Apache Kafka 近期发布了 2.3.0 版本,主要的新特性如下:Kafka Connect REST API 已经有了一些改进。Kafka Connect 现在支持增量协同重新均衡(incremental cooperative rebalancing)Kafka Streams 现在支持内存会话存储和窗口存储;AdminClient 现在允许用户确定他们有权对主题执行哪些操作;broker 增加了一个新的启动时间指标;JMXTool现在可以连接到安 w397090770 6年前 (2019-06-27) 3075℃ 0评论6喜欢
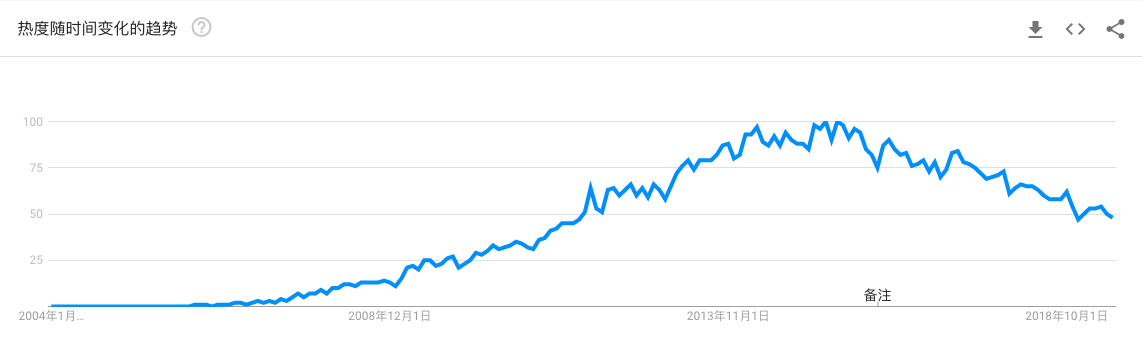
Hadoop我先从一个悲观的观点说起:Hadoop 正在迅速失去市场,我们可以从 Google 趋势走向看出这个现象:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop下面的炒作生命周期表也上面的趋势很类似:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop看起来 Hadoo w397090770 6年前 (2019-06-23) 3687℃ 0评论32喜欢
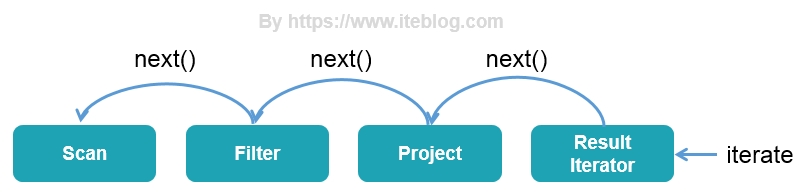
终于到最后一篇了,我们在前面两篇文章中《一条 SQL 在 Apache Spark 之旅(上)》 和 《一条 SQL 在 Apache Spark 之旅(中)》 介绍了 Spark SQL 之旅的 SQL 解析、逻辑计划绑定、逻辑计划优化以及物理计划生成阶段,本文我们将继续接上文,介绍 Spark SQL 的全阶段代码生成以及最后的执行过程。全阶段代码生成阶段 - WholeStageCodegen前面 w397090770 6年前 (2019-06-19) 9092℃ 0评论17喜欢
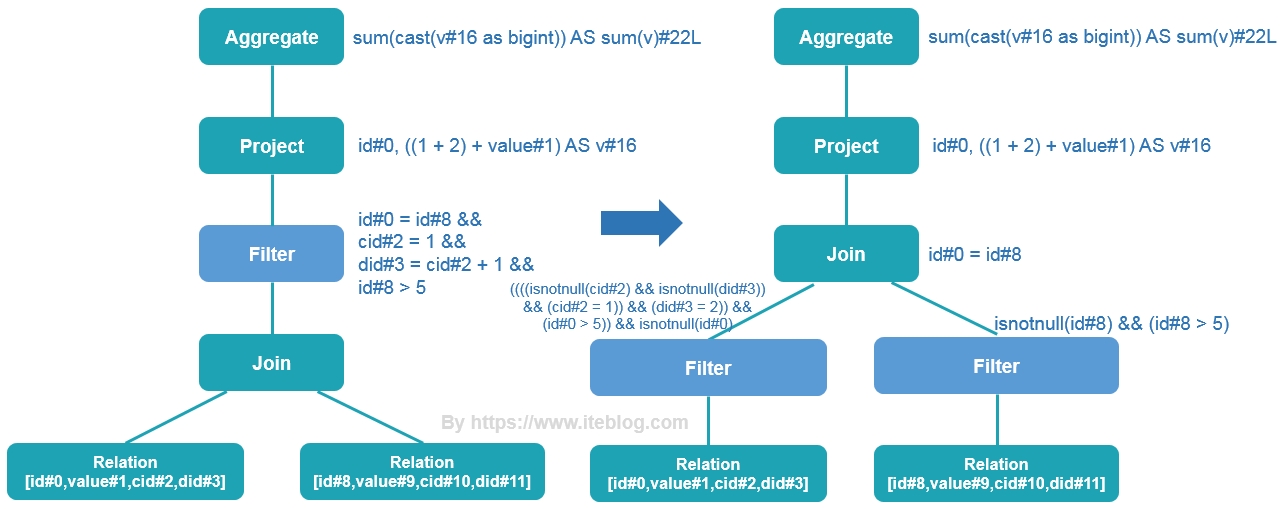
在 《一条 SQL 在 Apache Spark 之旅(上)》 文章中我们介绍了一条 SQL 在 Apache Spark 之旅的 Parser 和 Analyzer 两个过程,本文接上文继续介绍。优化逻辑计划阶段 - Optimizer在前文的绑定逻辑计划阶段对 Unresolved LogicalPlan 进行相关 transform 操作得到了 Analyzed Logical Plan,这个 Analyzed Logical Plan 是可以直接转换成 Physical Plan 然后在 Spark 中执 w397090770 6年前 (2019-06-18) 5723℃ 4评论21喜欢
大家肯定都知道要想在国内下载一个项目到本地速度太慢了。可以试试下面方案,把原地址:https://github.com/xxx.git 替换为:https://github.com.cnpmjs.org/xxx.git 即可。比如我们要克隆下面项目到本地,可以操作如下:[code lang="bash"][root@iteblog.com ~]$ git clone https://github.com.cnpmjs.org/397090770/web正克隆到 'web'...Username for 'https://github.com.cnpmjs.org w397090770 6年前 (2019-06-14) 973℃ 0评论1喜欢
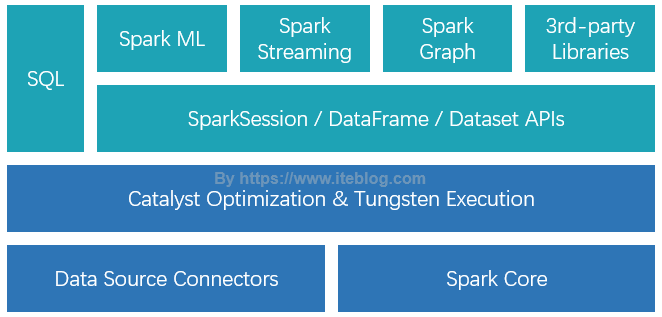
Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询和 DataFrame DSL。通过引入了 SQL 的支持,大大降低了开发人员的学习和使用成本。目前,整个 SQL 、Spark ML、Spark Graph 以及 Structured Streaming 都是运行在 Catalyst Optimization & Tungsten Execution 之上的,如下图所示:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关 w397090770 6年前 (2019-06-12) 10917℃ 0评论31喜欢
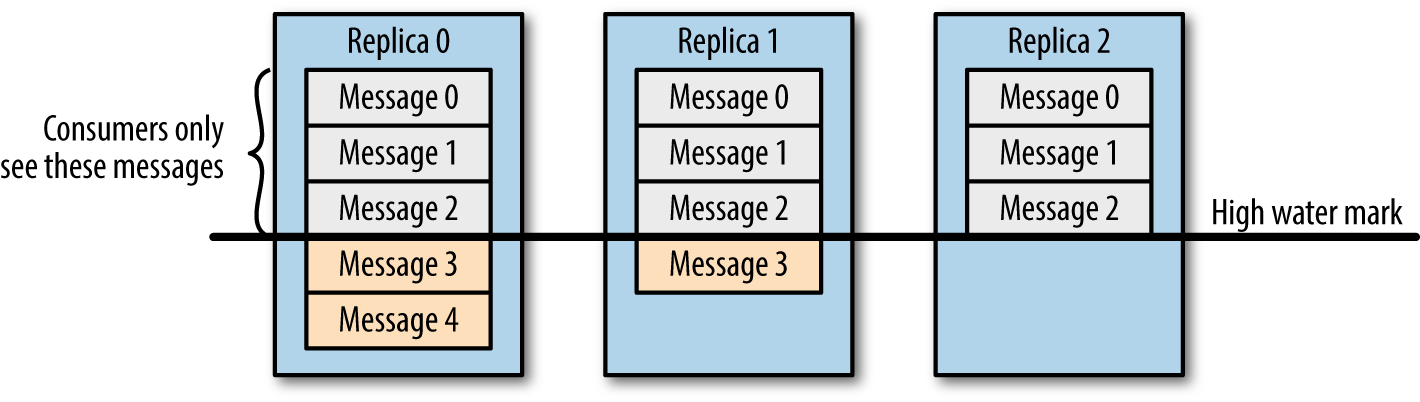
学过大数据的同学应该都知道 Kafka,它是分布式消息订阅系统,有非常好的横向扩展性,可实时存储海量数据,是流数据处理中间件的事实标准。本文将介绍 Kafka 是如何保证数据可靠性和一致性的。数据可靠性Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本文从 Producter 往 Broker 发送消息、Topic 分区副本以及 w397090770 6年前 (2019-06-11) 12903℃ 2评论42喜欢
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 6年前 (2019-06-06) 3281℃ 0评论8喜欢