本书将为您简要介绍ElasticSearch的基础知识以及Elasticsearch 5的新功能。通过本书将学习到Elasticsearch的基本功能和高级功能,例如查询,索引,搜索和修改数据。本书还介绍了一些高级知识,包括聚合,索引控制,分片,复制和聚类。中间部分介绍了ElasticSearch集群相关的知识,包括备份、监控、恢复等。读完本书,您将掌握Elastics zz~~ 8年前 (2017-02-28) 4980℃ 0评论13喜欢
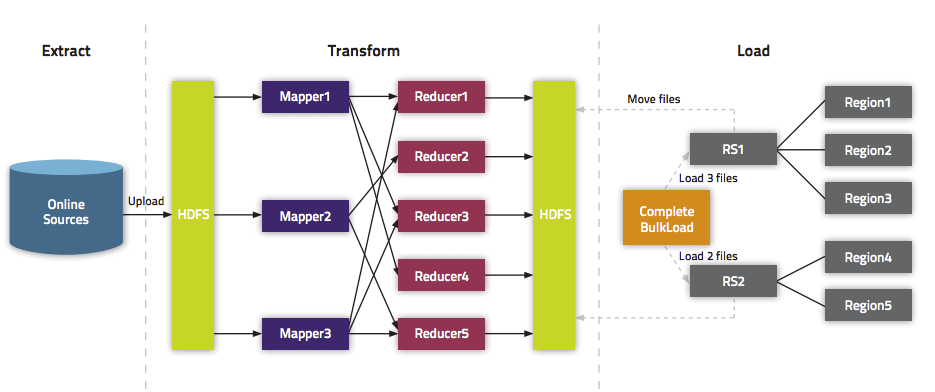
我们在《通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]》文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入数据到Hbase中的方法。这里将介绍两种方式:第一种使用Put普通的方法来倒数;第二种使用Bulk Load API。关于为啥需要使用Bulk Load本文就不介绍,更多的请参见《通过BulkLoad快 w397090770 8年前 (2017-02-28) 15134℃ 1评论40喜欢
Spark SQL从2.0开始已经不再支持ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)这种语法了(下文简称add columns语法)。如果你的Spark项目中用到了SparkSQL+Hive这种模式,从Spark1.x升级到2.x很有可能遇到这个问题。为了解决这个问题,我们一般有3种方案可以选择: 1、启动一个hiveserver2服务,通过jdbc直接调用hive w397090770 8年前 (2017-02-27) 3120℃ 0评论5喜欢
Angle Admin Template是一款后台管理模板,使用Bootstrap3.x作为界面框架,支持响应式布局。Angle包含JQuery和AngularJS两种js框架,方便SPA的使用,并且该模板提供了ASP.NET MVC、Angular、Rails等项目模板以及相应的种子模板,方便使用。点击下载Angle 3.5.4主题 该系列由于界面清爽,插件足够多、代码使用方便,文档齐全(英文), w397090770 8年前 (2017-02-25) 3237℃ 0评论16喜欢
Learning Apache Flink又名Mastering Apache Flink,是由Tanmay Deshpande所著,2017年02月在Packt出版,全书共280页。这本书是学习Apache Flink进行批处理和流数据处理的入门指南。本书首先介绍Apache Flink生态系统,然后介绍如何设置Apache Flink,并使用DataSet和DataStream API分别处理静态数据和流数据。本书将探讨如何在数据集上使用Table API。在本书的 zz~~ 8年前 (2017-02-24) 16340℃ 0评论19喜欢
在很多场景中我们会使用Shell命令来发送邮件,而且我们还可能在邮件里面添加附件,本文将介绍使用Shell命令发送带附件邮件的几种方式,希望对大家有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop使用mail命令mail命令是mailutils(On Debian)或mailx(On RedHat)包中的一部分,我们可以使 w397090770 8年前 (2017-02-23) 16413℃ 0评论12喜欢
Apache Kafka 0.10.2.0正式发布,此版本供修复超过200个bugs,合并超过500个 PR。本版本添加了一下的新功能: 1、支持session windows,参见KAFKA-3452 2、提供ProcessorContext中低层次Metrics的访问,参见KAFKA-3537 3、不用配置文件的情况下支持为 Kafka clients JAAS配置,参见KAFKA-4259 4、为Kafka Streams提供全局Table支持,参见KAFKA-4490 w397090770 8年前 (2017-02-23) 2611℃ 0评论1喜欢
最近,本博客由于流量增加,网站响应速度变慢,于是将全站页面全部静态化了;其中采取的方式主要是(1)、把所有https://www.iteblog.com/archives/\d{1,}全部跳转成https://www.iteblog.com/archives/\d{1,}.html,比如之前访问https://www.iteblog.com/archives/1983链接会自动跳转到https://www.iteblog.com/archives/1983.html;(2)、所有https://www.iteblog.com/page页 w397090770 8年前 (2017-02-22) 3783℃ 2评论9喜欢
我们可能会自己开发一些插件(比如微信公众号插件),在默认情况下,插件使用的URL很不友好,而且对SEO不好,比如我微信公众号的URL默认是 https://www.iteblog.com?iteblog_hadoop 。在Wordpress中,实现自己的rewrite rules方式有很多种,本文就是其中一种方法。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号 w397090770 8年前 (2017-02-22) 4409℃ 0评论7喜欢
我们在使用Hive的时候肯定遇到过建立了一张分区表,然后手动(比如使用 cp 或者 mv )将分区数据拷贝到刚刚新建的表作为数据初始化的手段;但是对于分区表我们需要在hive里面手动将刚刚初始化的数据分区加入到hive里面,这样才能供我们查询使用,我们一般会想到使用 alter table add partition 命令手动添加分区,但是如果初始化 w397090770 8年前 (2017-02-21) 16492℃ 0评论31喜欢

![[电子书]Mastering Elasticsearch 5.x - Third Edition PDF下载](https://www.iteblog.com/pic/elastic/Mastering_Elasticsearch_5.x-Third_Edition_iteblog.jpg)

![[电子书]Learning Apache Flink PDF下载](https://www.iteblog.com/pic/flink/Mastering_Apache_Flink_iteblog.png)

