Spark 1.1.0中兼容大部分Hive特性,我们可以在Spark中使用Hive。但是默认的Spark发行版本并没有将Hive相关的依赖打包进spark-assembly-1.1.0-hadoop2.2.0.jar文件中,官方对此的说明是:Spark SQL also supports reading and writing data stored in Apache Hive. However, since Hive has a large number of dependencies, it is not included in the default Spark assembly 所以,如果你直 w397090770 10年前 (2014-09-26) 12676℃ 5评论9喜欢
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 但是Spark官方文档给出的属性只是简单的介绍了一下含义,许多细节并没有涉及到。本文及以后几篇文章将会对Spark官方的各个属性进行说明介绍。以下是根据Spark 1.1.0文档中的属性进行说明。Application相关属性绝大多数的属性控制应用程序的内部设置,并且默认值 w397090770 10年前 (2014-09-25) 17936℃ 1评论20喜欢
随着Spark项目的逐渐成熟, 越来越多的可配置参数被添加到Spark中来。在Spark中提供了三个地方用于配置:Spark properties:这个可以控制应用程序的绝大部分属性。并且可以通过 SparkConf 对象或者Java 系统属性进行设置;环境变量(Environment variables):这个可以分别对每台机器进行相应的设置,比如IP。这个可以在每台机器的 $SPARK_HOME/co w397090770 10年前 (2014-09-24) 56999℃ 1评论22喜欢
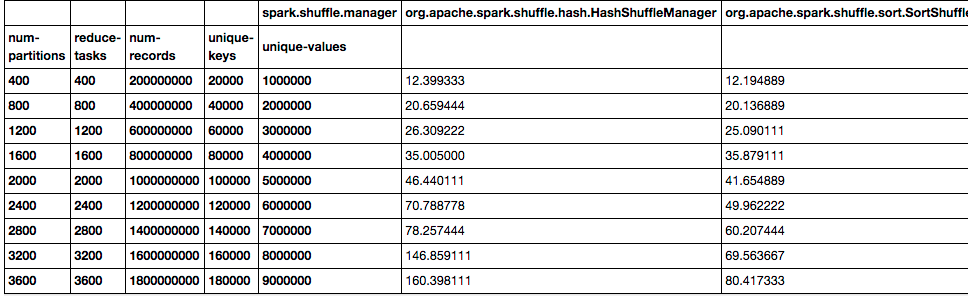
我们都知道Hadoop中的shuffle(不知道原理?可以参见《MapReduce:详细介绍Shuffle的执行过程》),Hadoop中的shuffle是连接map和reduce之间的桥梁,它是基于排序的。同样,在Spark中也是存在shuffle,Spark 1.1之前,Spark的shuffle只存在一种方式实现方式,也就是基于hash的。而在最新的Spark 1.1.0版本中引进了新的shuffle实现(《Spark 1.1.0正式发 w397090770 10年前 (2014-09-23) 15555℃ 3评论15喜欢
Mahout项目发展到了今天已经实现了许多的算法。下面列出Mahout项目主要的算法名称,供大家参考。一、协同过滤 Collaborative Filtering 1、基于用户的协同过滤 User-Based Collaborative Filtering 2、基于项目的协同过滤统 Item-Based Collaborative Filtering 3、交替最小二乘张量分解 Matrix Factorization with Alternating Least Squares 4、基 w397090770 10年前 (2014-09-23) 9475℃ 0评论17喜欢
Apache Spark是快速的通用集群计算系统。它在Java、Scala以及Python等语言提供了高层次的API,并且在通用的图形计算方面提供了一个优化的引擎。同时,它也提供了丰富的高层次工具,这些工具包括了Spark SQL、结构化数据处理、机器学习工具(MLlib)、图形计算(GraphX)以及Spark Streaming。如果想及时了解Spark、Hadoop或者Hbase相关的文章, w397090770 10年前 (2014-09-18) 3564℃ 0评论6喜欢
首先,很感谢大家对本博客的支持。 在此我想给各位网友阐述两件事(1)、QQ群问题;(2)、网站无法注册问题。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop一、QQ群问题(定期清人) 我在今年五月份创建了一个QQ群(群号:138615359),用来讨论Hadoop、Spark等相关方面 w397090770 10年前 (2014-09-17) 3862℃ 4评论8喜欢
Spark 1.1.0已经在前几天发布了(《Spark 1.1.0发布:各个模块得到全面升级》、《Spark 1.1.0正式发布》),本博客对Hive部分进行了部分说明:《Spark SQL 1.1.0和Hive的兼容说明》、《Shark迁移到Spark 1.1.0 编程指南》,在这个版本对Hive的支持更加完善了,如果想在Spark SQL中加入Hive,并加入JDBC server和CLI,我们可以在编译的时候通过加上参 w397090770 10年前 (2014-09-17) 18468℃ 8评论10喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-09-16) 119756℃ 4评论290喜欢
一、前提条件 1、安装好Java JDK 1.6或以上版本; 2、安装好Apache Maven。 如果上述条件准备好之后,下面开始用Maven编译Mahout源码二、git一份Mahout源码 用下面的命令从 Mahout GitHub 仓库Git(如果你电脑没有安装Git软件,可以参照这个安装《Git安装》)一份代码到本地[code lang="JAVA"]git clone git@github.com:apache/mahout.git w397090770 10年前 (2014-09-16) 6153℃ 0评论3喜欢