大年初二Apache CarbonData迎来了第四个稳定版本CarbonData 1.0.0。CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。CarbonData 1.0.0版本,一共带来了80+ 个新特性,并且有100+ 个bugfi w397090770 8年前 (2017-01-29) 2809℃ 0评论6喜欢
近日,Intel开源了基于Apache Spark的分布式深度学习框架BigDL。有了BigDL之后,用户可以像编写标准的Spark程序一样来编写深度学习(deep learning)应用程序,编写完的程序还可以直接运行在现有的Spark或者Hadoop集群之上。BigDL主要有以下三大特点:[gt href="https://github.com/intel-analytics/BigDL "]BigDL GitHub地址[/gt]丰富的深度学习算法支 w397090770 8年前 (2017-01-19) 4468℃ 0评论14喜欢
Apache HBase 1.3.0于美国时间2017年01月17日正式发布。本版本是Hbase 1.x版本线的第三次小版本,大约解决了1700个issues,主要包括了大量的Bug修复和性能提升;其中以下的新特性值得关注:Date-based tiered compactions (HBASE-15181, HBASE-15339)Maven archetypes for HBase client applications (HBASE-14877)Throughput controller for flushes (HBASE-14969)Controlled delay (CoD w397090770 8年前 (2017-01-18) 3446℃ 0评论3喜欢
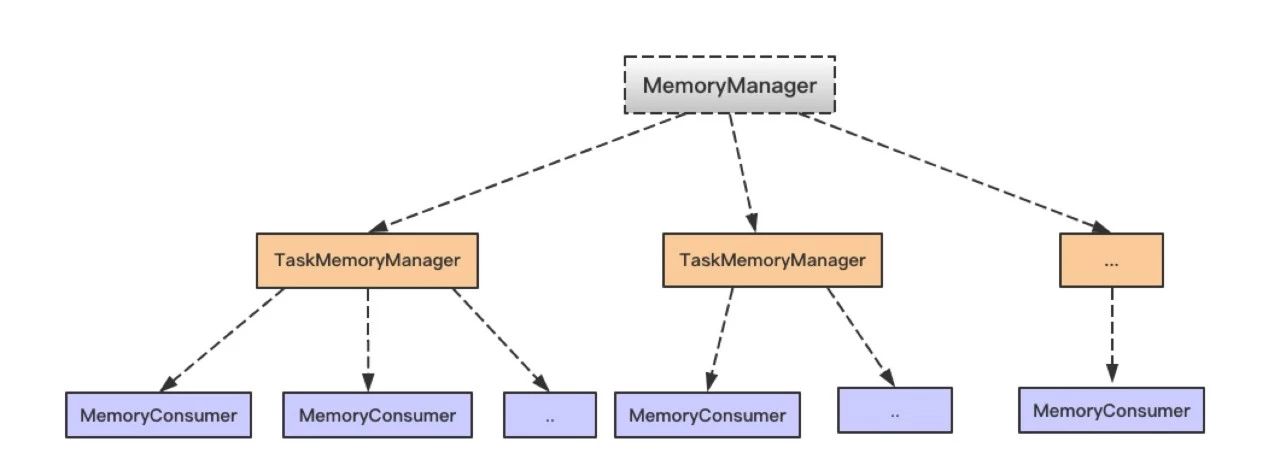
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 8年前 (2017-01-17) 828℃ 0评论1喜欢
好吧,有点标题党了!哈哈,这里介绍的Flink可查询状态提供的功能是有限的,不可能完全替换掉你的数据库(也可以说是持久化存储)。 我在《Apache Flink 1.2.0新功能概述》文章中简单介绍了即将发布的Apache Flink 1.2.0一些比较重要的新功能,其中就提到了Flink 1.2版本的两大重要特性:动态扩展(Dynamic Scaling)和可查询状 w397090770 8年前 (2017-01-15) 4901℃ 0评论4喜欢
Apache软件基金会在2017年01月10正式宣布Apache Beam从孵化项目毕业,成为Apache的顶级项目。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领 w397090770 8年前 (2017-01-12) 3179℃ 0评论7喜欢
我们都知道,当我们的页面请求一个js文件、一个cs文件或者点击到其他页面,浏览器一般都会给这些请求头加上表示来源的 Referrer 字段。Referrer 在分析用户的来源时非常有用,比如大家熟悉的百度统计里面就利用到 Referrer 信息了。但是遗憾的是,目前百度统计仅仅支持来源于http页面的referrer头信息;也就是说,如果你网站是ht w397090770 8年前 (2017-01-10) 24534℃ 0评论19喜欢
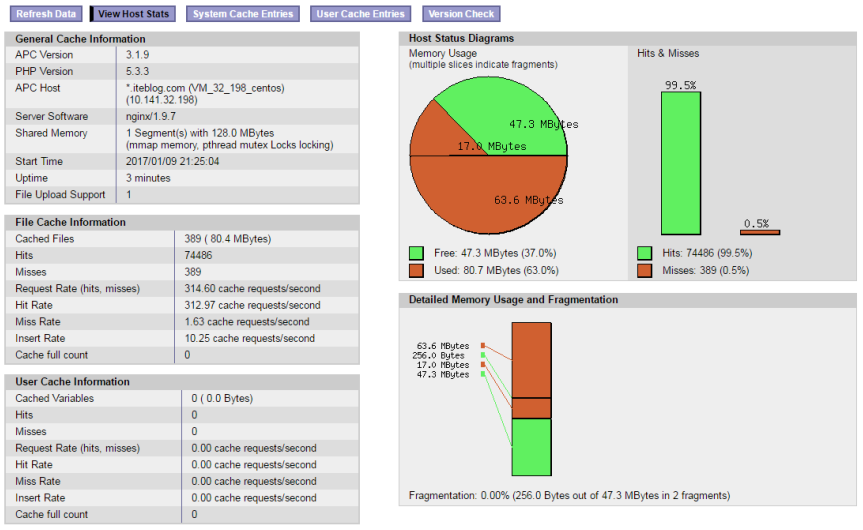
最近发现服务器php-fpm日志里面大量的Unable To Allocate Memory For Pool警告,如下:[code lang="bash"][09-Jan-2017 01:18:08] PHP Warning: require(): Unable to allocate memory for pool. in /data/web/iteblogbooks/wp-settings.php on line 220[09-Jan-2017 01:18:08] PHP Warning: require(): Unable to allocate memory for pool. in /data/web/iteblogbooks/wp-settings.php on line 221[09-Jan-2017 01:18:08] PHP Warning: re w397090770 8年前 (2017-01-09) 2188℃ 0评论4喜欢
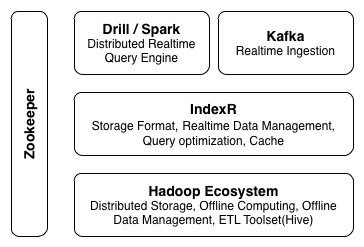
背景 舜飞科技的各个业务线对接全网的各大媒体及APP,从而产生大量数据,实时分析这些数据不仅仅用于监控业务的发展,还会影响产品的服务质量,直接创造价值。比如优化师要时刻关注活动的投放质量,竞价算法会根据投放数据实时调整策略,网站主会进行流量分析和快速事故反馈等等。这些分析需求的特点: 1 w397090770 8年前 (2017-01-03) 4629℃ 0评论6喜欢
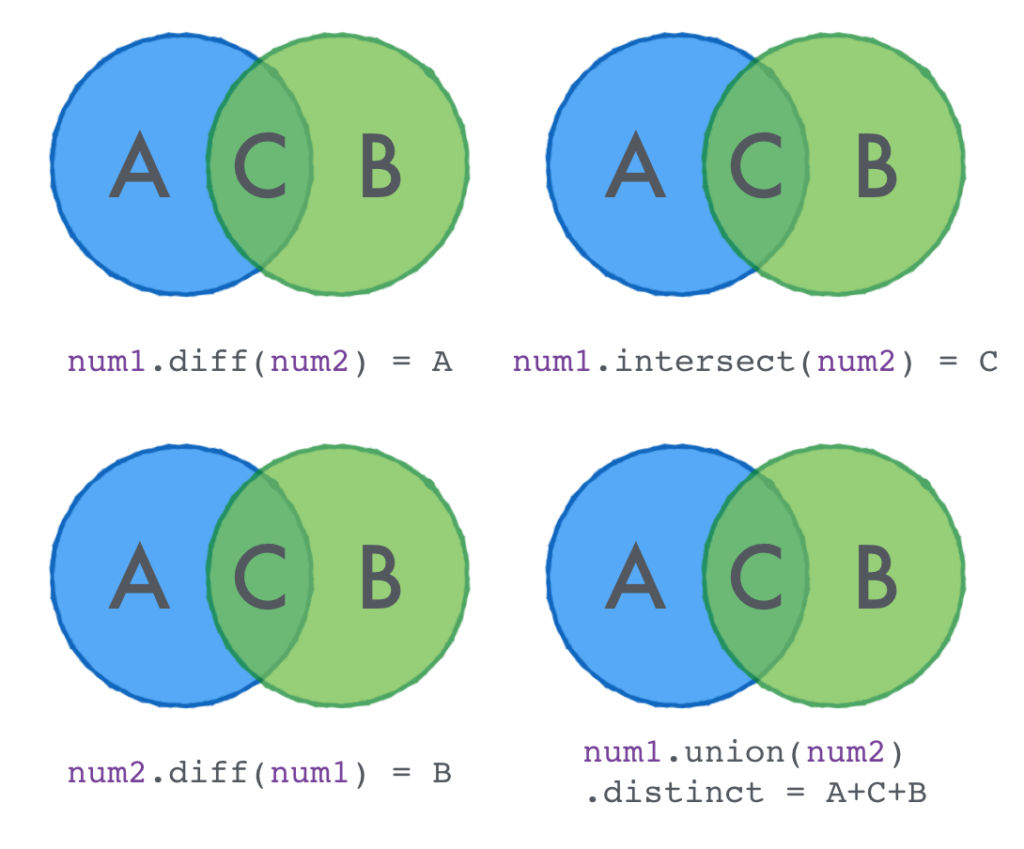
当我操作 Scala 集合时,我一般会进行两类操作:转换操作(transformation )和行动操作(actions)(有些人喜欢叫他为聚合操作)。第一种操作类型将集合转换为另一个集合,第二种操作类型返回某些类型的值。 本文我将集中介绍几个日常工作必备的 Scala 集合函数,如转换函数和聚合函数。文章最后,我会展示如何结合这 w397090770 8年前 (2017-01-02) 12332℃ 0评论45喜欢