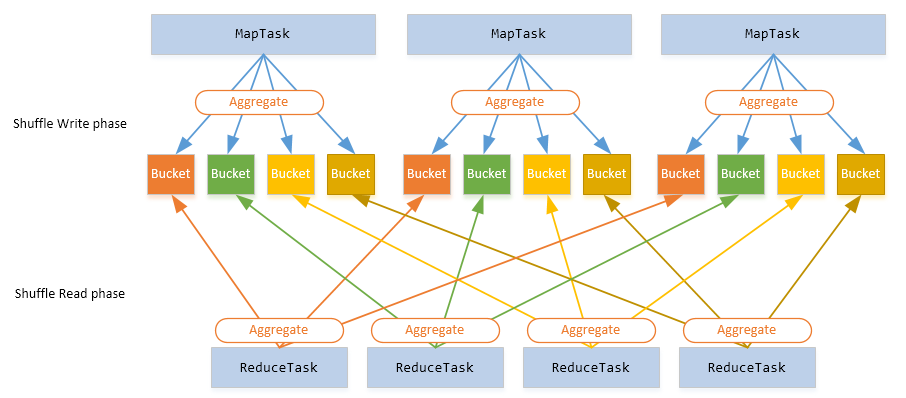
Spark Shuffle 基础在 MapReduce 框架中,Shuffle 是连接 Map 和 Reduce 之间的桥梁,Reduce 要读取到 Map 的输出必须要经过 Shuffle 这个环节;而 Reduce 和 Map 过程通常不在一台节点,这意味着 Shuffle 阶段通常需要跨网络以及一些磁盘的读写操作,因此 Shuffle 的性能高低直接影响了整个程序的性能和吞吐量。与 MapReduce 计算框架一样,Spark 作 w397090770 7年前 (2017-11-15) 7519℃ 3评论30喜欢
在使用 Apache Spark 的时候,作业会以分布式的方式在不同的节点上运行;特别是当集群的规模很大时,集群的节点出现各种问题是很常见的,比如某个磁盘出现问题等。我们都知道 Apache Spark 是一个高性能、容错的分布式计算框架,一旦它知道某个计算所在的机器出现问题(比如磁盘故障),它会依据之前生成的 lineage 重新调度这个 w397090770 7年前 (2017-11-13) 10556℃ 0评论24喜欢
本文总结了几个本人在使用 Carbondata 的时候遇到的几个问题及其解决办法。这里使用的环境是:Spark 2.1.0、Carbondata 1.2.0。必须指定 HDFS nameservices在初始化 CarbonSession 的时候,如果不指定 HDFS nameservices,在数据导入是没啥问题的;但是数据查询会出现相关数据找不到问题:[code lang="scala"]scala> val carbon = SparkSession.builder().temp w397090770 7年前 (2017-11-09) 6668℃ 5评论14喜欢
本书于2017-08由 Packt 出版,作者 Manish Kumar, Chanchal Singh,全书269页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Learn the basics of Apache Kafka from scratchUse the basic building blocks of a streaming applicationDesign effective streaming applications with Kafka using Spark, Storm &, and HeronUnderstand the i zz~~ 7年前 (2017-11-08) 6669℃ 0评论31喜欢
Kafka 从首次发布之日起,已经走过了七个年头。从最开始的大规模消息系统,发展成为功能完善的分布式流式处理平台,用于发布和订阅、存储及实时地处理大规模流数据。来自世界各地的数千家公司在使用 Kafka,包括三分之一的 500 强公司。Kafka 以稳健的步伐向前迈进,首先加入了复制功能和无边界的键值数据存储,接着推出了用 w397090770 7年前 (2017-11-05) 25816℃ 0评论17喜欢
Spark Summit 2017 Europe 于2017-10-24 至 26在柏林进行,本次会议议题超过了70多个,会议的全部日程请参见:https://spark-summit.org/eu-2017/schedule/。本次议题主要包括:开发、研究、机器学习、流计算等领域。从这次会议可以看出,当前 Spark 发展两大方向:深度学习(Deep Learning)提升流系统的性能( Streaming Performance)如果想及时了解Spar w397090770 7年前 (2017-11-02) 3553℃ 0评论13喜欢



![[电子书]Building Data Streaming Applications with Apache Kafka PDF下载](https://www.iteblog.com/pic/books/building-data-streaming-applications-apache-kafka-iteblog.png)
![Spark Summit 2017 Europe全部PPT及视频下载[共69个]](https://www.iteblog.com/pic/spark/spark-summit-2017-europe-iteblog.png)