

文章目录
分享的内容主要包括三个内容:
1)Kyuubi是什么?介绍Kyuubi的核心功能以及Kyuubi在各个使用场景中的解决方案;
2)Kyuubi在网易内部的定位、角色和实际使用场景;
3)通过案例分享Kyuubi在实际过程中如何起到作用。
Kyuubi是什么
开源Kyuubi是网易秉持开源理念的作品。Kyuubi是网易第一款贡献给Apache并进入孵化的开源项目。Kyuubi主要应用在大数据领域场景,包括大数据离线计算、数据仓库、Ad Hoc等方向。通过Kyuubi进入Apache的自我描述,可以知道Kyuubi是一个分布式、支持多用户、兼容DBC或ODBC的大数据处理服务。Kyuubi采用了Apache Spark作为计算引擎,并带来了很好的性能收益。Kyuubi未来也可能会支持其他的类似执行引擎,比如:Apache Flink。Kyuubi在2018年由网易开源到Github, 2021年成功进入Apache进行孵化,现在是处于孵化阶段。
1.1关键字
•开源:开源把整个项目带到了社区,在社区中的其它公司或技术开发人员,也会为Kyuubi带来新颖的想法,从而使Kyuubi可以发展得越来越好;
•多租户:作为一款企业级服务,多租户是不可缺少的功能,同时需要保证数据的安全性;
•兼容Hive JDBC:Hive是各大公司主流、常用的大数据处理引擎。兼容Hive JDBC可以很轻易帮助Hive用户无缝迁移到Kyuubi;
•Spark计算引擎:目前业界公认的、性能最好的、最流行的大数据计算引擎。因此Kyuubi的第一款内置计算引擎也选用Spark计算引擎;
大规模数据处理能力:需求分成两种情况:
•第一种情况是数据量的规模。比如:SQL查询,可能需要处理的数据量是GB或者TB级别的庞大规模,这就需要大规模数据处理能力来处理这种规模的数据;
•第二种情况是并发查询的规模。当任务非常多,每天会有几万个或者几十万个SQL查询任务在Kyuubi 上运行时,就需要有一个足够强大的处理能力,保证服务端可以及时响应用户的请求。
开箱即用:Kyuubi的务实、亲民设计理念,追求让用户以最低的成本、获取最好的效果。
1.2主流查询引擎对比
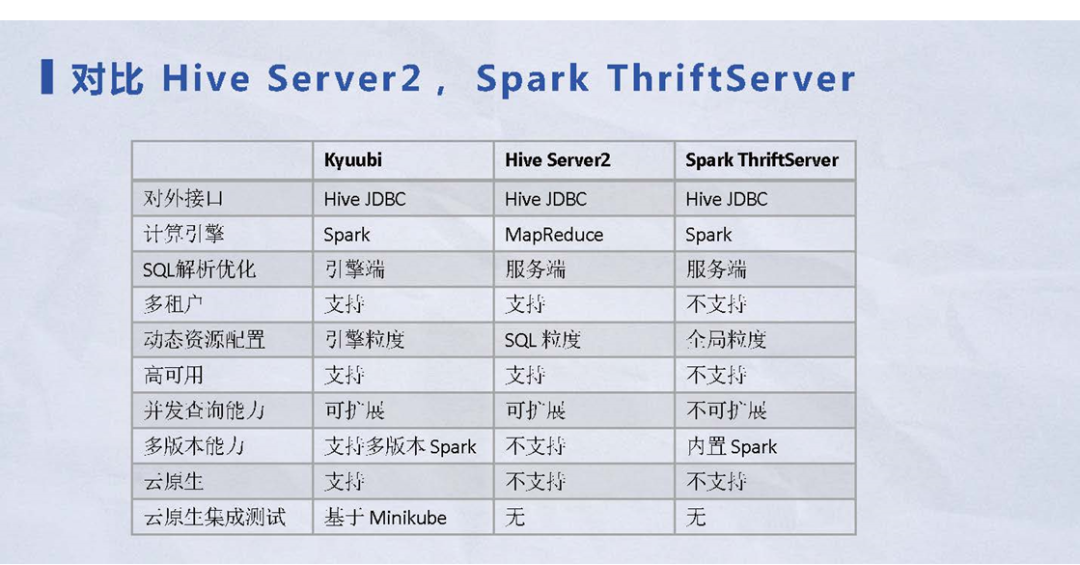
图 3 1.2主流查询引擎一览表
与目前主流的SQL大数据计算引擎进行对比,Kyuubi有着自己独特的优势:
•对外接口:都是基于Hive JDBC,如果使用Hive Server2迁移到Kyuubi时,整个切换是无缝、自然的使用Kyuubi;
•计算引擎:由计算引擎相关经验可以知道,Hive Server2基于MapRedeuce;Spark Thrift Server基于Spark,Kyuubi同样采用Spark计算引擎;
•多版本能力:Kyuubi在Spark基础上,具备提供多版本Spark的能力。在历史的迭代或产品的升级中,都会存在历史版本在测试和生产环境中,因此支持多版本的能力也非常重要;
•SQL解析优化:简单看就是毫秒级别或者是秒级别的优势,其实还有很多映射关系。比如Spark查一张表,需要Hive的全局锁,或者需要Hive全局锁控制整个的请求过程。在这个基础上,如果有多个用户同时去查询,可能会出现阻塞或者单点瓶颈的问题。Kyuubi可以把整个流程下推到引擎上,保证服务端可以及时的、快速的响应用户的请求,并且可以保持用户之间的引擎完全隔离;
•多租户:是企业级应用系统的基本功能,Kyuubi同时支持并保证多租户的数据安全性;
•动态资源配置:Hive的SQL基于MapReduce;Spark Thrift Server的资源配置并不是很灵活,原因在于Spark是全局单实例的方式,无论用户多少,都只能拥有一套资源配置场景。而Kyuubi提供了基于引擎粒度的资源配置,帮助用户实现任务间的快速隔离;
•高可用:是企业级SQL引擎的基本特性。Spark Thrift Server不具备这种能力;而Kyuubi提供了基于ZooKeeper的高可用解决方案,以支持高可用特性;
•并发查询能力:Kyuubi在基于高可用特性的基础上,可以轻松的在服务端进行横向的水平扩展,以保证并发查询能力,而Spark Thrift Server不支持并发查询特性;
•云原生:是近几年比较热门的话题,它可以帮助用户把整个集群进行混合部署,节省用户的资源使用。Kyuubi也同样支持以上云原生场景;
•云原生集成测试:在云原生的基础上,Kyuubi提供了与云原生相关的集成测试。Kyuubi是基于Minikube组件实现集成测试,这一环节在很多主流的技术组件中被忽视。通过完整的集成测试流程和高测试覆盖率,可以极大的降低用户在工作环境中出现bug的可能性。
1.3 Kyuubi的架构
Kyuubi的架构请看下面的具体的架构图。从左到右整张架构图可以分成三个部分:
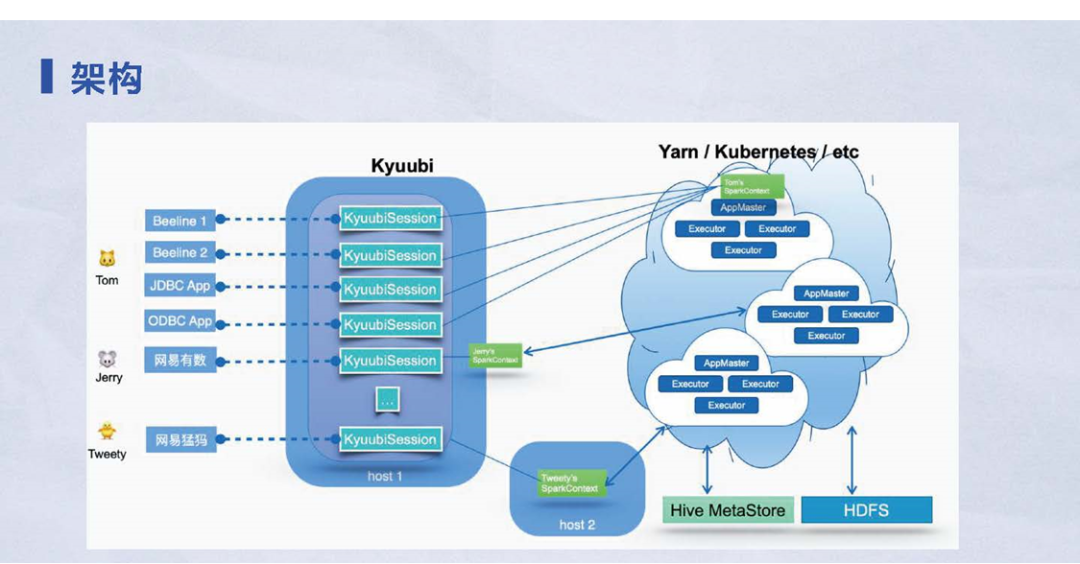
图 4 kyuubi的架构示意图
1) 客户端:是用户可以接触到的部分。比如:Hive Beeline、JDBC或ODBC接口,在内部,网易有数也是以客户端的角色连接到 Kyuubi;
2) Kyuubi服务端:通过和客户端建立一些会话(KyuubiSession),会话最终被路由到实际的执行引擎。
3) 实际执行引擎:会话路由的过程比较灵活,甚至可以由用户自定义。在这张架构图展现的案例就是用户A用户B共享引擎,即使用了同一个引擎;而用户C用了另一个引擎。在这个场景下,用户的整个引擎资源实现了隔离,并且引擎之间也可以部署在不同级资源管理集群,比如:支持Spark On Yarn或者Spark On Kubernetes。在这种很灵活的配置环境下,用户可以轻松的、让自己的任务跑在任意集群。这些都是Kyuubi架构的优势。
Kyuubi在网易的应用
Kyuubi在网易的应用包括两方面:
1) 用户画像:有哪些人、哪些团队使用Kyuubi大数据引擎组件;
2) 业务场景:Kyuubi的使用场景和业务场景,以及对应不同业务场景的解决方案。
1.1 用户画像
Kyuubi使用者可以分成三个大类:

图5 Kyuubi 用户画像
1) 数仓团队:数仓团队又细分成三种:
•传统数仓团队,使用MySql或Oracle做数据分析,没有大数据、大数据引擎的处理能力,不知道SQL查询在计算引擎上的整个执行过程,只知道数据的结果;
•有一些Hive或者Spark的使用经验,部分了解配置优化;
•关注性能和成本,不接受任务跑得很快,但占用很多资源的情况。
2) BI团队:专注于面向业务开发,工作时间相对集中在工作日的白天,对成本不敏感,更关注 SQL 查询的执行性能;
3) Spark团队:Kyuubi重度使用者。Spark团队有三个方面的任务:
•日常管理Spark版本。不同于社区,网易内部有很多Spark分支,每个月或者定期会发布修复Bug的Spark版本、或增加新功能;
•进行插件管理。由于Spark插件多种多样,比如:SQL的插件可以优化SQL;权限控制插件,帮助用户做数据脱敏加密;
•完成配置管理。当客户端分布在各个节点的时候,维护配置比较困难;而Kyuubi面对这样的场景,可以统一在服务端实现维护,整个过程很简捷。
1.2 业务场景
在Kyuubi的使用过程可以分成四个大类:
1) 海量任务;
2) 复杂环境;
3) 复杂任务;
4) 多入口。

图 6业务场景一览
2.2.1 海量任务
由于网易内部的团队和业务部门很多,Kyuubi的任务数量也非常多,每天有几万或几十万个SQL任务,高峰期每秒钟都会有很多Kyuubi请求任务。
2.2.2 复杂任务
任务复杂程度也需要考虑,由于Kyuubi的用户人群很多,如上所述有:数仓、BI或者其他的开发人员,其任务的复杂度也各不相同。比如:数仓任务如果是细数据,需要做简单的清洗类似ETL类型,属于IO密集型任务;如果是一个轻量聚合或者汇总层的任务,整个过程比较简捷,属于CPU密集型任务。这些场景在Kyuubi上的任务是非常复杂的。
2.2.3 复杂环境
•多集群混合管理能力
由于支持On Yarn或者On Kubernetes,有些用户需求出于稳定性或成本的考虑,提出Query的部分SQL分别跑在On Yarn或On Kubernetes上,Kyuubi具备支撑这种多集群混合管理的能力。
•多版本能力
能够管理多个Spark版本,以及Spark依赖不同版本的Hive,整个环境非常复杂。
2.2.4 多入口
由于网易有数的很多产品线接入了Kyuubi,比如:BI或者AI的平台;网易在做的自助分析和离线开发的SQL任务,也已经接入了Kyuubi。Kyuubi需要控制和维护这么多入口,有相当的压力。
下面分别分析不同场景下Kyuubi的实际解决方案和使用经验。
1.3 业务场景 – 数据仓库
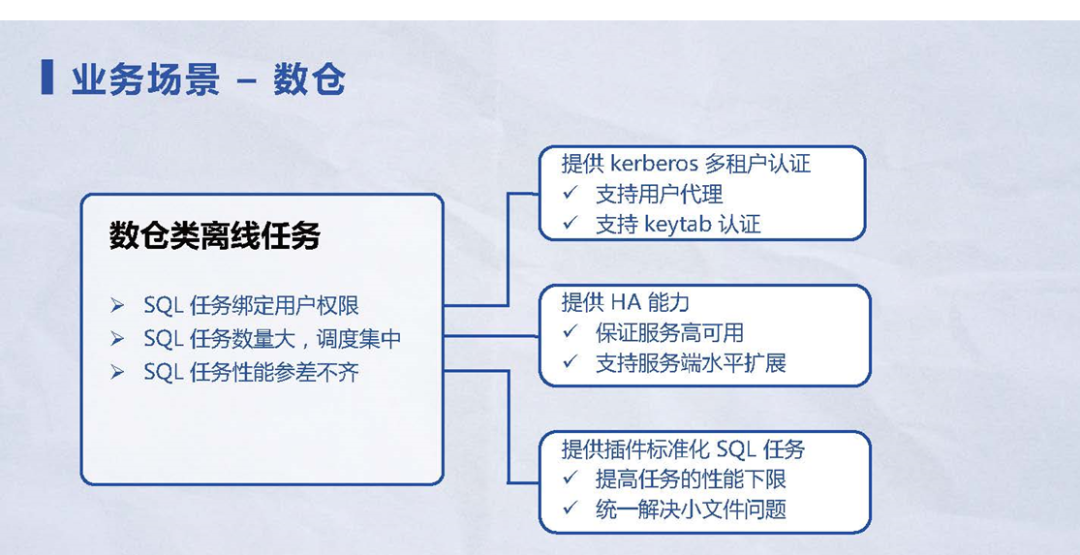
图 7数据仓库业务场景
在数仓类离线任务的使用场景下,有三个核心痛点:
1) SQL任务绑定用户权限。就是需要数据隔离或数据读写的安全性以保证数据的安全。
在这个背景下,Kyuubi支持kerberos多租户的认证,同时支持:
•用户代理模式;
•keytab的认证方式,通过灵活的配置就可以满足用户在不同业务场景下的需求叠加。
2) SQL任务数量大,调度集中。比如数仓任务大部分都在凌晨一两点的时候任务提交启动。在这个场景下,Kyuubi提供:
•HA能力,保证服务的高用性和SLA指标;
•提供服务端水平扩展,业务线可以部署两台或以上Kyuubi服务,保证每个Kyuubi负载均匀,确保能够快速响应用户的请求。
3) 性能参差不齐。考虑到历史任务不可能把每个任务都已经跑到目标性能,有些任务连一些常见Spark配置都没有改,或者SQL本身也不规范。在这个事实基础上,Kyuubi提供了标准化SQL插件、来标准化SQL任务。由于SQL脚本数量非常巨大,成千上万的又不可能让用户逐个去修改,标准化SQL任务的方式就会非常有效果。
Kyuubi提供了集中式SQL任务的标准化,其中最核心的两个功能是:
•提高任务的性能下限,任务性能再差,也比上Kyuubi之前的性能要好;
•统一解决小文件问题。小文件问题是一个老生常谈的问题,不同的公司会有不同的解决方案。Kyuubi提供的统一解小文件问题方案,可以极大减轻整个集群的存储压力,保证了每个任务的瓶颈产生文件都是期望大小,比如200MB以上。
1.4 业务场景 – Ad hoc
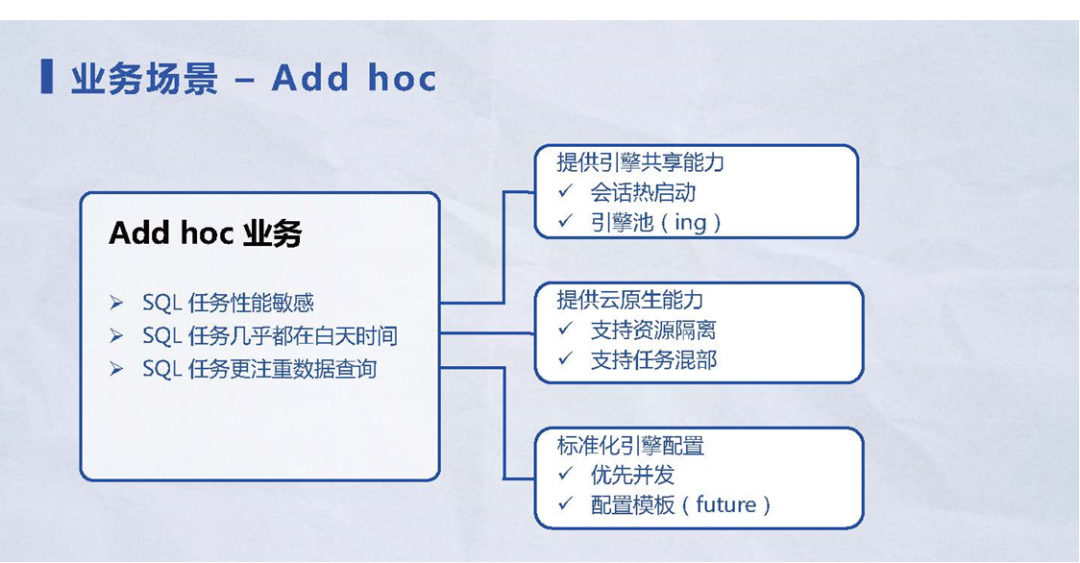
图 8 Ad hoc业务场景
Ad hoc业务场景是BI团队会遇到的场景,Ad hoc场景中遇到的痛点和方案如下:
1) SQL任务性能敏感。快速响应的任务,以秒为单位进行计时,如果超过指定时长,就会直接放弃这个任务结果。在这种需求下,Kyuubi提供了引擎共享能力:
•会话热启动:当用户创建会话时,Kyuubi的计算指令引擎已经处于活跃状态,比如:和 Hive Metastore 的连接已经连接成功,整个的Spark机制都已经运转起来,无需再处理这些过程。整个Query会非常快,极大减轻了整个SQL启动时间。比如:SQL本身执行需要十几秒,整个任务的起效时间大概需要十秒,甚至由于资源管理器不一样、或者Kubernetes出现资源挑战,都可能需要几十秒的时间,整个过程非常缓慢。Kyuubi提供的会话热启动的能力,相当于把每一个SQL Query的查询时间提升50%或者100%,使得性能有明显的提升。
•引擎池:目前在Kyuubi社区还在讨论如何进一步开发。核心目标就是为了解决:当某些用户的SQL吞吐量非常大,单个引擎实力满足不了需求时,需要多个引擎同时在线提供服务。在这种场景下,Kyuubi通过引擎池,配套负载均衡或者类似Round-Robin这种随机引擎选择策略,用户就可以优雅地增加查询能力。
2) SQL任务几乎都在白天跑。常见的SQL任务的工作时间是九点到下午十七点,在这段时间使用频率很高;在晚上整个集群就基本上都处于闲置状态。Kyuubi在这个场景下可以支持云原生能力,帮助用户把Ad hoc任务或者Ad hoc的Kyuubi集群、以及背后的引擎资源,全部可以部署到Kubernetes上,让整个处于闲置状态下的资源充分利用起来,避免出现浪费,从而降低用户的资源成本。
3) SQL任务更加注重数据查询。数据查询相对于数据写入场景的场景来说,SQL Query的结果数量可能很少,只有几条或十几条数据肉眼可见的数据规模。在这种场景下,可以把整个计算引擎的配置都标准化为优先并发的配置,即不考虑小文件问题。此时不存在小文件,就可以把整个分区或者分区处理的文件大小,控制在诸如32兆或者16兆更小的数据规模,从而保证整个SQL Query的高性能。此外还提供了配置模板的特性方案,主要功能是把整个SQL任务进行分类。比如:数据查询是一大类,这个粒度比较粗,后面将针对用户的任务,定义更细粒度的类型,并给出相应的配置模板。在不同配置模板下,就可以发挥出计算引擎强大的性能。比如:发挥Spark计算引擎的强大性能,从而帮助提升用户的查询效率,加快查询速度。
1.5 业务场景 – 内部系统
在业务场景中会有难以描述的内部系统,具体也不清楚该系统是用来做什么业务,或者有那些隐藏在背后的用户。针对这样的内部系统业务场景,其解决方案如下:
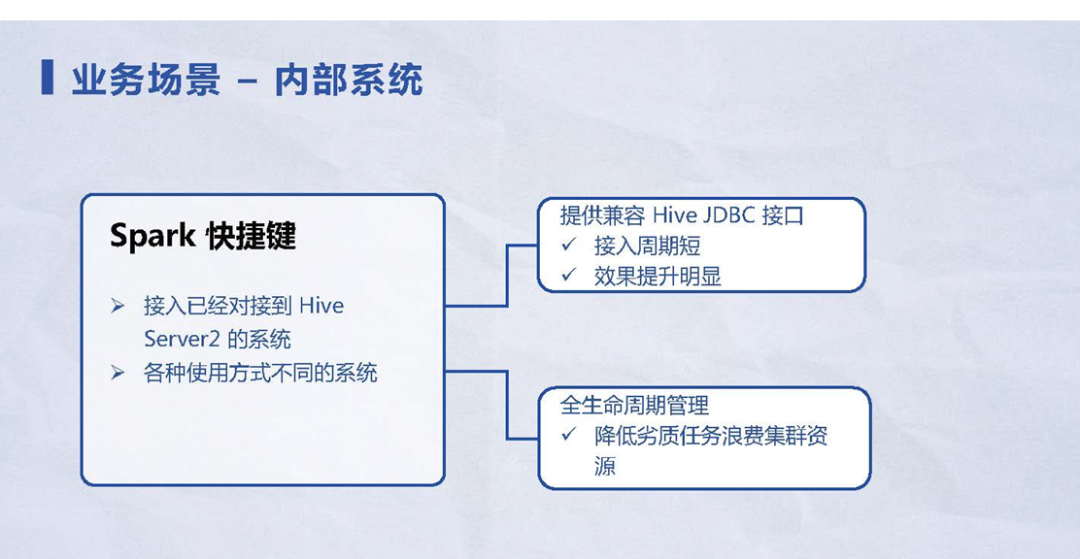
图9内部系统业务场景
1) 由于接入Kyuubi的门槛很低,用户通过JDBC或者Hive Beeline就可以轻松接入Kyuubi,整个过程是很轻量级。对于已经接入Hive Server2的系统,Kyuubi完全兼容Hive的接口,用户任务的迁移周期非常短。对于开发者来说,Kyuubi把背后的引擎优化成Spark,提供了缓存、插件等,仅仅改一两行代码就可以带来很大的收益,可以让用户得到更好的性能效果。
2) 对于意料之外接入的系统,Kyuubi提供了整套全生命周期管理的配套措施。不管用户创建了会话、通过会话创建的引擎实例,还是在引擎实例跑的SQL任务,Kyuubi对于各个层级、各个粒度资源,都做了生命管控。
例如:一个引擎实例已经闲置了十分钟,Kyuubi就会主动释放引擎资源,而不会再浪费整个集群资源。通过这种方式可以降低历史任务、或意料之外的任务浪费集群资源,保证集群的稳定性。
案例分析
以上讲述了Kyuubi在网易内部的一些使用场景和相应的解决方案。最后分享一个具体案例,让大家感受如何实际使用Kyuubi,以及Kyuubi发挥的价值。
2.1 案例痛点1:
1) 案例背景和矛盾:有用户的任务跑在Hive On Yarn的场景,用户想优化整个任务、或改Spark跑、或改到Kubernetes上做任务。

图 10 Hive On Yarn优化案例
2) 整个案例的痛点:Hive任务的自身优化空间比较小,加了几个或十几个配置之后,还没有达到用户的预期,用户就切换背后的执行引擎到Spark。由于任务的整个执行时间上的规律、或执行时间分散,用户想用Kubernetes进一步的降低成本。在推出Spark 3.0之后,推出了基于AQE的、基于运行中的数据计算信息、优化每一个Stage的功能。用户想用该功能,但是如果直接切到 Spark,整个过程非常通过。而采用Kyuubi将会让整个迁移过程变得更加平滑
2.2 案例痛点2:
1) 案例背景和矛盾:由于历史原因,每个公司或者每个团队都有整个任务的调度体系。

图 11古老脚本的迁移案例
2) 整个案例的痛点:对于这个案例,之前的SQL脚本大家都保存在shell脚本里面,再通过一些Hive执行SQL脚本,整个过程都是非常原始,没有统一的管理系统。对于外部系统想接入或者想做更新和优化非常困难。
对于这个迁移性项目,给用户带来的收益可以看成是三部分内容:
•迁移旧系统的代价;
•旧系统的代价减去新系统的代价;
•再减去迁移成本,这才是用户最终得到的收益。
如果降低了用户的迁移成本,保留了用户的使用习惯之后,给用户带来的收益也是增加的。并且在用户的旧任务迁移完成之后,用户新任务的开发也有很大收益。因此 Kyuubi 选择保留用户的使用习惯。
2.3 案例痛点3:
1) 案例背景和矛盾:迁移周期和迁移效果的矛盾。

图 12迁移周期与经营效果案例
2) 整个案例的痛点:整个迁移数据的SQL任务数会很多,比如:2000多的任务,每个任务也非常复杂;想要达到的效果目标很高,比如:每个任务平均性能提升40%,也就是之前100秒跑完的任务,现在想要40秒就能跑完,资源节省30%。这样资源和性能是两个矛盾点。
当资源充足的情况下,性能自然就能提升;但资源和性能都要提升,这在一定条件下是非常困难的。
2.4 案例痛点的解决方案:
根据前面Kyuubi的特性,Kyuubi针对以上三个痛点提出了解决方案:

图 13 案例痛点的解决方案
1) 完全兼容Hive JDBC接口。用户只需要改beeline的JDBC连接串就可以非常轻量、无缝的、平滑的切换到Kyuubi。在切换到Kyuubi之后,不管背后是Spark On Yarn或者Spark On Kubernetes,用户都无需关心整个运行集群或运营配置。只要跑在Kyuubi上,剩下工作的交给Kyuubi就可以。整个迁移的流程非常平滑,对用户也非常简单。
2) Kyuubi提供了AQE的线下增强插件。在Spark社区分支的基础上,Kyuubi提供了增强版AQE。同时Kyuubi项目组也向Spark社区提交了大约20多个AQE的补丁,对Spark进行了优化。
增强插件的核心需求有两个:
•小文件合并。把每一个SQL任务,标准化成带小文件合并的SQL任务,这样就让用户的每个SQL任务、产出的文件数保持一定规模。比如:每个任务产出平均文件的大小都是200或500多兆,可以对齐HDFS 的 Block 大小,或者对齐更大的文件需求。
•基于Stage的配置隔离。Stage是Spark的一个概念,Spark对于每个shuffle切割Stage,Stage粒度的配置隔离,意味着可以对shuffle进行优化,向用户提供更多优化的可能性,同时提高了任务的优化上限。
3) 支持混部集群。Kyuubi本身支持Spark On Yarn 和Spark On k8s两种Spark调度模式。用户迁移到了Kyuubi之后,无需再二次迁移。用户可以自由选择Spark任务执行的集群环境,比如任务a跑到yarn集群,任务b跑到kubernetes集群。整个切换非常丝滑,只需要修改一些配置。
这些都是对于案例痛点提出的解决方案。
2.5 案例发展史
下图是Kyuubi项目的整个发展时间线或者进度条。
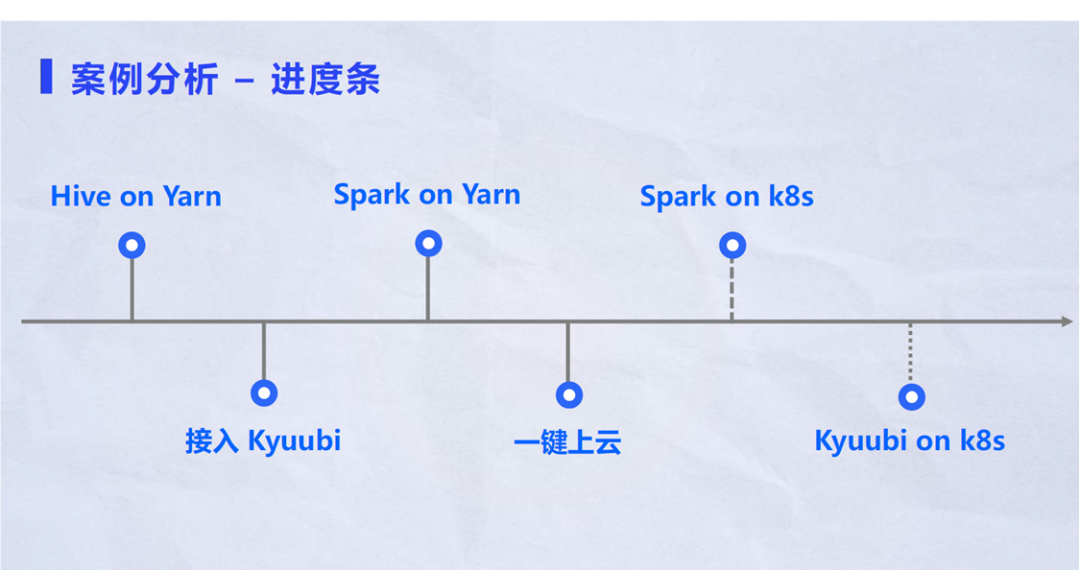
图 14 Kyuubi项目发展史
从上图可以看到整个案例的发展史,按照时间进度可以分为三个阶段:
1) 第一阶段:迁移原本跑在 Hive 上的 beeline 脚本到kyuubi。接下来只需在Kyuubi层面完成工作,整个过程虽然非常复杂,但是不会影响到用户脚本里的代码,从而减少迁移人员的工作量,要知道改历史代码是每个公司最不想面对的事情。
2) 第二阶段:Spark On Yarn阶段。迁移的首要目标是考虑稳定性,Kyuubi具有很高的SLA保证率。由于Spark On k8s技术对于Spark并不是特别成熟,而On Yarn已经存在了5~6年或者更长的时间,整个构架和体系都是经过考验,用户会把关键性任务迁移到Spark On Yarn环境。在此基础上才会考虑进一步压缩成本。比如:把一些非关键性或者有周期性的任务跑在k8s上。
3) 第三阶段:接入Kyuubi之后一键上云。比如:用户在第二次迁移到k8s的时候,就不需要再走一遍之前的过程,只需加一个配置去选择需要的k8s环境,整个过程是非常简单。
在支持k8s之前,Kyuubi已基于minikube做集成测试,之后会继续增加测试的覆盖率,包括增加TPCDS在k8s环境的测试。Kyuubi On k8s可以进一步展示Kyuubi服务端所占用资源的情况,可以帮助用户更加灵活、更加弹性的部署Kyuubi。
2.6 案例成果分析
下面讲一个迁移项目带来收益的案例。

图 15项目迁移到Kyuubi收益案例
这个项目大概持续了3个多月,时间不算长。目前大部分任务都已经迁移到了k8s环境上,整个任务规模数量在2000任务,整体大概有70%的性能提升,就是之前用100秒跑的任务,现在任务只要跑30秒,个别任务可能更夸张。因为这个性能提升70%是平均的性能提升。
最后一点是资源节省,也是用户非常关心的特点。在性能提升70%的同时,通过控制CPU和内存的资源成本线,整个资源可以节省50%,可帮助用户获得更多的成果。
本次分享到此结束。
答疑
问题1:大家熟悉的Spark计算框架在运行Spark任务时,对小文件控制的不好。Kyuubi自带小文件问题解决方案,在运行任务的过程中,会对小文件进行合并。请具体讲一下Kyuubi采取了如何实现小文件的合并?
答:小文件合并是Spark的老大难的问题。从Spark流行开始一直有小文件问题,而且Spark可以非常轻易的产生小文件。比如:在动态分析插入的场景中,小文件的产生量用指数级的爆炸来描述也不过分。
1) Kyuubi对于动态场景做了一个小文件自动合并的方案,这个方案解决两个问题:一个问题是静态分区插入,另一个是动态分区插入。对于静态分区插入,整个过程比较简单,直接在最后的stage后面,追加一个额外的Shuffle stage。
2) 上面也提到过Kyuubi的插件、还有另外的一些功能,比如:stage粒度的配置隔离。在配置隔离的基础上,新增的Shuffle就可以灵活地控制每个分区的处理能力(处理的数据量)。比如:每个分区可以处理200或者500多兆的数据量,这个数据量和最终产生的文件大小是相关的。如果增加配置或增加了某个分区的数据处理量,也就增加了产生的最终文件的大小。
3) 另一个解决方案是动态分区插入,稍微复杂一点。它的分区是在计算完成之后,才会感知到想生成哪些分区、在哪些分区上产生了哪些文件。Kyuubi对于这样的场景,额外增加一个对于分区字段的Shuffle,也就是先对分析字段做Hash,然后把相同分区值分布到同一部分之内,从而保证不会过多。
4) 在这个基础上,Kyuubi提供了一些额外的配置,比如:动态分区会产生数据倾斜的隐患。Kyuubi提供一些配置缓解这样的问题。比如:每一个分区可以指定产生的文件数,来解决数据信息的问题。另外 Kyuubi 社区的一些技术同学也积极给Spark社区提新的特性-rebalance。所以在Spark3.2.0之后会有新的解决方法,带给我们更优秀的小文件合并能力。
问题2:在Kyuubi使用过程中,涉及到脚本外部传参, Kyuubi后续规划里面有没有针对脚本传参的规划。
答:脚本传参的场景,第一个是参数, Spark的参数有静态和动态。静态的参数是非SQL类参数,比如:资源配置,内存、CPU之类的配置是静态的,不允许在使用过程中动态修改。动态的参数是可以动态修改。比如:SQL的配置、Shuffle的分区数。对于静态的配置,在Kyuubi端也是无法修改,因为Kyuubi和Spark是一样流程。
对于这部分内容,Kyuubi之后可能会提供更细粒度的引擎实现,做到动态的、资源修改的解决方案,可以对比当前的引擎实例和期望的引擎实例的资源配置;如果不满足可以做一些其他判断。比如:创建一个额外的引擎、或替换当前的引擎都有可能。不过目前来说这些都还只是设想,没有实际的方案。如果你有一些其他想法或思路,也可以来社区提出更明细的问题,可能跟开发聊这些事情会更方便,然后可以讨论出更好的解决方案。
问题3:HUE能跟Kyuubi集成吗?
答:可以。Kyuubi的官方文档就提供了HUE的quick start,这些文档可以教你如何一步一步的把HUE接入到Kyuubi。
问题4:高并发下Kyuubi的Server端压力大不大?
答:确实会有压力,但这个压力和整个的调度模式有关,比如:用Spark On Client模式去调度, Server端的压力就会自然增长,原因是Spark Driver进程会一直跑在Server端。如果用其他的调度模式Server端的压力会降低。
问题5:负载均衡池如何做到负载均衡?
答:负载均衡池是依赖于Hive Client,基于Zookeeper可以获取Kyuubi的所有实例,然后进行随机选取,然后做到负载均衡。
之后会推进Kyuubi自己的Client,在这个基础上,就可以更加灵活的控制、如何选择更合适的Kyuubi Server。
目前还是依赖于Hive Client端的负载均衡方式。
问题6:请简单总结一下Kyuubi在性能优化的方式。
答:性能优化很宽泛,需要通过一系列的手段影响产生性能优化的结果。比较大的影响因素包括:Kyuubi提供了一个会话缓存或者说引擎快速启动特性,帮助用户最大可能减少在引擎启动的调度耗时;资源释放或者资源申请的时间;提供插件,比如:提供了Spark插件,带来SQL层面上的优化。
问题7:Kyuubi从架构上跟Hive Server2的架构基本完全一致。从语法层面Hive SQL的语法能与Spark SQL的语法完全能兼容吗?有没有细节方面之类的差异?
答:肯定会有,因为Hive SQL有很多自己的方言;Spark SQL对应的也有自己的方言。在大部分场景或者99%的case基本上都是兼容的。
Kyuubi在迁移的过程中,也遇到过不兼容的场景。Hive SQL的一些语法,在Spark SQL得不到承认。这些是一些比较细微的、或者跟性能没有关系的一些语法。只要能把整个Query语法解释一遍,或者说分析一遍就可以了。这个过程是非常快的。
问题8:关于Kyuubi生产部署环境的案例。
答:Kyuubi在整个网易内部的很多Spark查询已经很广泛,整个Kyuubi项目在网易有数对外的商业化版本里面。整个Kyuubi的生产环境有很多,商业化项目也有好几百个,也都会默认带上Kyuubi。
网易内部是一个很重要场景,每天有几十万的任务量,在内部、外部都有很好的落地的应用。可以关注Kyuubi公众号和微信群进行更多的交流。
问题9:Kyuubi和Spark SQL有什么区别?
答:Kyuubi使用了Spark SQL作为底层的执行引擎。横向的对比对象是Spark Thrift Server。对比SQL引擎管理、整个数据链路、或者整个查询生命周期的维护,Kyuubi会提供更多诸如:HA、缓存、插件机制,这些Spark SQL都是不支持的。Kyuubi是强依赖于Spark SQL的性能,Kyuubi的计算引擎还是Spark SQL。
这两个内容不在同一层面上,难以进行对比。Kyuubi是在Spark SQL的上面做了很多诸如:隔离等工作,而SparkSQL本身是不涉及这些内容的。
分享嘉宾:尤夕多 网易资深大数据开发工程师,目前就职于网易数帆有数产品线,专注于开源大数据领域,Apache Kyuubi (Incubating) Committer & PPMC / Apache Spark Contributor。
编辑整理:曾新宇 对外经贸大学
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Kyuubi在网易的深度实践】(https://www.iteblog.com/archives/10114.html)
