本章节我们提供一些 Java 8 中的 IntStream、LongStream 和 DoubleStream 使用范例。IntStream、LongStream 和 DoubleStream 分别表示原始 int 流、 原始 long 流 和 原始 double 流。这三个原始流类提供了大量的方法用于操作流中的数据,同时提供了相应的静态方法来初始化它们自己。这三个原始流类都在 java.util.stream 命名空间下。java.util.stream.Int w397090770 3年前 (2022-03-31) 227℃ 0评论1喜欢
Java 8 流的新类 java.util.stream.Collectors 实现了 java.util.stream.Collector 接口,同时又提供了大量的方法对流 ( stream ) 的元素执行 map and reduce 操作,或者统计操作。本章节,我们就来看看那些常用的方法,顺便写几个示例练练手。Collectors.averagingDouble()Collectors.averagingDouble() 方法将流中的所有元素视为 double 类型并计算他们的平均值 w397090770 3年前 (2022-03-31) 200℃ 0评论1喜欢
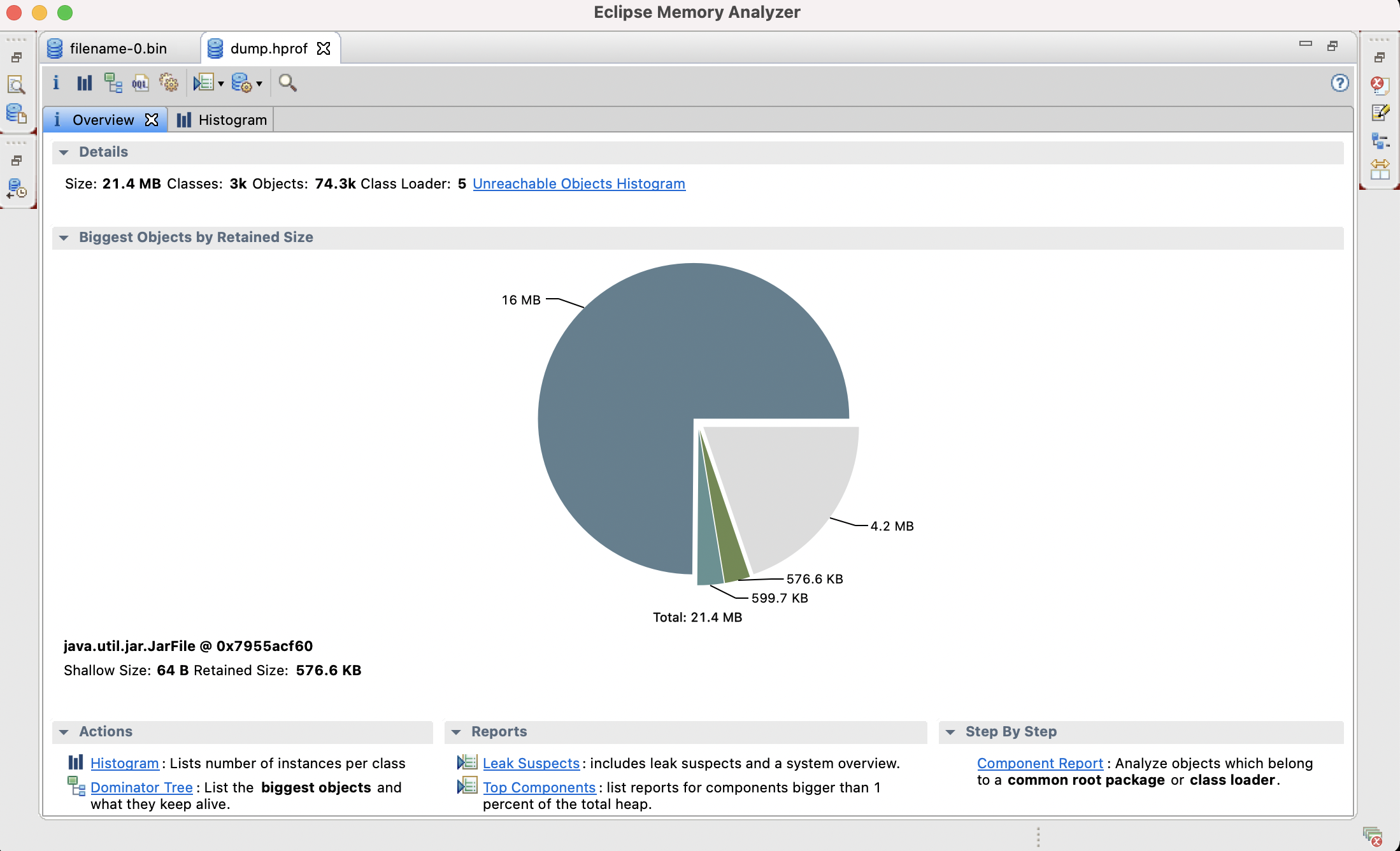
在安装完 JDK 之后,会自带安装一些常用的小工具,而 jmap 就是其中一个比较常用的。jmap 打印给定进程、core file 或远程调试服务器的共享对象内存映射或堆内存细节。我们可以查看下 jmap 的命令使用:[code lang="bash"]iteblog@iteblog.com:~|⇒ jmapUsage: jmap [option] <pid> (to connect to running process) jmap [option] <executable <co w397090770 4年前 (2021-08-02) 869℃ 0评论0喜欢
Java 14 计划将会在今年的3月17日发布,Java 14 包含的 JEP(Java Enhancement Proposals 的缩写,Java 增强建议)比 Java 12 和 13 两个版本加起来还要多。那么,对于每天编写和维护代码的 Java 开发人员来说,哪个特性值得我们关注呢?如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文我将介绍以下几个重 w397090770 5年前 (2020-03-07) 945℃ 0评论2喜欢
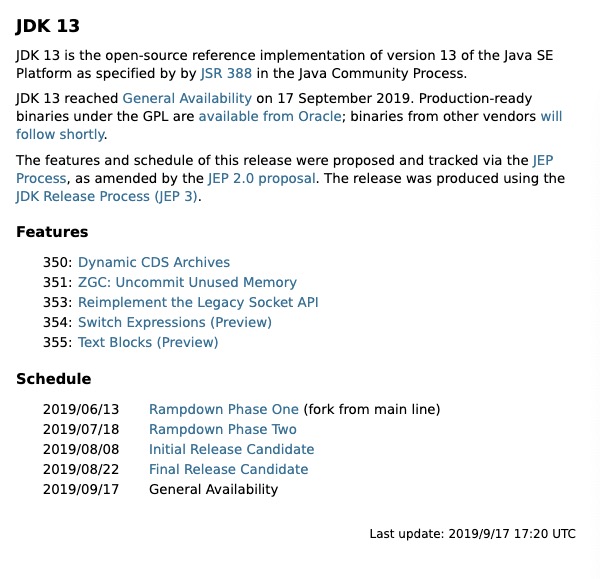
就在昨天(2019年09月17日),JDK 13 已经处于 General Availability 状态,已经正式可用了。General Availability(简称 GA)是一种正式版本的命名,也就是官方开始推荐广泛使用了,我们熟悉的 MySQL 就用 GA 来命令其正式版本。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop从上图我们可以看到 JDK 13 带来了 w397090770 5年前 (2019-09-18) 1556℃ 0评论1喜欢
最近使用 Intellij IDEA 打开之前写的 HBase 工程代码,发现里面有个语法错误,但之前都没问题。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop后面发现,不管你使用的 JDK 是什么版本(我这里用的是 JDK 1.8),Intellij IDEA 设置的 Language Level 都是 1.5,如下:如果想及时了解Spark、Hadoop或者Hbase w397090770 7年前 (2018-07-12) 6145℃ 0评论4喜欢
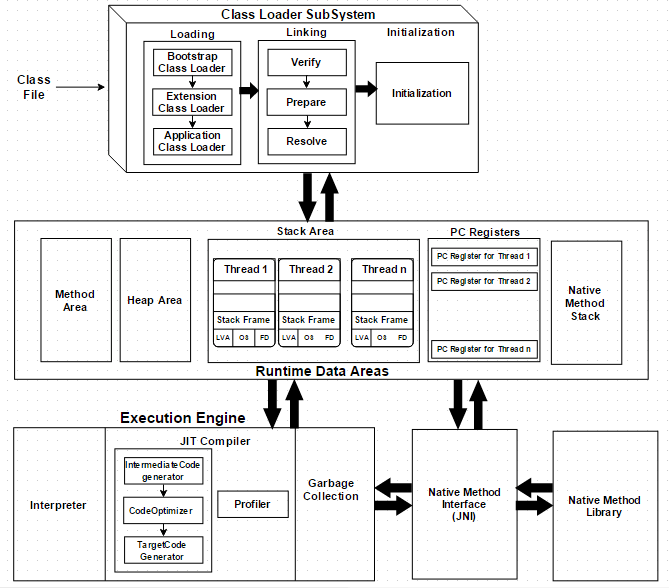
每个Java开发人员都知道字节码经由JRE(Java运行时环境)执行。但他们或许不知道JRE其实是由Java虚拟机(JVM)实现,JVM分析字节码,解释并执行它。作为开发人员,了解JVM的架构是非常重要的,因为它使我们能够编写出更高效的代码。本文中,我们将深入了解Java中的JVM架构和JVM的各个组件。JVM 虚拟机是物理机的软件 w397090770 8年前 (2017-01-01) 3620℃ 0评论12喜欢
今天我将介绍如何在Java工程使用Scala代码。对于那些想在真实场景中尝试使用Scala的开发人员来说,会非常有意思。这和你项目中有什么类型的东西毫无关系:不管是Spring还是Spark还是别的。我们废话少说,开始吧。抽象Java Maven项工程 这里我们使用Maven来管理我们的Java项目,项目的结果如下所示:如果想及时了解Spa w397090770 8年前 (2017-01-01) 9860℃ 0评论24喜欢
前言 如果你尝试使用Apache Log4J中的DailyRollingFileAppender来打印每天的日志,你可能想对那些日志文件指定一个最大的保存数,就像RollingFileAppender支持maxBackupIndex参数一样。不过遗憾的是,目前版本的Log4j (Apache log4j 1.2.17)无法在使用DailyRollingFileAppender的时候指定保存文件的个数,本文将介绍如何修改DailyRollingFileAppender类,使得它 w397090770 9年前 (2016-04-12) 5718℃ 0评论3喜欢
JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序、设备、系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。启动JMX监控,在启动java程序的时候最少需要在环境变量里面配置以下的选项:[code lang="bash"]-Dcom.sun.m w397090770 9年前 (2016-03-25) 6274℃ 0评论10喜欢