由于本文比较长,考虑到篇幅问题,所以将本文拆分为二,请阅读本文之前先阅读本文的第一部分《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》。为你带来的不变,敬请谅解。 与MultipleOutputFormat类不一样的是,MultipleOutputs可以为不同的输出产生不同类型,到这里所说的MultipleOutputs类还是旧版本的功能,后 w397090770 11年前 (2013-11-27) 21579℃ 0评论17喜欢
直到目前,我们看到的所有Mapreduce作业都输出一组文件。但是,在一些场合下,经常要求我们将输出多组文件或者把一个数据集分为多个数据集更为方便;比如将一个log里面属于不同业务线的日志分开来输出,并交给相关的业务线。 用过旧API的人应该知道,旧API中有 org.apache.hadoop.mapred.lib.MultipleOutputFormat和org.apache.hadoop.mapr w397090770 11年前 (2013-11-26) 15191℃ 1评论10喜欢
根据官方文档(Apache Hadoop MapReduce - Migrating from Apache Hadoop 1.x to Apache Hadoop 2.x:http://hadoop.apache.org/docs/r2.2.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduce_Compatibility_Hadoop1_Hadoop2.html)所述,Hadoop2.x是对Hadoop1.x程序兼容的,由于Hadoop2.x对Hadoop1.x做了重大的结构调整,很多程序依赖库被拆分了,所以以前(Hadoop1.x)的依赖库不再可 w397090770 11年前 (2013-11-26) 9618℃ 3评论2喜欢
索引是标准的数据库技术,hive 0.7版本之后支持索引。Hive提供有限的索引功能,这不像传统的关系型数据库那样有“键(key)”的概念,用户可以在某些列上创建索引来加速某些操作,给一个表创建的索引数据被保存在另外的表中。 Hive的索引功能现在还相对较晚,提供的选项还较少。但是,索引被设计为可使用内置的可插拔的java w397090770 11年前 (2013-11-15) 23295℃ 3评论16喜欢
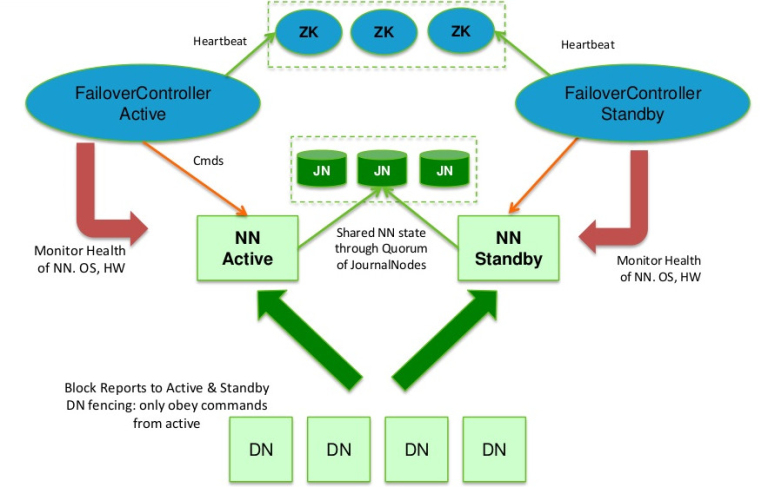
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。 主要在两方面影响了HDFS的可用性: (1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个 w397090770 11年前 (2013-11-14) 10676℃ 3评论22喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ 如果你想查询某个表的某 w397090770 11年前 (2013-11-13) 18057℃ 4评论17喜欢
如果你想搭建伪分布式Hadoop平台,请参见本博客《在Fedora上部署Hadoop2.2.0伪分布式平台》 经过好多天的各种折腾,终于在几台电脑里面配置好了Hadoop2.2.0分布式系统,现在总结一下如何配置。 前提条件: (1)、首先在每台Linux电脑上面安装好JDK6或其以上版本,并设置好JAVA_HOME等,测试一下java、javac、jps等命令 w397090770 11年前 (2013-11-06) 21320℃ 6评论27喜欢
Hive可以运行保存在文件里面的一条或多条的语句,只要用-f参数,一般情况下,保存这些Hive查询语句的文件通常用.q或者.hql后缀名,但是这不是必须的,你也可以保存你想要的后缀名。假设test文件里面有一下的Hive查询语句:[code lang="JAVA"]select * from p limit 10;select count(*) from p;[/code]那么我们可以用下面的命令来查询:[cod w397090770 11年前 (2013-11-06) 10208℃ 2评论5喜欢
1、新增"Explain dependency"语法,以json格式输出执行语句会读取的input table和input partition信息,这样debug语句会读取哪些表就很方便了[code lang="JAVA"]hive> explain dependency select count(1) from p;OK{"input_partitions":[{"partitionName":"default@p@stat_date=20110728/province=bj"},{"partitionName":"default@p@stat_date=20110728/provinc w397090770 11年前 (2013-11-04) 7562℃ 2评论4喜欢
在Hive0.11.0版本新引进了一个新的特性,也就是当用户将Hive查询结果输出到文件,用户可以指定列的分割符,而在之前的版本是不能指定列之间的分隔符,这样给我们带来了很大的不变,在Hive0.11.0之前版本我们一般是这样用的:[code lang="JAVA"]hive> insert overwrite local directory '/home/wyp/Documents/result'hive> select * from test;[/code] w397090770 11年前 (2013-11-04) 21090℃ 9评论10喜欢