本文将介绍使用Spark batch作业处理存储于Hive中Twitter数据的一些实用技巧。首先我们需要引入一些依赖包,参考如下:[code lang="scala"]name := "Sentiment"version := "1.0"scalaVersion := "2.10.6"assemblyJarName in assembly := "sentiment.jar"libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.6.0&qu zz~~ 9年前 (2016-08-31) 3338℃ 0评论5喜欢
rest 接口 现在我们已经有一个正常运行的节点(和集群),下一步就是要去理解怎样与其通信。幸运的是,Elasticsearch提供了非常全面和强大的REST API,利用这个REST API你可以同你的集群交互。下面是利用这个API,可以做的几件事情: 1、查你的集群、节点和索引的健康状态和各种统计信息 2、管理你的集群、节点、 zz~~ 9年前 (2016-08-31) 1440℃ 0评论2喜欢
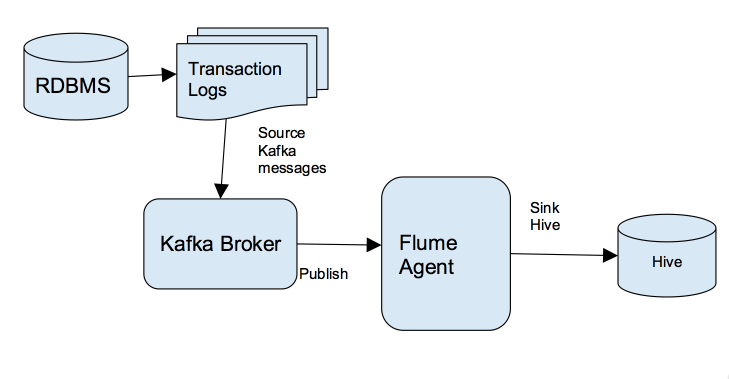
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 w397090770 9年前 (2016-08-30) 11512℃ 6评论26喜欢
Elasticsearch最少需要Java 7版本,在本文写作时,推荐使用Oracle JDK 1.8.0_73版本。Java的安装和平台有关,所以本文并不打算介绍如何在各个平台上安装Java。在你安装ElasticSearch之前,先运行以下的命令检查你Java的版本:[code lang="java"]java -versionecho $JAVA_HOME[/code] 一旦我们将 Java 安装完成, 我们就可以下载并安装 Elasticsearch w397090770 9年前 (2016-08-29) 1553℃ 0评论1喜欢
在Elasticsearch下,一个文档除了有数据之外,它还包含了元数据(Metadata)。每创建一条数据时,都会对元数据进行写入等操作,当然有些元数据是在创建mapping的时候就会设置,元数据在Elasticsearch下起到了非常大的作用。本文将对ElasticSearch中的元数据进行介绍,后续文章将分别对这些元数据进行解说。身份元数据(Identity meta-field w397090770 9年前 (2016-08-28) 4563℃ 0评论4喜欢
最近在一个项目中使用到Play的Json相关的类库,看名字就知道这是和Json打交道的类库。其可以很方面地将class转换成Json字符串;也可以将Json字符串转换成一个类。一般的转换直接看Play的相关文档即可很容易的搞定,将class转换成Json字符串直接写个Writes即可;而将Json字符串转换成一个类直接写个Reads即可。所有的操作只需要引入 w397090770 9年前 (2016-08-27) 3277℃ 0评论14喜欢
1、Hive内部表和外部表的区别? 1、在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而表则不一样; 2、在删除表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的! 那么, w397090770 9年前 (2016-08-26) 5661℃ 2评论20喜欢
一. 问答题1) datanode在什么情况下不会备份?2) hdfs的体系结构?3) sqoop在导入数据到mysql时,如何让数据不重复导入?如果存在数据问题sqoop如何处理?4) 请列举曾经修改过的/etc下的配置文件,并说明修改要解决的问题?5) 描述一下hadoop中,有哪些地方使用了缓存机制,作用分别是什么?二. 计算题1、使用Hive或 w397090770 9年前 (2016-08-26) 4281℃ 1评论4喜欢
一. 问答题1. 用mapreduce实现sql语句select count(x) from a group by b?2. 简述MapReduce大致流程,map -> shuffle -> reduce3. HDFS如何定位replica4. Hadoop参数调优: cluster level: JVM, map/reduce slots, job level: reducer, memory, use combiner? use compression?5. hadoop运行的原理?6. mapreduce的原理?7. HDFS存储的机制?8. 如何确认Hadoop集群的健康状况? w397090770 9年前 (2016-08-26) 3403℃ 0评论3喜欢
一. 问答题1.hive如何调优?2.hive如何权限控制?3.hbase写数据的原理是什么?4.hive能像关系数据库那样,建多个库吗?5.hbase宕机如何处理?6.hive实现统计的查询语句是什么?7.生产环境中为什么建议使用外部表?8.hadoop mapreduce创建类DataWritable的作用是什么?9.为什么创建类DataWritable?二. 思考题1.假 w397090770 9年前 (2016-08-26) 3534℃ 0评论5喜欢




![Play JSON类库将List[(String, String)]转换成Json字符串](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/4.jpg)


