时隔两年,Apache Hadoop终于又有大改版,Apache基金会近日发布了Hadoop 2.8版,一次新增了2,919项更新功能或新特色。不过,Hadoop官网建议,2.8.0仍有少数功能在测试,要等到释出2.8.1或是2.8.2版才适合用于正式环境。在2.8.0版众多更新,主要分布于4大套件分别是:共用套件(Common)底层分散式档案系统HDFS套件(HDFS)MapReduce运算 w397090770 8年前 (2017-03-31) 2824℃ 2评论17喜欢
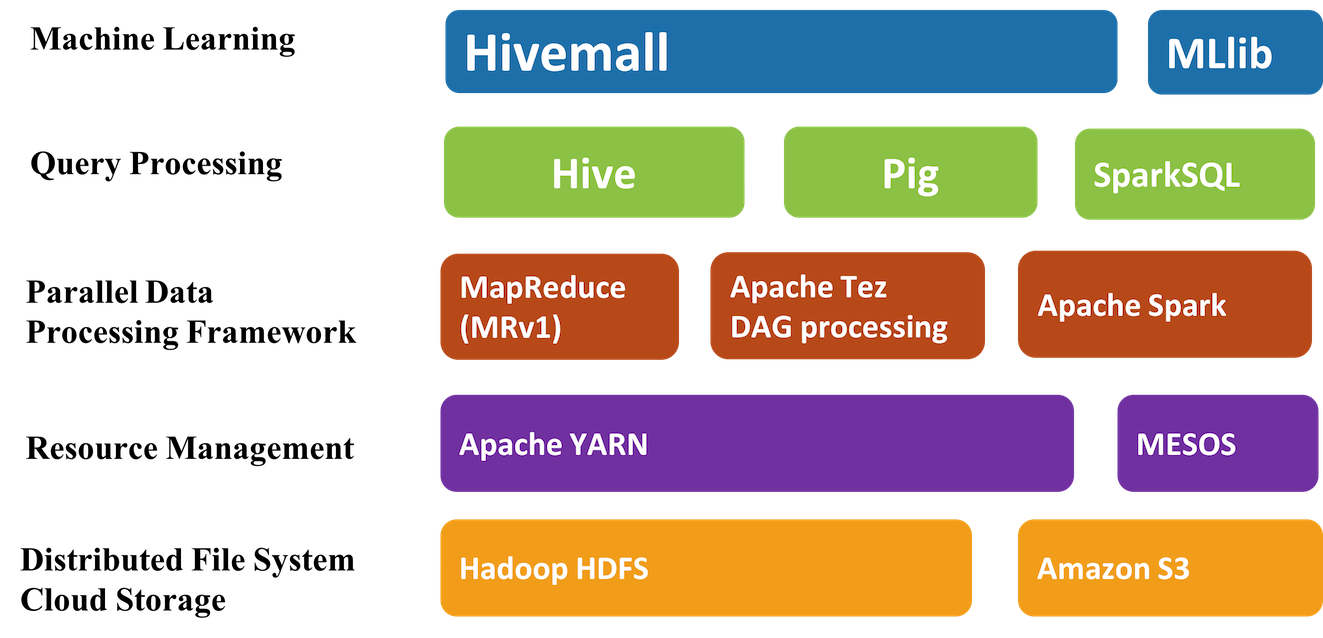
Apache Hivemall是机器学习算法(machine learning algorithms)和多功能数据分析函数(versatile data analytics functions)的集合,它通过Apache Hive UDF / UDAF / UDTF接口提供了一些易于使用的机器学习算法。Hivemall 最初由Treasure Data 开发的,并于2016年9月捐献给 Apache 软件基金会,进入了Apache 孵化器。 Apache Hivemall提供了各种功能包括:回归( w397090770 8年前 (2017-03-29) 3474℃ 1评论10喜欢
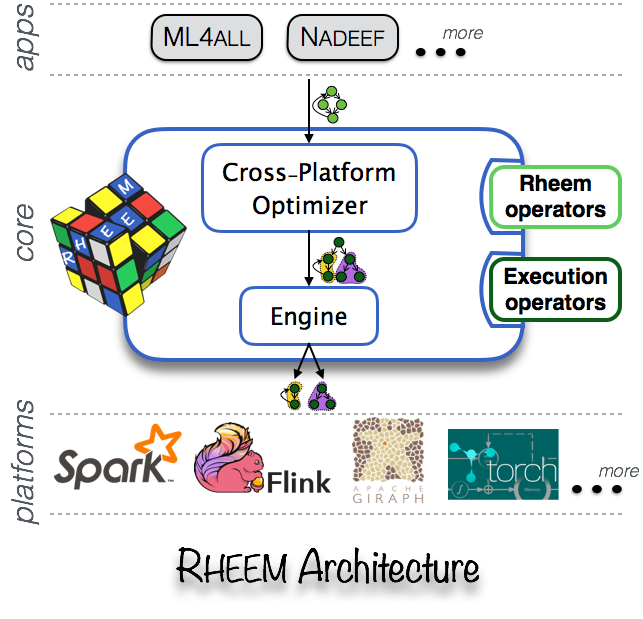
RHEEM是一个可扩展且易于使用的跨平台大数据分析系统,它在现有的数据处理平台之上提供了一个抽象。它允许用户使用易于使用的编程接口轻松地编写数据分析任务,为开发者提供了不同的方式进行性能优化,编写好的程序可以在任意数据处理平台上运行,这其中包括:PostgreSQL, Spark, Hadoop MapReduce或者Flink等;Rheem将选择经典 w397090770 8年前 (2017-03-23) 1057℃ 0评论3喜欢
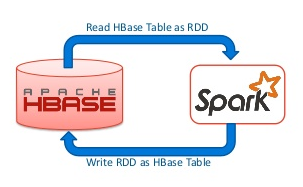
在使用Spark操作Hbase的时候,其返回的数据类型是RDD[ImmutableBytesWritable,Result],我们可能会对这个结果进行其他的操作,比如join等,但是因为org.apache.hadoop.hbase.io.ImmutableBytesWritable 和 org.apache.hadoop.hbase.client.Result 并没有实现 java.io.Serializable 接口,程序在运行的过程中可能发生以下的异常:[code lang="bash"]Serialization stack: - object not ser w397090770 8年前 (2017-03-23) 5425℃ 1评论13喜欢
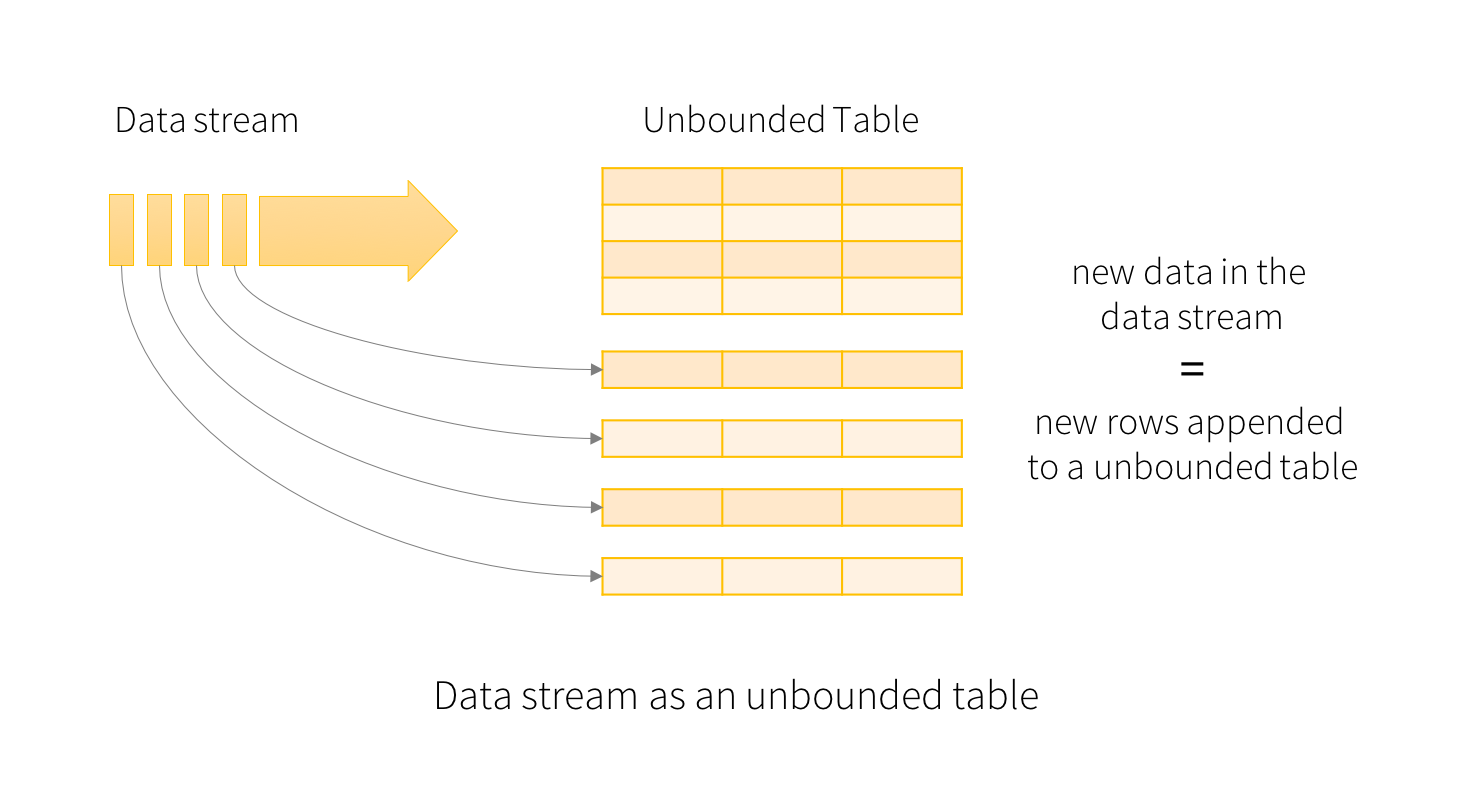
概览 Structured Streaming 是一个可拓展,容错的,基于Spark SQL执行引擎的流处理引擎。使用小量的静态数据模拟流处理。伴随流数据的到来,Spark SQL引擎会逐渐连续处理数据并且更新结果到最终的Table中。你可以在Spark SQL上引擎上使用DataSet/DataFrame API处理流数据的聚集,事件窗口,和流与批次的连接操作等。最后Structured Streaming zz~~ 8年前 (2017-03-22) 10783℃ 2评论11喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer 作业。比如下面的例子[code lang="bash"]mapred streaming \ -input myInputDirs \ -output myOutputDir \ -mapper /bin/cat \ -reducer /usr/bin/wc[/code]Hadoop Streaming程序是如何工作的Hadoop Streaming 使用了 Unix 的标准 w397090770 8年前 (2017-03-21) 10037℃ 0评论15喜欢
HDFS Federation为HDFS系统提供了NameNode横向扩容能力。然而作为一个已实现多年的解决方案,真正应用到已运行多年的大规模集群时依然存在不少的限制和问题。本文以实际应用场景出发,介绍了HDFS Federation在美团点评的实际应用经验。 背景 2015年10月,经过一段时间的优化与改进,美团点评HDFS集群稳定性和性能有显著 zz~~ 8年前 (2017-03-17) 2052℃ 0评论7喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer,从而充分利用 Hadoop 并行计算框架的优势和能力,来处理大数据。而我们在官方文档或者是Hadoop权威指南看到的Hadoop Streaming例子都是使用 Ruby 或者 Python 编写的,官方说可以使用任何可执行文件 w397090770 8年前 (2017-03-14) 2729℃ 0评论2喜欢
本文作者:李寅威,从事大数据、机器学习方面的工作,目前就职于CVTE联系方式:微信(coridc),邮箱(251469031@qq.com)原文链接: Spark2.1.0 + CarbonData1.0.0集群模式部署及使用入门1 引言 Apache CarbonData是一个面向大数据平台的基于索引的列式数据格式,由华为大数据团队贡献给Apache社区,目前最新版本是1.0.0版。介于 zz~~ 8年前 (2017-03-13) 3454℃ 0评论11喜欢
在Flink中有许多函数需要我们为其指定key,比如groupBy,Join中的where等。如果我们指定的Key不对,可能会出现一些问题,正如下面的程序:[code lang="scala"]package com.iteblog.flinkimport org.apache.flink.api.scala.{ExecutionEnvironment, _}import org.apache.flink.util.Collector///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2017 w397090770 8年前 (2017-03-13) 16902℃ 9评论15喜欢