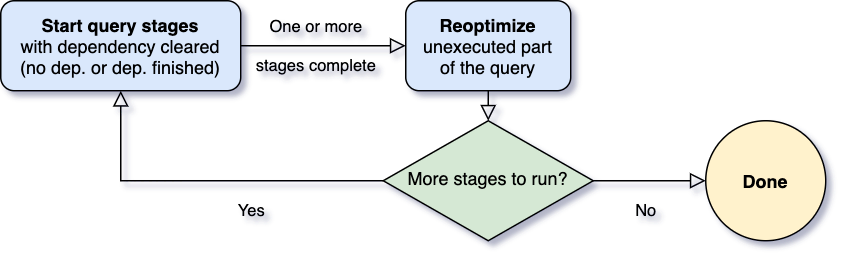
多年以来,社区一直在努力改进 Spark SQL 的查询优化器和规划器,以生成高质量的查询执行计划。最大的改进之一是基于成本的优化(CBO,cost-based optimization)框架,该框架收集并利用各种数据统计信息(如行数,不同值的数量,NULL 值,最大/最小值等)来帮助 Spark 选择更好的计划。这些基于成本的优化技术很好的例子就是选择正确 w397090770 5年前 (2020-05-30) 1766℃ 0评论4喜欢
Pandas 用户定义函数(UDF)是 Apache Spark 中用于数据科学的最重要的增强之一,它们带来了许多好处,比如使用户能够使用 Pandas API和提高性能。 但是,随着时间的推移,Pandas UDFs 已经有了一些新的发展,这导致了一些不一致性,并在用户之间造成了混乱。即将推出的 Apache Spark 3.0 完整版将为 Pandas UDF 引入一个新接口,该接口利用 w397090770 5年前 (2020-05-30) 970℃ 0评论1喜欢
Hadoop 社区推出了新一代分布式Key-value对象存储系统 Ozone,同时提供对象和文件访问的接口,从构架上解决了长久以来困扰HDFS的小文件问题。本文作为Ozone系列文章的第一篇,抛个砖,介绍Ozone的产生背景,主要架构和功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop背景HDFS是业界默认的 w397090770 5年前 (2020-05-26) 1944℃ 1评论1喜欢
美国当地时间2020年05月11日,Apache Hudi 项目的共同创始人、PMC Vinoth Chandar 给社区发了一封标题为 [DISCUSS] Graduate Apache Hudi (Incubating) as a TLP 的邮件,来投票讨论 Apache Hudi 毕业成为 Apache TLP 项目。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop2020年05月19日共40人投票赞成 。不久社区给 Apache 董事 w397090770 5年前 (2020-05-22) 1204℃ 0评论1喜欢
数据湖分析Data Lake Analytics是阿里云数据库自研的云原生数据湖分析系统,目前已有数千企业在使用,是阿里云 库、仓、湖战略高地之一 !!!现紧急招聘【 数据湖平台工程师】 产品链接:https://www.aliyun.com/product/datalakeanalytics !!!如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop团队内部拥有多 w397090770 5年前 (2020-05-22) 933℃ 0评论1喜欢
我们是负责58同城商业广告变现的商业工程技术团队,负责竞价排名类广告系统研发,包含广告投放系统,广告检索系统,以及广告投放策略的研究、实现。在这里,你将面临严密的商业逻辑的挑战,高并发、大数据量的挑战,如何认知数据、应用数据的挑战。高级大数据研发工程师 工作职责:负责或参与58商业数据仓库 w397090770 5年前 (2020-05-21) 1374℃ 0评论8喜欢
目前,Apache Kafka 使用 Apache ZooKeeper 来存储它的元数据,比如分区的位置和主题的配置等数据就是存储在 ZooKeeper 集群中。在 2019 年社区提出了一个计划,以打破这种依赖关系,并将元数据管理引入 Kafka 本身。所以 Apache Kafka 为什么要移除 Zookeeper 的依赖?Zookeeper 有什么问题?实际上,问题不在于 ZooKeeper 本身,而在于外部元数据 w397090770 5年前 (2020-05-19) 1427℃ 0评论1喜欢
NVIDIA (辉达) 于2020年5月15日宣布将与开源社群携手合作,将端到端的 GPU 加速技术导入 Apache Spark 3.0。全球超过五十万名资料科学家使用 Apache Spark 3.0 分析引擎处理大数据资料。透过预计于今年春末正式发表的 Spark 3.0,资料科学家与机器学习工程师将能首次把革命性的 GPU 加速技术应用于 ETL (撷取、转换、载入) 资料处理作业负载 w397090770 5年前 (2020-05-15) 749℃ 0评论2喜欢
我们使用数据库可以快速访问业务数据,但是随着时间的推移,数据库会不断增长,提取信息所需的时间也会更长,数据操作成为瓶颈。这时候我们就需要对数据进行分区(partition)了。分区是将数据库或其组成元素划分为不同的独立部分。数据库分区通常是出于可管理性、性能或可用性或负载平衡的原因而进行的。在分布式数据 w397090770 5年前 (2020-05-14) 1093℃ 0评论2喜欢
物化视图作为一种预计算的优化方式,广泛应用于传统数据库中,如Oracle,MSSQL Server等。随着大数据技术的普及,各类数仓及查询引擎在业务中扮演着越来越重要的数据分析角色,而物化视图作为数据查询的加速器,将极大增强用户在数据分析工作中的使用体验。本文将基于 SparkSQL(2.4.4) + Hive (2.3.6), 介绍物化视图在SparkSQL中 w397090770 5年前 (2020-05-14) 2286℃ 0评论4喜欢