数据库事业部承载着阿里巴巴及阿里云的数据库服务,为超过数万家中国企业提供专业的数据库服务。我们提供在线事务处理、缓存文档服务、BigData NoSQL服务 、在线分析处理的全栈数据库产品。本团队提供基于Apache HBase\Phoenix\Spark\Cassandra\Solr\ES等,结合自研技术,打造存储、检索、计算的一站式的BigData NoSQL自主可控的服务,满足客 w397090770 7年前 (2018-01-30) 6487℃ 1评论28喜欢
经过几个星期的开发,本博客微信小程序(过往记忆大数据技术博客)正式上线了!至此大家可以通过微信公众号、微信小程序等方式访问本博客了。下面来看看本博客微信公众号的一些预览:微信小程序首页在首页可以查看本博客最新的文章,热门文章以及搜索等。文章页文章页可以文章的详情,功 w397090770 7年前 (2018-01-28) 1986℃ 0评论7喜欢
在 《使用Python编写Hive UDF》 文章中,我简单的谈到了如何使用 Python 编写 Hive UDF 解决实际的问题。我们那个例子里面仅仅是一个很简单的示例,里面仅仅引入了 Python 的 sys 包,而这个包是 Python 内置的,所有我们不需要担心 Hadoop 集群中的 Python 没有这个包;但是问题来了,如果我们现在需要使用到 numpy 中的一些函数呢?假设我们 w397090770 7年前 (2018-01-25) 6571℃ 3评论23喜欢
Hive 内置为我们提供了大量的常用函数用于日常的分析,但是总有些情况这些函数还是无法满足我们的需求;值得高兴的是,Hive 允许用户自定义一些函数,用于扩展 HiveQL 的功能,这类函数叫做 UDF(用户自定义函数)。使用 Java 编写 UDF 是最常见的方法,但是本文介绍的是如何使用 Python 来编写 Hive 的 UDF 函数。如果想及时了解S w397090770 7年前 (2018-01-24) 14550℃ 0评论27喜欢
Apache Pulsar(孵化器项目)是一个企业级的发布订阅(pub-sub)消息系统,最初由Yahoo开发,并于2016年底开源,现在是Apache软件基金会的一个孵化器项目。Pulsar在Yahoo的生产环境运行了三年多,助力Yahoo的主要应用,如Yahoo Mail、Yahoo Finance、Yahoo Sports、Flickr、Gemini广告平台和Yahoo分布式键值存储系统Sherpa。如果想及时了解Spark、Hadoop w397090770 7年前 (2018-01-16) 1998℃ 0评论9喜欢
在计算机人工智能领域,距离(distance)、相似度(similarity)是经常出现的基本概念,它们在自然语言处理、计算机视觉等子领域有重要的应用,而这些概念又大多源于数学领域的度量(metric)、测度(measure)等概念。 曼哈顿距离曼哈顿距离又称计程车几何距离或方格线距离,是由十九世纪的赫尔曼·闵可夫斯基所创词汇 ,为欧几里得几 w397090770 7年前 (2018-01-14) 6836℃ 0评论27喜欢
我们每天都可能会操作 HDFS 上的文件,这就很难避免误操作,比如比较严重的误操作就是删除文件。本文针对这个问题提供了三种恢复误删除文件的方法,希望对大家的日常运维有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop通过垃圾箱恢复HDFS 为我们提供了垃圾箱的功能, w397090770 7年前 (2018-01-14) 10200℃ 2评论23喜欢
本文作者:汪愈舟 俞育才 郭晨钊 程浩(英特尔),李元健(百度)Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇到不少易用性和可扩展性的挑战。为了应对这些挑战,英特尔大数据技术团 w397090770 7年前 (2018-01-11) 91098℃ 0评论78喜欢
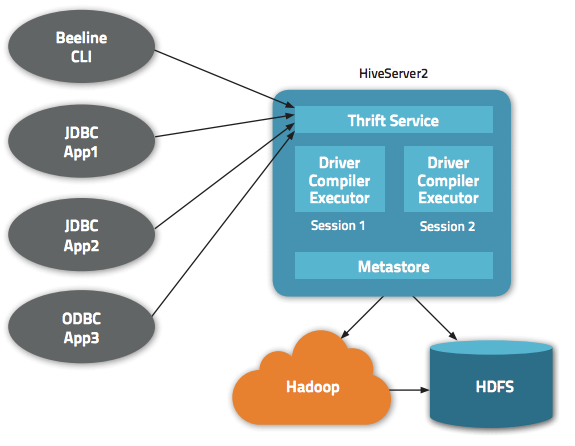
Hive 除了为我们提供一个 CLI 方式来查询数据之外,还给我们提供了基于 JDBC/ODBC 的方式来连接 Hive,这就是 HiveServer2(HiveServer)。但是默认情况下通过 JDBC 连接 HiveServer2 不需要任何的权限认证(hive.server2.authentication = NONE);这意味着任何知道 ThriftServer 地址的人都可以连接我们的 Hive,并执行一些操作。更可怕的是,这些人甚至可 w397090770 7年前 (2018-01-11) 13467℃ 5评论18喜欢
本 hosts 文件更新时间为 2018年07月22日。原作者为 Google Hosts 组织本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、 w397090770 7年前 (2018-01-09) 16267℃ 1评论43喜欢