重庆博尼施科技有限公司是一家商用车全周期方案服务商,利用车联网、云计算、移动互联网技术,在物流领域 为商用车的生产、销售、使用、售后、回收各个环节提供一站式解决方案,其中的新能源车辆监控系统就是由该公司提供的,本文是阿里云客户重庆博尼施科技有限公司介绍如何使用阿里云 HBase 来实现新能源车辆监控系统 w397090770 6年前 (2018-11-29) 4310℃ 2评论16喜欢
Protobuf (全称 Protocol Buffers)是 Google 开发的一种数据描述语言,能够将结构化数据序列化,可用于数据存储、通信协议等方面。在 HBase 里面用使用了 Protobuf 的类库,目前 Protobuf 最新版本是 3.6.1(参见这里),但是在目前最新的 HBase 3.0.0-SNAPSHOT 对 Protobuf 的依赖仍然是 2.5.0(参见 protobuf.version),但是这些版本的 Protobuf 是互补兼 w397090770 6年前 (2018-11-26) 5504℃ 0评论10喜欢
Apache Spark 2.4 新增了24个内置函数和5个高阶函数,本文将对这29个函数的使用进行介绍。关于 Apache Spark 2.4 的新特性,可以参见 《Apache Spark 2.4 正式发布,重要功能详细介绍》。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop针对数组类型的函数array_distinctarray_distinct(array<T>): array<T w397090770 6年前 (2018-11-25) 7585℃ 0评论18喜欢
近几年来,人工智能逐渐火热起来,特别是和大数据一起结合使用。人工智能的主要场景又包括图像能力、语音能力、自然语言处理能力和用户画像能力等等。这些场景我们都需要处理海量的数据,处理完的数据一般都需要存储起来,这些数据的特点主要有如下几点:大:数据量越大,对我们后面建模越会有好处;稀疏:每行 w397090770 6年前 (2018-11-22) 3326℃ 1评论10喜欢
Apache Spark 2.4 是在11月08日正式发布的,其带来了很多新的特性具体可以参见这里,本文主要介绍这次为复杂数据类型新引入的内置函数和高阶函数。本次 Spark 发布共引入了29个新的内置函数来处理复杂类型(例如,数组类型),包括高阶函数。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop w397090770 6年前 (2018-11-21) 2500℃ 0评论2喜欢
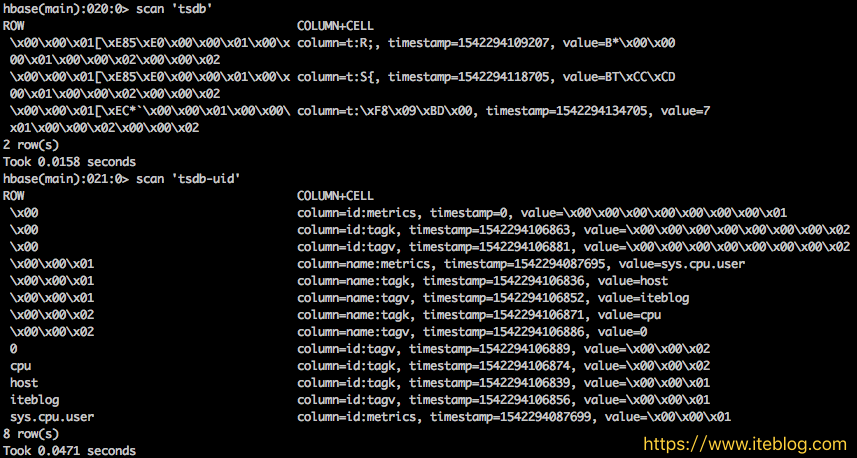
通过《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》 文章我们已经了解 OpenTSDB 底层的 HBase Rowkey 是如何设计的了。我们现在来测试一下 OpenTSDB 导入的时序数据到底长什么样子。在 OpenTSDB 里面默认存时序数据的表为 tsdb。前面说了,每个指标名称、标签名称以及标签值都有唯一的编码,这些编码数据是存放在 tsdb-uid 表里面。为了更加 w397090770 6年前 (2018-11-16) 3032℃ 3评论6喜欢
OpenTSDB 是基于 HBase 的可扩展、开源时间序列数据库(Time Series Database),可以用于存储监控数据、物联网传感器、金融K线等带有时间的数据。它的特点是能够提供最高毫秒级精度的时间序列数据存储,能够长久保存原始数据并且不失精度。它拥有很强的数据写入能力,支持大并发的数据写入,并且拥有可无限水平扩展的存储容量。目 w397090770 6年前 (2018-11-15) 5176℃ 1评论10喜欢
到目前为止,Scala 环境下至少存在6种 Json 解析的类库,这里面不包括 Java 语言实现的 Json 类库。所有这些库都有一个非常相似的抽象语法树(AST)。而 json4s 项目旨在提供一个单一的 AST 树供其他 Scala 类库来使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopjson4s 的使用非常的简单,它可以将 w397090770 6年前 (2018-11-15) 1129℃ 0评论4喜欢
美国时间 2018年11月08日 正式发布了。一如既往,为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.4 带来了许多新功能,如下:添加一种支持屏障模式(barrier mode)的调度器,以便与基于MPI的程序更好地集成,例如, 分布式深度学习框架;引入了许多内置的高阶函数,以便更容易处理复杂的数据类型(比如数组和 map); w397090770 6年前 (2018-11-10) 4552℃ 0评论6喜欢
Apache Spark 2.4 与昨天正式发布,Apache Spark 2.4 版本是 2.x 系列的第五个版本。 如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Spark 2.4 为我们带来了众多的主要功能和增强功能,主要如下:新的调度模型(Barrier Scheduling),使用户能够将分布式深度学习训练恰当地嵌入到 Spark 的 stage 中 w397090770 6年前 (2018-11-09) 3358℃ 0评论1喜欢