
文章目录

- Meta 正在引入 Velox,这是一个开源的统一执行引擎(unified execution engine),旨在加速数据管理系统和简化其开发。
- Velox 正在积极开发中,Meta 在 2022 年超大型数据库国际会议(VLDB)上发表了相关论文,里面详细介绍了 Velox 如何提高数据管理系统的效率和一致性。
- Velox 有助于整合和统一数据管理系统,我们相信这将有利于整个行业。我们希望更大的开源社区能加入我们,为这个项目做出贡献。
Meta 的基础设施在支持我们的产品和服务中扮演着重要的角色。我们的数据基础设施生态系统由几十个专门的数据计算引擎组成,所有这些引擎都专注于不同的工作负载,用于各种用例,从 SQL 分析(批处理和交互)到事务性工作负载、流处理、数据摄入等等。最近,随着 Meta 基础设施中人工智能(AI)和机器学习(ML)用例的快速增长,针对特征工程、数据预处理以及 ML 训练和服务管道的其他工作负载,产生了更多的引擎和库。
然而,尽管有相似之处,这些引擎在很大程度上是独立发展的。这种碎片化使得维护和增强它们变得困难,特别是考虑到随着工作负载的发展,执行这些工作负载的硬件也会发生变化。最终,这种碎片化导致系统具有不同的特性集和不一致的语义——降低了数据用户的生产力,这些用户需要与多个引擎交互才能完成任务。
为了应对这些挑战,并为我们自己的产品和世界创建一个更强大、更高效的数据基础设施,Meta 创建了 Velox,并将其开源。这是一个新颖的、最先进的统一执行引擎,旨在加速数据管理系统以及简化其开发。Velox 统一了数据计算引擎中常见的数据密集型组件,同时仍可扩展和适应不同的计算引擎。它将以前只在单个引擎中实现的优化大众化,提供了一个可以实现一致语义的框架。这减少了重复工作,促进了可重用性,并提高了整体效率和一致性。
Velox 正在积极开发中,但它已经处于与 Meta 的十几个数据系统集成的不同阶段,包括 Presto、Spark 和 PyTorch(后者通过一个名为 TorchArrow 的数据预处理库实现),以及其他内部流处理平台、事务引擎、数据吸收系统和基础设施、特性工程的 ML 系统等。
自从首次开源到 GitHub 以来,Velox 开源项目已经吸引了超过150名代码贡献者,包括 Ahana、Intel、Voltron Data 等关键合作者,以及各种学术机构。通过开源和培养 Velox 社区,我们相信我们可以加快数据管理系统开发行业的创新步伐。我们希望更多的个人和公司加入我们的行列。
Velox 概述
虽然数据计算引擎乍一看似乎各不相同,但它们都由一组类似的逻辑组件组成:语言前端、中间表示(intermediate representation、IR)、优化器、执行运行时(execution runtime)和执行引擎(execution engine)。Velox 提供了实现执行引擎所需的构建块,包括在单个主机中执行的所有数据密集型操作,如表达式求值、聚合、排序、JOIN 等——这些也通常称为 data plane。因此,Velox 期望一个优化的计划作为输入,并使用本地主机中的可用资源高效地执行它。

Velox 利用了大量的运行时优化,例如过滤器和连接的重新排序(conjunct reordering)、数组和基于哈希的聚合和连接的 key 标准化、动态过滤器下推(dynamic filter pushdown)和自适应列预取(adaptive column prefetching)。考虑到从传入的数据批次中提取的可用信息和统计数据,这些优化提供了最佳的本地效率。由于复杂数据类型在现代工作负载中无处不在,Velox 是从头开始设计的,以有效支持复杂数据类型,因此在连接和过滤等基数增加和基数减少操作方面广泛依赖于字典编码,同时仍然为基本数据类型提供快速路径。
Velox 提供的主要组件有:
- Type:一个通用类型系统,允许开发人员表示标量、复杂和嵌套数据类型,包括 structs、maps、arrays、functions (lambda)、decimals、tensors 等等。
- Vector:一个兼容 Apache Arrow 的列式内存布局模块,支持多种编码,如 flat, dictionary, constant, sequence/RLE 和参照系(frame of reference),此外还支持惰性实化模式(lazy materialization pattern)和无序结果缓冲区填充(out-of-order result buffer population)。
- Expression Eval:基于向量编码数据构建的最先进的向量化表达式评估引擎,利用常见子表达式消除(subexpression elimination,)、常量折叠(constant folding)、有效空值传播(efficient null propagation)、编码感知评估(encoding-aware evaluation,)、字典剥离( dictionary peeling)和记忆(memoization)等技术。
- Functions:开发人员可以使用这些 API 来构建自定义函数,为标量函数提供一个简单(逐行)和向量化(逐批)接口,并为聚合函数提供一个 API。Velox 还提供了一个与流行的 PrestoSQL 方言兼容的函数包。
- Operators:实现常见的 SQL 操作符,如 TableScan, Project, Filter, Aggregation, Exchange/Merge, OrderBy, TopN, HashJoin, MergeJoin, Unnest 等。
- I/O:一组允许 Velox 集成到其他引擎和运行时环境中的 api,例如:
- Connectors:使开发人员能够为 TableScan 和 TableWrite 操作符对接专门的数据源和接收器(Sink)。
- DWIO:一个可扩展的接口,提供对流行文件格式(如 Parquet、ORC 和 DWRF)的编码/解码支持。
- Storage adapters:这是一个基于字节的可扩展接口,允许 Velox 连接到诸如 Tectonic、S3、HDFS 等存储系统。
- Serializers:一个针对网络通信的序列化接口,可以实现不同的协议,支持 Presto 的 Page 和 Spark 的 UnsafeRow 格式。
- Resource management:处理计算资源的原语集合,如 CPU 和内存管理、溢出、内存和 SSD 缓存。
Velox 的主要集成和实验结果
除了提高效率之外,Velox 还通过统一不同数据计算引擎的执行引擎提供了价值。最最要的集成是 Presto、Spark 和 TorchArrow/PyTorch。
Presto — Prestissimo
作为 Prestissimo 项目的一部分,Velox 被集成到 Presto 中,Presto Java 实现的 workers 被基于 C++ 实现的 Velox 所取代。该项目最初由 Meta 于2020年创建,目前正在与 Ahana 以及其他开源贡献者合作继续开发。
Prestissimo 提供了 Presto 的 HTTP REST 接口的 C++ 实现,包括 worker- worker 交换序列化协议(exchange serialization protocol)、coordinator-worker 编排和状态报告 endpoints,从而为 Presto worker 提供了一个临时的 C++ 替代。主要包括从 Java 实现的 coordinator 接收 Presto plan fragment ,将其转换为 Velox 查询计划,并将其交给 Velox 执行。
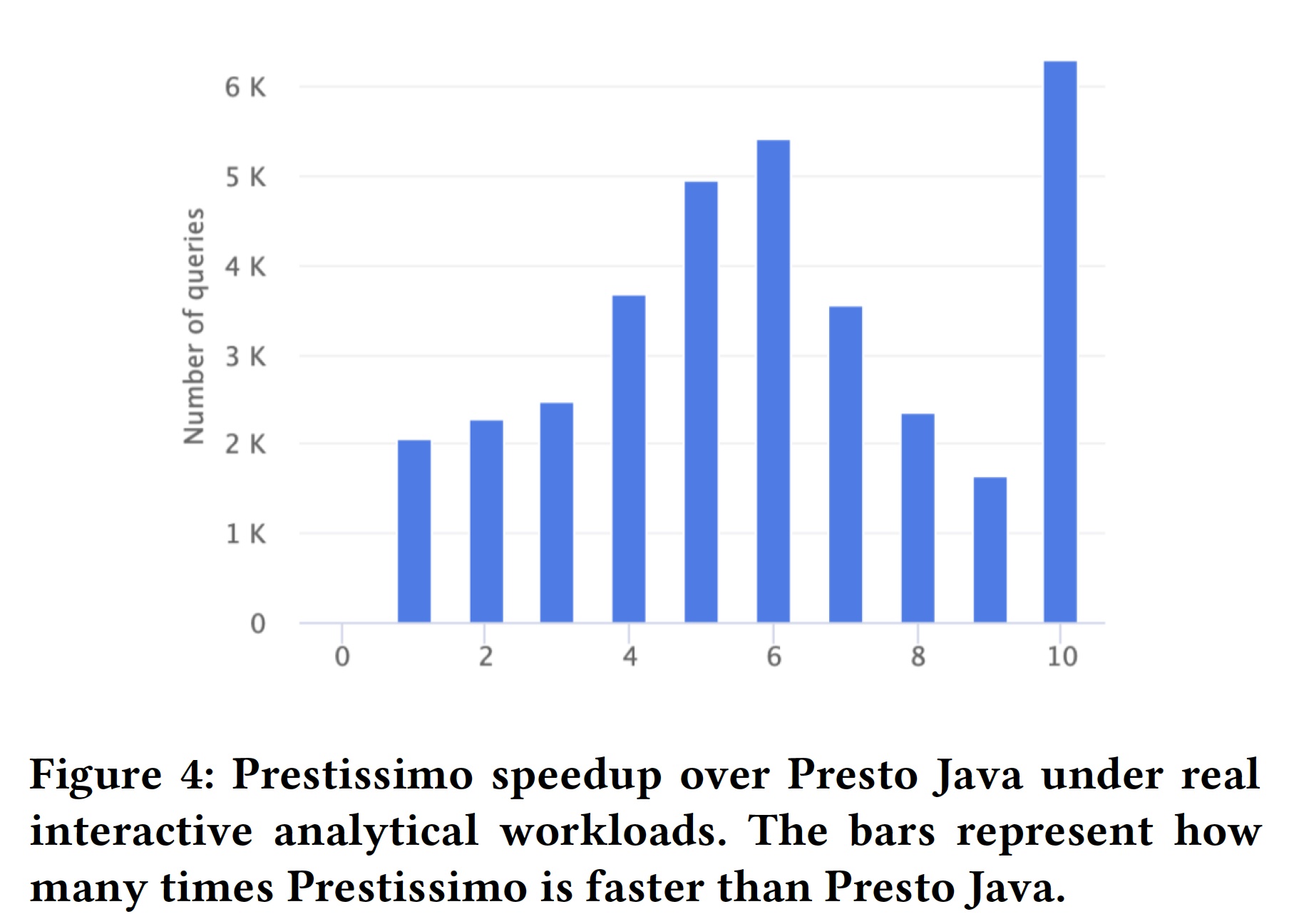
我们进行了两个不同的实验来探索 Velox 在 Presto 中提供的加速。我们的第一个实验使用了 TPC-H 基准测试,在一些 cpu 敏感的查询中,速度提高了一个数量级。对于 shuffle 敏感的查询,我们看到了更温和的加速(平均3-6倍)。
虽然 TPC-H 数据集是一个标准基准测试,但它不能代表真实的工作负载。为了探索 Velox 在这些情况下的表现,我们做了一个实验,在这个实验中,我们执行了 Meta 中各种交互分析工具产生的工作负载。在这个实验中,我们看到数据查询的平均速度提高了6-7倍,有些结果的速度提高了一个数量级以上。可以在这篇论文中查看更详细的介绍。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
Spark — Gluten
Intel 创建的 Gluten 项目支持将 Velox 集成到 Spark 中。Gluten 允许在执行 Spark SQL 查询时在 Spark 环境中使用 C++ 执行引擎(例如 Velox)。 Gluten 通过创建基于 Apache Arrow 数据格式和 Substrait 查询计划的 JNI API 将 Spark JVM 和执行引擎解耦,从而允许 Velox 在 Spark 中使用,只需与 Gluten 的 JNI API 进行集成。
TorchArrow
TorchArrow 是一个 dataframe Python 库,用于深度学习中的数据预处理,是 PyTorch 项目的一部分。TorchArrow 内部将 dataframe 表示形式转换为 Velox 计划,并将其委托给 Velox 执行。 除了聚合 ML 数据预处理库的碎片空间之外,这种集成还允许 Meta 整合分析引擎和 ML 基础设施之间的执行引擎代码。 它通过公开相同的函数/UDF 集并确保跨引擎的一致行为,为 ML 最终用户提供更一致的体验,这些最终用户通常需要与不同的计算引擎交互以完成特定任务。
未来数据库系统的发展方向
Velox 证明了通过将执行引擎整合到一个统一的库中,可以使数据计算系统具有更强的适应性。随着我们继续将 Velox 集成到我们自己的系统中,我们致力于建立一个可持续的开源社区来支持该项目,并加快这个类库的开发和行业采用。我们也有兴趣通过统一这些孤岛之间的功能包和语义来继续模糊 ML 基础设施和传统数据管理系统之间的界限。
展望未来,我们相信 Velox 的统一和模块化特性有潜力为利用数据管理系统的行业带来好处,尤其是那些开发数据管理系统的行业。它将允许我们与硬件供应商合作,并随着硬件的进步主动调整我们的统一软件栈。重用统一且高效的组件还将允许我们随着数据工作负载的发展而更快地创新。我们相信模块化和可重用性是数据库系统开发的未来,我们希望数据公司、学术界和数据库从业人员都能加入我们的行列。
关于 Velox 和这些组件的深入文档可以参考这篇研究论文 Velox: Meta’s unified execution engine。
感谢
我们要感谢 Velox 项目的所有贡献者。 特别感谢 Meta 团队的 Sridhar Anumandla、Philip Bell、Biswapesh Chattopadhyay、Naveen Cherukuri、Wei He、Jiju John、Jimmy Lu、Xiaoxuang Meng、Krishna Pai、Laith Sakka、Bikramjeet Vigand、Kevin Wilfong 以及无数社区 贡献者,包括 Frank Hu、Deepak Majeti、Aditi Pandit 和 Ying Su。
本文翻译自:Introducing Velox: An open source unified execution engine
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Velox 介绍:一个开源的统一执行引擎】(https://www.iteblog.com/archives/10195.html)







