为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12544℃ 0评论34喜欢
本文来自徐宇辉(微信号:xuyuhui263)的投稿,目前在中国移动从事数字营销的业务支撑工作,感谢他的文章。Apache Flume简介Apache Flume是一个Apache的开源项目,是一个分布的、可靠的软件系统,主要目的是从大量的分散的数据源中收集、汇聚以及迁移大规模的日志数据,最后存储到一个集中式的数据系统中。Apache Flume是由 zz~~ 8年前 (2017-03-08) 7236℃ 0评论19喜欢
公安行业存在数以万计的前后端设备,前端设备包括相机、检测器及感应器,后端设备包括各级中心机房中的服务器、应用服务器、网络设备及机房动力系统,数量巨大、种类繁多的设备给公安内部运维管理带来了巨大挑战。传统通过ICMP/SNMP、Trap/Syslog等工具对设备进行诊断分析的方式已不能满足实际要求,由于公安内部运维管 w397090770 8年前 (2017-01-01) 11298℃ 1评论39喜欢
Apache Flume 1.7.0是自Flume成为Apache顶级项目的第十个版本。Apache Flume 1.7.0可以在生产环境下使用。Flume 1.7.0 User Guide下载Flume 1.7.0Flume 1.7.0 Developer GuideChanges[code lang="bash"]** New Feature[FLUME-2498] - Implement Taildir Source** Improvement[FLUME-1899] - Make SpoolDir work with Sub-Directories[FLUME-2526] - Build flume by jdk 7 in default[FLUME-2628] - Add an optiona w397090770 8年前 (2016-10-19) 3719℃ 0评论11喜欢
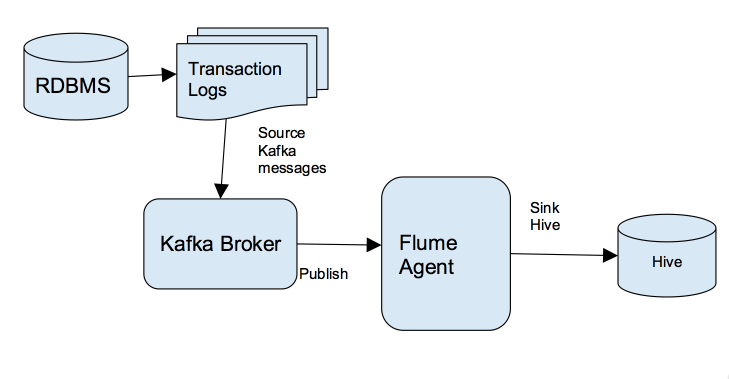
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 w397090770 9年前 (2016-08-30) 11512℃ 6评论26喜欢
本文出自本公众号ChinaScala,由陈超所述。一、Spark能否取代Hadoop? 答: Hadoop包含了Common,HDFS,YARN及MapReduce,Spark从来没说要取代Hadoop,最多也就是取代掉MapReduce。事实上现在Hadoop已经发展成为一个生态系统,并且Hadoop生态系统也接受更多优秀的框架进来,如Spark (Spark可以和HDFS无缝结合,并且可以很好的跑在YARN上).。 w397090770 10年前 (2015-08-26) 7209℃ 1评论42喜欢
默认情况下,Flume中的PollingPropertiesFileConfigurationProvider会每隔30秒去重新加载Flume agent的配置文件,如果监听到配置文件变化了,Flume会试图重新加载变化的配置文件。判断配置文件是否变化主要是基于文件的最后修改时间来的,代码片段如下:[code lang="java"]///////////////////////////////////////////////////////////////////// User: 过往记忆 w397090770 10年前 (2015-08-20) 6714℃ 0评论13喜欢
下面的大数据学习电子书我会陆续上传,敬请关注。一、Hadoop1、Hadoop Application Architectures2、Hadoop: The Definitive Guide, 4th Edition3、Hadoop Security Protecting Your Big Data Platform4、Field Guide to Hadoop An Introduction to Hadoop, Its Ecosystem, and Aligned Technologies5、Hadoop Operations A Guide for Developers and Administrators6、Hadoop Backup and Recovery Solutions w397090770 10年前 (2015-08-11) 20479℃ 2评论56喜欢
我们知道,Flume可以和许多的系统进行整合,包括了Hadoop、Spark、Kafka、Hbase等等;当然,强悍的Flume也是可以和Mysql进行整合,将分析好的日志存储到Mysql(当然,你也可以存放到pg、oracle等等关系型数据库)。 不过我这里想多说一些:Flume是分布式收集日志的系统;既然都分布式了,数据量应该很大,为什么你要将Flume分 w397090770 11年前 (2014-09-04) 25740℃ 21评论40喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 11年前 (2014-07-15) 92438℃ 0评论164喜欢