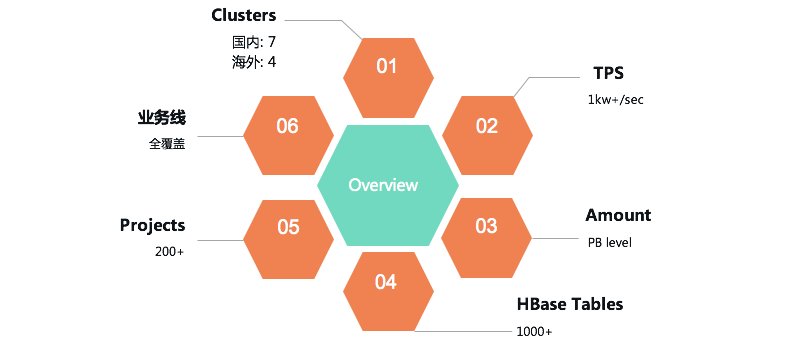
滴滴HBase团队日前完成了0.98版本 -> 1.4.8版本滚动升级,用户无感知。新版本为我们带来了丰富的新特性,在性能、稳定性与易用性方便也均有很大提升。我们将整个升级过程中面临的挑战、进行的思考以及解决的问题总结成文,希望对大家有所帮助。背景目前HBase服务在我司共有国内、海外共计11个集群,总吞吐超过1kw+/s,服务 w397090770 5年前 (2020-06-10) 1587℃ 0评论6喜欢
最近由于工作方面的原因需要解析 Apache Phoenix 底层的原始文件,也就是存在 HDFS 上的 HFile。但是由于 Phoenix 有自身的一套数据编码方式,但是由于本人对 Phoenix 这套根本就不熟悉,所以只能自己去看相关代码。但是 Apache Phoenix 是个大工程啊,不可能一个一个文件去找的,这会相当的慢。这时候我想到的是搭建一个 Phoenix 测试环境, w397090770 5年前 (2019-10-22) 3921℃ 0评论3喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12544℃ 0评论34喜欢
今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的拿出电脑,带上耳机,开始我一天的知识盘 w397090770 6年前 (2019-08-13) 5664℃ 2评论33喜欢
Apache Spark 和 Apache HBase 是两个使用比较广泛的大数据组件。很多场景需要使用 Spark 分析/查询 HBase 中的数据,而目前 Spark 内置是支持很多数据源的,其中就包括了 HBase,但是内置的读取数据源还是使用了 TableInputFormat 来读取 HBase 中的数据。这个 TableInputFormat 有一些缺点:一个 Task 里面只能启动一个 Scan 去 HBase 中读取数据;TableIn w397090770 6年前 (2019-04-02) 13140℃ 5评论18喜欢
前两篇文章,《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 和 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 分别介绍了两种方法读取加盐之后的 HBase 表。本文将介绍如何在 MapReduce 读取加盐之后的表。在 MapReduce 中也可以使用 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 文章里面的 SaltRangeTableInputForm w397090770 6年前 (2019-02-27) 2954℃ 0评论7喜欢
在 《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 文章中介绍了使用协处理器来查询加盐之后的表,本文将介绍第二种方法来实现相同的功能。我们知道,HBase 为我们提供了 hbase-mapreduce 工程包含了读取 HBase 表的 InputFormat、OutputFormat 等类。这个工程的描述如下:This module contains implementations of InputFormat, OutputFormat, Mapper w397090770 6年前 (2019-02-26) 3904℃ 0评论16喜欢
在 《HBase Rowkey 设计指南》 文章中,我们介绍了避免数据热点的三种比较常见方法:加盐 - Salting哈希 - Hashing反转 - Reversing其中在加盐(Salting)的方法里面是这么描述的:给 Rowkey 分配一个随机前缀以使得它和之前排序不同。但是在 Rowkey 前面加了随机前缀,那么我们怎么将这些数据读出来呢?我将分三篇文章来介绍如何 w397090770 6年前 (2019-02-24) 4728℃ 0评论11喜欢
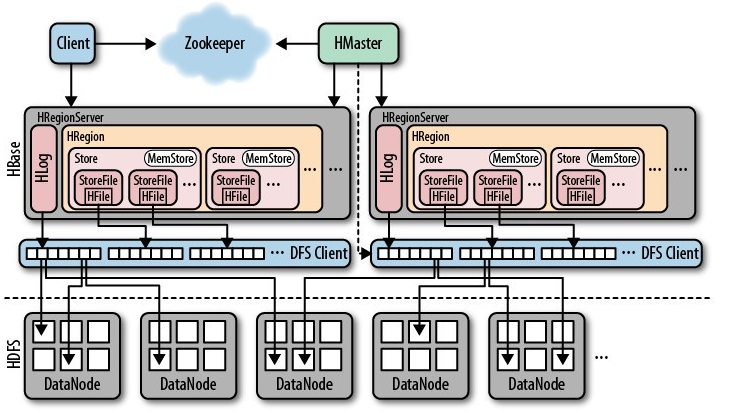
本文首先对 HBase 做简单的介绍,包括其整体架构、依赖组件、核心服务类的相关解析。再重点介绍 HBase 读取数据的流程分析,并根据此流程介绍如何在客户端以及服务端优化性能,同时结合有赞线上 HBase 集群的实际应用情况,将理论和实践结合,希望能给读者带来启发。如文章有纰漏请在下面留言,我们共同探讨共同学习。HBas w397090770 6年前 (2019-02-20) 5260℃ 0评论11喜欢
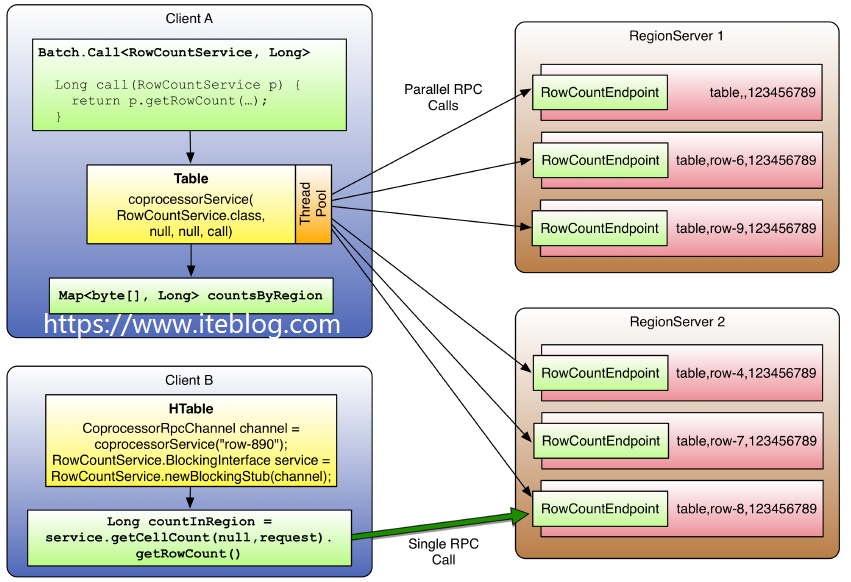
HBase 和 MapReduce 有很高的集成,我们可以使用 MR 对存储在 HBase 中的数据进行分布式计算。但是在很多情况下,例如简单的加法计算或者聚合操作(求和、计数等),如果能够将这些计算推送到 RegionServer,这将大大减少服务器和客户的的数据通信开销,从而提高 HBase 的计算性能,这就是本文要介绍的协处理器(Coprocessors)。HBase w397090770 6年前 (2019-02-17) 6327℃ 2评论13喜欢