在 Spark AI Summit 的第一天会议中,数砖重磅发布了 Delta Engine。这个引擎 100% 兼容 Apache Spark 的向量化查询引擎,并且利用了现代化的 CPU 架构,优化了 Spark 3.0 的查询优化器和缓存功能。这些特性显著提高了 Delta Lake 的查询性能。当然,这个引擎目前只能在 Databricks Runtime 7.0 中使用。数砖研发 Delta Engine 的目的过去十年,存储的速 w397090770 5年前 (2020-06-28) 1045℃ 0评论1喜欢
在2020年6月24日的 Spark AI summit Keynote 上,数砖的首席执行官 Ali Ghodsi 宣布其收购了 Redash 开源产品的背后公司 Redash!如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop通过这次收购,Redash 加入了 Apache Spark、Delta Lake 和 MLflow,创建了一个更大、更繁荣的开源系统,为数据团队提供了同类中最好的 w397090770 5年前 (2020-06-26) 1007℃ 0评论3喜欢
尽量不要把数据 collect 到 Driver 端如果你的 RDD/DataFrame 非常大,drive 端的内存无法放下所有的数据时,千万别这么做[code lang="scala"]data = df.collect()[/code]Collect 函数会尝试将 RDD/DataFrame 中所有的数据复制到 driver 端,这时候肯定会导致 driver 端的内存溢出,然后进程出现 crash。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 5年前 (2020-06-23) 782℃ 0评论3喜欢
双重检查锁定模式(也被称为"双重检查加锁优化","锁暗示"(Lock hint)) 是一种软件设计模式用来减少并发系统中竞争和同步的开销。双重检查锁定模式首先验证锁定条件(第一次检查),只有通过锁定条件验证才真正的进行加锁逻辑并再次验证条件(第二次检查)。该模式在某些语言在某些硬件平台的实现可能是不安全的。有 w397090770 5年前 (2020-06-19) 912℃ 0评论4喜欢
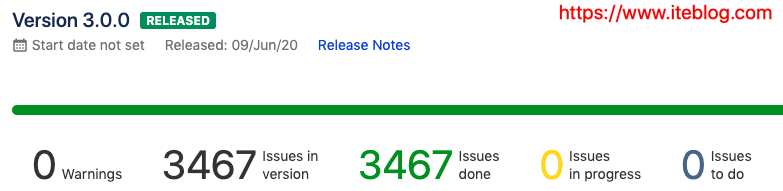
原计划在2019年年底发布的 Apache Spark 3.0.0 今天终于赶在下周二举办的 Spark Summit AI 会议之前正式发布了! Apache Spark 3.0.0 自2018年10月02日开发到目前已经经历了近21个月!这个版本的发布经历了两个预览版以及三次投票:2019年11月06日第一次预览版,参见 https://spark.apache.org/news/spark-3.0.0-preview.html2019年12月23日第二次预览版,参见 https w397090770 5年前 (2020-06-18) 1849℃ 0评论4喜欢
2010年,Facebook 的工程师在 ICDC(IEEE International Conference on Data Engineering) 发表了一篇 《RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems》 的论文,介绍了其为基于 MapReduce 的数据仓库设计的高效存储结构,这就是我们熟知的 RCFile(Record Columnar File)。下面介绍 RCFile 的一些诞生背景和设计。背景早在2010 w397090770 5年前 (2020-06-16) 1363℃ 0评论8喜欢
Facebook Spark 的使用情况在介绍下面文章之前我们来看看 Facebook 的 Spark 使用情况:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopSpark 是 Facebook 内部最大的 SQL 查询引擎(按 CPU 使用率计算)在存储计算分 w397090770 5年前 (2020-06-14) 1590℃ 0评论6喜欢
导言本文主要介绍如何快速的通过Spark访问 Iceberg table。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopSpark通过DataSource和DataFrame API访问Iceberg table,或者进行Catalog相关的操作。由于Spark Data Source V2 API还在持续的演进和修改中,所以Iceberg在不同的Spark版本中的使用方式有所不同。版本对比 w397090770 5年前 (2020-06-10) 10131℃ 0评论4喜欢
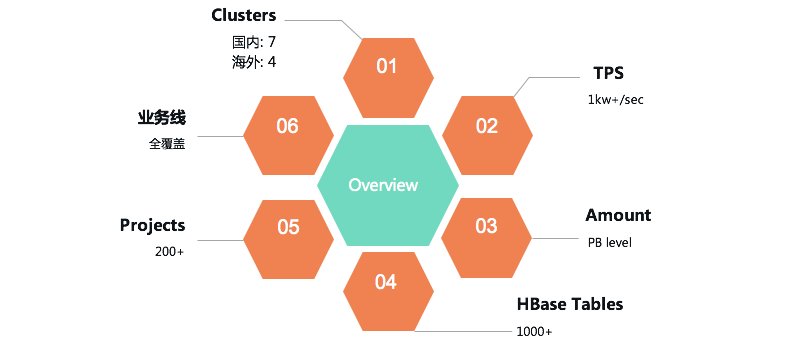
滴滴HBase团队日前完成了0.98版本 -> 1.4.8版本滚动升级,用户无感知。新版本为我们带来了丰富的新特性,在性能、稳定性与易用性方便也均有很大提升。我们将整个升级过程中面临的挑战、进行的思考以及解决的问题总结成文,希望对大家有所帮助。背景目前HBase服务在我司共有国内、海外共计11个集群,总吞吐超过1kw+/s,服务 w397090770 5年前 (2020-06-10) 1587℃ 0评论6喜欢
大数据处理技术现今已广泛应用于各个行业,为业务解决海量存储和海量分析的需求。但数据量的爆发式增长,对数据处理能力提出了更大的挑战,同时对时效性也提出了更高的要求。业务通常已不再满足滞后的分析结果,希望看到更实时的数据,从而在第一时间做出判断和决策。典型的场景如电商大促和金融风控等,基于延迟数 w397090770 5年前 (2020-06-08) 3953℃ 0评论3喜欢