

文章目录
背景

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
在 Uber,数据影响着每一个决定。Presto 是推动 Uber 各种数据分析的核心引擎之一。例如,运营团队在仪表盘等服务中大量使用 Presto;Uber Eats 和营销团队依靠这些查询的结果来决定价格。此外, Presto 还被用于 Uber 的合规部门、增长营销部门和临时数据分析。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
Uber 的 Presto 规模很大。目前,Presto 有9000个日活跃用户,每天处理500K次查询,处理超过 50PB 的数据。Uber 的基础设施包括两个数据中心,7000个节点和跨越两个地区的20个 Presto 集群。
Uber 的 Presto 部署
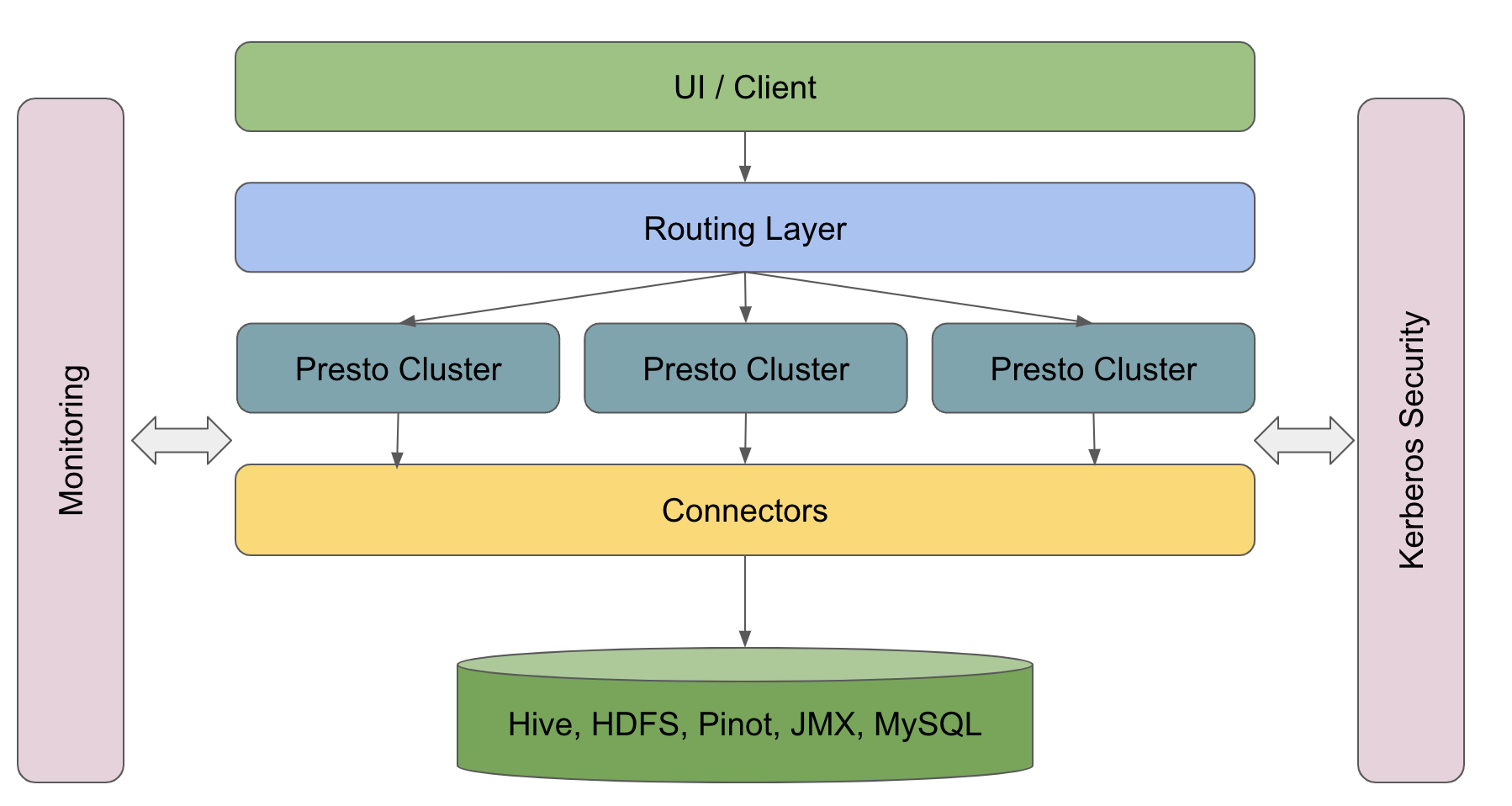
当前架构
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
- UI/客户端层:这包括内部仪表板、Google Data Studio、Tableau 和其他工具。此外,我们还有一些使用 JDBC 或查询解析与 Presto 通信的后端服务。
- 路由层:这一层负责将查询分配到不同的 Presto 集群。路由是基于从每个 Presto 集群提取的统计数据,包括查询和任务的数量、CPU 和内存使用情况等等。我们根据这些统计信息确定每个查询应该路由到哪个集群。换句话说,这一层充当负载均衡和查询拦截的服务。
- Presto 集群:在底部,多个 Presto 集群与底层 Hive、HDFS、Pinot 等进行通信。Join 操作可以在不同的 connectors 或不同的数据集之间执行。
此外,对于上述架构的每一层,我们有:
- 内部监控
- 支持使用 Kerberos

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
Presto 工作负载分为两类:
- 交互式的:由数据科学家和工程师发送的查询;
- 定时任务:主要是定期循环的批量查询,包括 Dashboard, ETL等。
使用 Alluxio 进行本地缓存
最近,我们将 Alluxio 部署在我们三个生产环境的集群中,每个集群有200多个节点。我们使用的是 Alluxio Local Cache 模式,它利用 Presto worker 的本地 NVMe 磁盘。我们不是缓存所有数据,而是通过选择性缓存其中一部分数据。
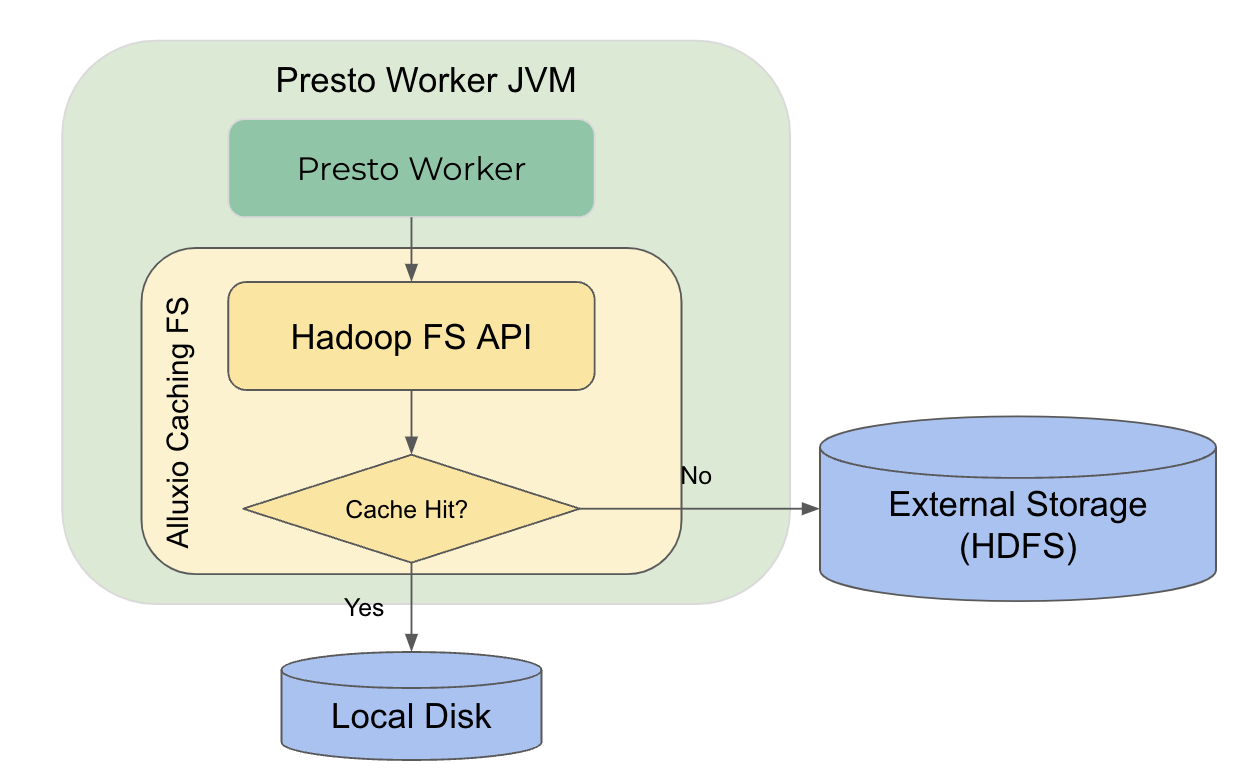
下图是将 Alluxio 作为 Local Cache 的示意图。Alluxio Cache Library 是一个运行在 Presto worker 内部的本地缓存,我们在默认的 HDFS 客户端之上实现了一个层。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
当任何外部 API 从 HDFS 调用中读取数据时,系统首先查看缓存,看看是否命中缓存,如果命中,它将直接从本地 SSD 中读取数据。否则,它将从远程 HDFS 读取数据,并在本地缓存数据以备下一次读取。在此过程中,缓存命中率对整体性能有重要影响。
我们将在下面讨论 Alluxio Local Cache 的详细设计和改进。
主要挑战和解决方案
挑战1:实时分区更新
我们遇到的第一个挑战是实时分区更新。在 Uber,很多表/分区都在不断地变化,因为我们不断地将数据插入 Hudi 表。
挑战在于,仅使用分区 ID 作为缓存键是不够的。同一个分区可能在 Hive 中发生了变化,而 Alluxio 仍然缓存过时的版本。在这种情况下,缓存中的分区已经过时,因此如果数据来自缓存,那么在运行查询时,用户将得到过时的结果,从而导致不一致的体验。
解决方法:将 Hive 的最新修改时间添加到缓存 Key 中
我们的解决方案是为缓存的 Key 添加最新的修改时间,如下所示:
- 之前的缓存 key 为: hdfs://<path>
- 现在的缓存 Key 为:hdfs://<path><mod time>
Presto 目前可以通过 HDFS API 获取每个 Hive 分区文件的最新修改时间。具体来说,在处理 split 时,Presto worker 会显式调用 HDFS listDirectory API,作为 HDFS 返回的信息的一部分,有文件的最新修改时间。通过此解决方案,缓存了最新修改的新分区,确保用户始终获得其数据的一致视图。注意,可能存在一个竞态条件窗口,在 Presto worker 获得最新的修改时间后,远程文件再次更新,而 Presto worker 仍然错过最新的更改。一方面,在如此短的时间间隔内进行两次连续更新是罕见的;另一方面,这样的场景并不比没有缓存的情况差,但是在查询执行期间更改了表目录。在这种情况下,即使是现有的非缓存执行也会导致不一致的行为。另一个注意事项是有一个权衡:过时的分区仍然存在于缓存中,浪费缓存空间,直到删除。目前,我们正在努力改进缓存清除策略。
挑战2:集群节点变更
在 Presto 中,Soft Affinity 调度是通过简单的、基于求模的算法实现的。该算法的缺点是,如果添加或删除一个节点,整个环将被不同的缓存键打乱。因此,如果一个节点加入或离开集群,它可能会损害所有节点的缓存命中率,这是有问题的。
为了提高缓存命中率,在 Presto 中读取给定分区的数据会定位到相同的节点。虽然这很好,但问题是 Presto 之前使用了一个简单的哈希函数,当集群发生变化时,这个函数可能会失效。
如下所示,目前,我们使用一个简单的基于哈希 mod 的节点查找:key 4 % 3 nodes = worker#1。现在 worker#3 宕机,新的查找为:key 4 % 2 nodes = worker#0,但 worker#0 没有缓存相关的数据。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
解决方案:基于节点 id 的一致性哈希
一致哈希(Consistent hashing)是解决方案。与基于求模的功能不同,所有节点都放在一个虚拟环上。无论节点加入或离开,环上节点的相对顺序都不会改变。我们总是查找环上的键,而不是使用求模得到的 hash 值。我们可以确保无论做了多少更改,它们总是基于相同的节点集。此外,我们使用复制来提高健壮性。这是解决集群成员问题的解决方案。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
挑战3:缓存大小限制
Uber 的数据湖规模比较大,Presto 集群每天扫描50PB的数据。但是,我们的本地磁盘空间每个节点只有 500 GB。Presto 查询访问的数据量远远大于 Worker 节点上可用的磁盘空间。尽管可以将所有内容都放入缓存中,但经常清理缓存可能会损害整体缓存性能。
解决方案: Cache Filter
其思想是只缓存选定的数据子集,其中包括某些表和一定数量的分区。解决方案是开发一个 cache filter,这是一种决定是否缓存一张表以及缓存多少个分区的机制。下面是一个配置示例:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
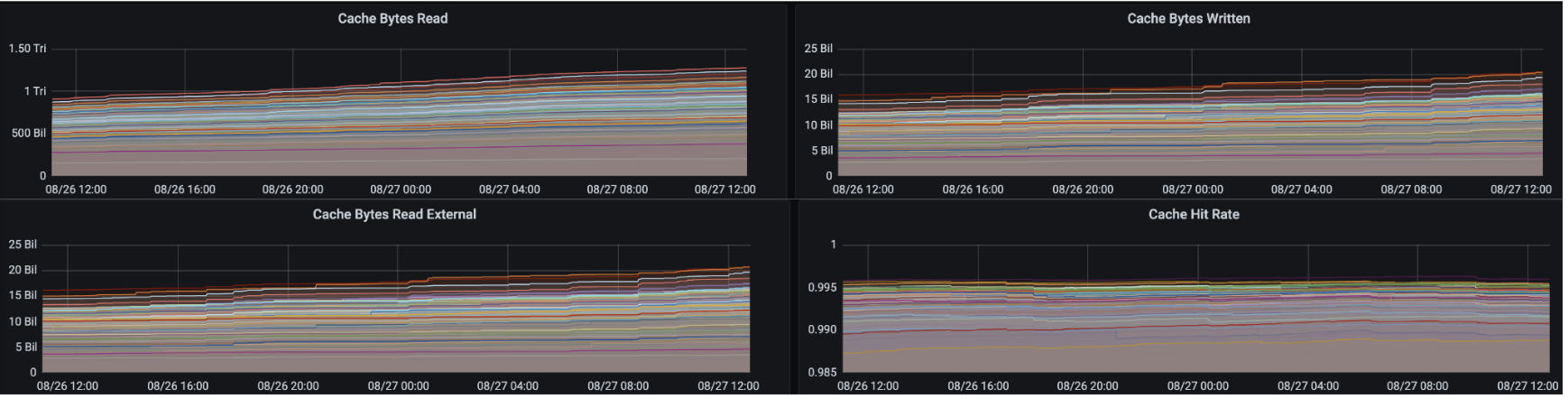
cache filter 大大提高了缓存命中率,从~65%提高到>90%。下面是 cache filter 需要注意的几个方面:
- 它是手动、并且是静态配置
- 需要根据访问频率进行设置
- 最常访问的表;
- 需要根据访问频率进行设置
- 不经常更改的表
- 理想情况下,应该基于 shadow caching 的数据和表级指标。
我们还通过监控/仪表板实现了可观察性,它与 Uber 的内部指标平台集成,使用发送到基于 grafana 的仪表板的 JMX 指标。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
元数据优化
在下面的小节中,我们将讨论对本地缓存元数据的改进。
本地缓存的文件级元数据
动机
首先,我们希望防止过时的缓存。底层数据文件可能由第三方框架更改。注意,这种情况在 Hive 表中可能很少见,但在 Hudi 表中很常见。
其次,每天从 HDFS 读取的非复制数据可能很大,但我们没有足够的缓存空间来缓存所有数据。因此,我们可以通过为每个表设置配额来引入范围配额管理。
第三,元数据应该在服务器重新启动后可以恢复。我们将元数据存储在内存而不是磁盘中的本地缓存中,这使得在服务器关闭并重新启动时不可能恢复元数据。
高级别的方法
因此,我们提出文件级元数据(file-level metadata),它保存文件的最后修改时间和缓存的每个数据文件的范围。文件级元数据存储应该持久保存在磁盘上,这样数据才不会在重新启动后消失。
随着文件级元数据的引入,数据将有多个版本。当数据更新时,会生成一个新的时间戳,对应于一个新的版本。一个存储新 page 的新文件夹将根据这个新时间戳创建。同时,我们将尝试删除旧的时间戳。
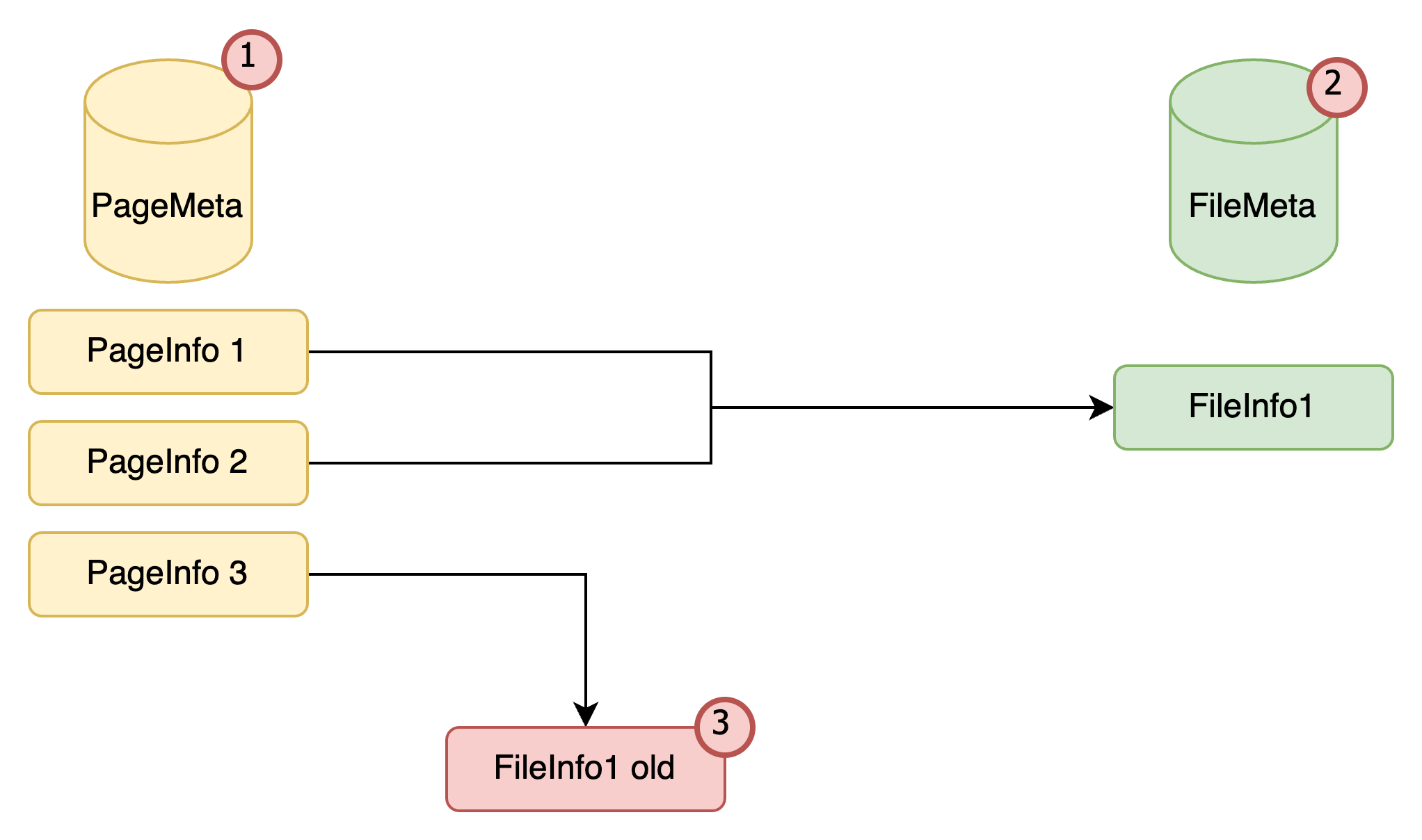
缓存数据和元数据结构
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如上所示,我们有两个文件夹对应两个时间戳:timestamp1 和 timestamp2。通常,当系统运行时,不会同时有两个时间戳,因为我们将删除旧的 timestamp1,只保留 timestamp2。然而,在繁忙的服务器或高并发性的情况下,我们可能无法删除旧时间戳的数据,在这种情况下,我们可能同时有两个时间戳的数据。此外,我们维护一个元数据文件,其中包含 protobuf 格式的文件信息和最新的时间戳。这确保了 Alluxio 的本地缓存只从最新的时间戳读取数据。当服务器重新启动时,从元数据文件中读取时间戳信息,以便正确管理配额和最后修改时间。
Metadata 感知
Cache Context
由于 Alluxio 是一种通用的缓存解决方案,它仍然需要计算引擎(如 Presto)将元数据传递给 Alluxio。为此,我们在 Presto 端实现了 HiveFileContext。对于 Hive 表或 Hud i表中的每个数据文件,Presto 都会创建一个 HiveFileContext。在打开 Presto 文件时,Alluxio 会使用这些信息。
当调用 openFile 时,Alluxio 创建一个 PrestoCacheContext 的新实例,它保存 HiveFileContext,并具有作用域(4个级别:database, schema, table, partition)、quota、缓存标识符(即文件路径的 MD5 值)和其他信息。我们将把这个 cache context 传递给本地文件系统。因此,Alluxio 可以管理元数据并收集指标。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
Presto 侧的每个查询指标聚合
除了将数据从 Presto 传递到 Alluxio 之外,我们还可以回调 Presto。在执行查询操作时,我们将知道一些内部指标,例如有多少字节的数据读取到缓存中,有多少字节的数据从外部 HDFS 存储中读取。
如下所示,我们将包含 PrestoCacheContext 的 HiveFileContext 传递给本地缓存文件系统(LocalCacheFileSystem),之后本地缓存文件系统回调(IncremetCounter)给 CacheContext。这个回调链将继续到 HiveFileContext,然后到 RuntimeStats。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
在 Presto 中,RuntimeStats 用于在执行查询时收集度量信息,以便我们可以执行聚合操作。之后,我们可以在 Presto 的 UI 或 JSON 文件中看到关于本地缓存文件系统的信息。我们可以让 Alluxio 和 Presto 在上述过程中紧密配合。在 Presto 方面,我们有更好的统计数据;在 Alluxio 方面,我们对元数据有了更清晰的了解。
未来工作
下一步
首先,我们希望缓存更多的表,并通过自动化改进表的缓存过程,Alluxio Shadow Cache (SC) 将在这方面有所帮助。 其次,我们希望对不断变化的分区/Hudi 表有更好的支持。 最后,负载均衡是我们可以实现的另一个优化。 我们的旅程还有很长的路要走。
随着计算-存储分离以及大数据容器化继续成为趋势,我们相信像 Alluxio 这样连接计算和存储的统一层将继续发挥关键作用。
性能调优
由于上述回调过程使 CacheContext 的生命周期显着增长,我们遇到了一些 GC 延迟上升的问题,我们正在努力解决。
Adopt Semantic Cache (SC)
我们将根据我们建议的文件级元数据来实现语义缓存(SC)。 例如,我们可以将数据结构保存在 Parquet 或 ORC 文件中。
更高效的反序列化
为了实现更有效的反序列化,我们将使用flatbuf而不是protobuf。尽管在ORC工厂中使用protobuf来存储元数据,但我们发现在Alluxio与Facebook的合作中,ORC的元数据带来了超过20-30%的CPU使用总量。因此,我们计划用flatbuf替换现有的protobuf来存储缓存和元数据,预计这将显著提高反序列化的性能。
为了实现更高效的反序列化,我们将使用 flatbuf 代替 protobuf。 虽然在 ORC factory 中使用了 protobuf 来存储元数据,但我们发现在 Alluxio 与 Facebook 的合作中,ORC 的元数据带来了超过 20-30% 的总 CPU 使用率。 因此,我们计划用 flatbuf 替换现有的 protobuf 来存储缓存和元数据,这有望显着提高反序列化的性能。
总结
在本文中,我们讨论了 Uber Presto 缓存解决方案的设计和实现,以提高 Uber 在各种用例中的交互式查询性能。 我们分享了 Presto 在 Uber 采用 Alluxio Local Cache 的历程,讨论了我们如何定制和扩展现有解决方案,以解决我们遇到的特定于 Uber 规模和用例的挑战。 该解决方案已在生产环境中运行超过四分之一,并且维护开销最小。
本文翻译自:Speed Up Presto at Uber with Alluxio Local Cache
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Alluxio Local Cache 加速 Presto 查询在 Uber 的应用】(https://www.iteblog.com/archives/10197.html)






