本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》、《Hadoop从入门到上手企业开发视 w397090770 10年前 (2015-02-28) 96715℃ 381评论279喜欢
相关图标矢量字库:《Font Awesome:图标字体》、《阿里巴巴矢量图标库:Iconfont》 Iconfont.cn是由阿里巴巴UX部门推出的矢量图标管理网站,也是国内首家推广Webfont形式图标的平台。网站涵盖了1000多个常用图标并还在持续更新中(目前加上用户上传的图标近70000个,我们可以通过搜索来找到他们。)。、 Iconfont平台为用 w397090770 10年前 (2015-02-26) 29735℃ 0评论27喜欢
基本格式f1 f2 f3 f4 f5 program分 时 日 月 周 命令 第1列表示分钟1~59每分钟用*或者 */1表示;第2列表示小时1~23(0表示0点);第3列表示日期1~31;第4列表示月份1~12;第5列标识号星期0~6(0表示星期天);第6列要运行的命令 当 f1 为 * 时表示每分钟都要执行 program,f2 为* 时表示每小时都要执行程序, w397090770 10年前 (2015-02-22) 3944℃ 0评论7喜欢
我们先来看看aggregate函数的官方文档定义:Aggregate the elements of each partition, and then the results for all the partitions, using given combine functions and a neutral "zero value". This function can return a different result type, U, than the type of this RDD, T. Thus, we need one operation for merging a T into an U and one operation for merging two U's, as in scala.TraversableOnce. Both of these functions w397090770 10年前 (2015-02-12) 37449℃ 5评论23喜欢
Learning Spark这本书链接是完整版,和之前的预览版是不一样的,我不是标题党。这里提供的Learning Spark电子书格式是mobi、pdf以及epub三种格式的文件,如果你有亚马逊Kindle电子书阅读器,是可以直接阅读mobi、pdf。但如果你用电脑,也可以下载相应的PC版阅读器 。如果你需要阅读器,可以找我。如果想及时了解Spark、Hadoop或者Hbase相 w397090770 10年前 (2015-02-11) 50946℃ 305评论70喜欢
美国时间2015年2月09日Spark 1.2.1正式发布了,邮件如下:Hi All,I've just posted the 1.2.1 maintenance release of Apache Spark. We recommend all 1.2.0 users upgrade to this release, as this release includes stability fixes across all components of Spark.- Download this release: http://spark.apache.org/downloads.html- View the release notes: http://spark.apache.org/releases/spark-release-1-2-1.html- w397090770 10年前 (2015-02-10) 3497℃ 0评论2喜欢
美国时间2015年2月4日,Hive 1.0.0正式发布了。该版本是Apache Hive九年来工作的认可,并且开发者们正在继续开发。Apache Hive 1.0.0版本本来是要命名为Hive 0.14.1的,但是社区感觉是时候以1.x.y结构来命名。 虽然被叫做1.0.0版本,但是其中的改变范围很少,主要有两个改变:1、开始为HiveMetaStoreClient定义公开的API(HIVE-3280);2、HiveServ w397090770 10年前 (2015-02-06) 7110℃ 0评论3喜欢
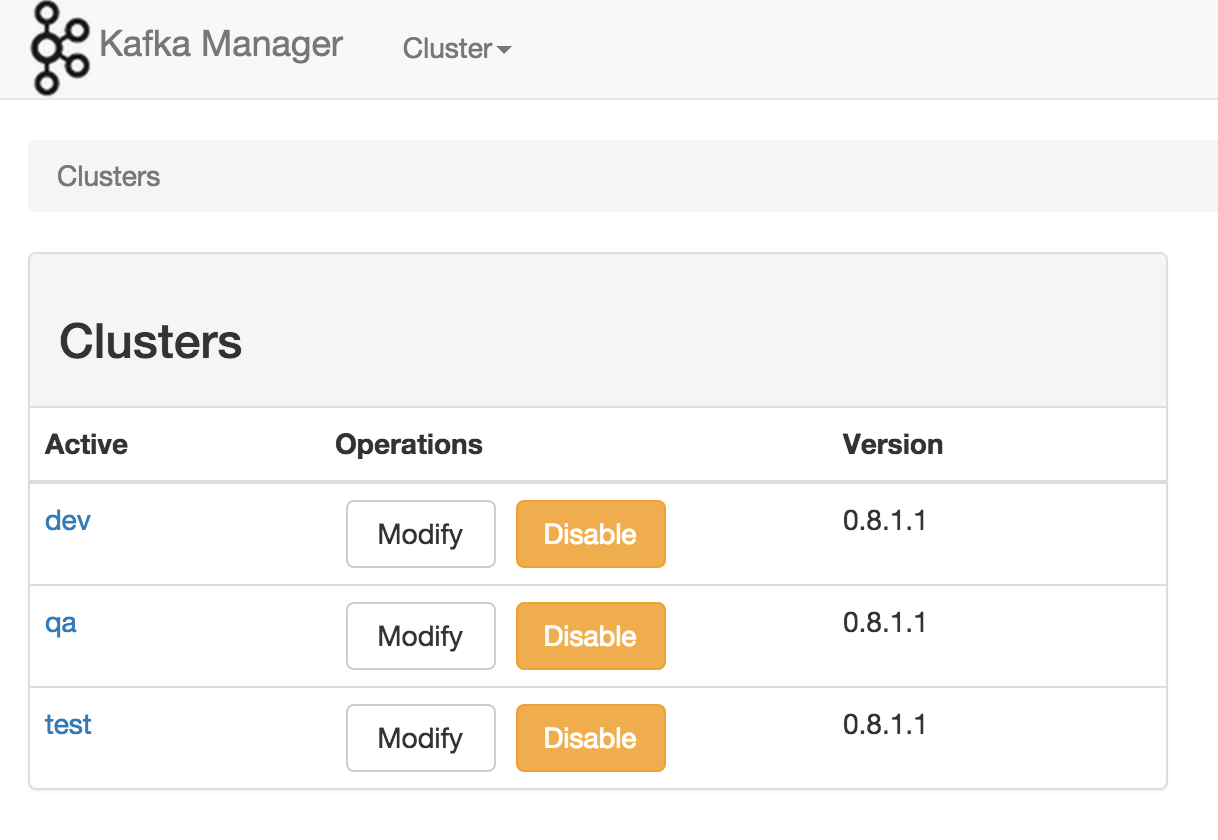
《Apache Kafka监控之Kafka Web Console》《Apache Kafka监控之KafkaOffsetMonitor》《雅虎开源的Kafka集群管理器(Kafka Manager)》Kafka在雅虎内部被很多团队使用,媒体团队用它做实时分析流水线,可以处理高达20Gbps(压缩数据)的峰值带宽。为了简化开发者和服务工程师维护Kafka集群的工作,构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka M w397090770 10年前 (2015-02-04) 22105℃ 0评论14喜欢
在这篇文章中,我将介绍一下Spark SQL对Json的支持,这个特性是Databricks的开发者们的努力结果,它的目的就是在Spark中使得查询和创建JSON数据变得非常地简单。随着WEB和手机应用的流行,JSON格式的数据已经是WEB Service API之间通信以及数据的长期保存的事实上的标准格式了。但是使用现有的工具,用户常常需要开发出复杂的程序 w397090770 10年前 (2015-02-04) 14405℃ 1评论16喜欢
目前的Spark RDD只提供了一个基于迭代器(iterator-based)、批量更新(bulk-updatable)的接口。但是在很多场景下,我们需要扫描部分RDD便可以查找到我们要的数据,而当前的RDD设计必须扫描全部的分区(partition )。如果你需要更新某个数据,你需要复制整个RDD!那么为了解决这方面的问题,Spark开发团队正在设计一种新的RDD:IndexedRDD。它是 w397090770 10年前 (2015-02-02) 6826℃ 0评论7喜欢

![Hadoop从入门到上手企业开发视频下载[70集]](https://www.iteblog.com/pic/iteblog.png)