
《Apache Kafka监控之Kafka Web Console》
《Apache Kafka监控之KafkaOffsetMonitor》
《雅虎开源的Kafka集群管理器(Kafka Manager)》
《Apache Kafka监控之KafkaOffsetMonitor》
《雅虎开源的Kafka集群管理器(Kafka Manager)》
Kafka在雅虎内部被很多团队使用,媒体团队用它做实时分析流水线,可以处理高达20Gbps(压缩数据)的峰值带宽。
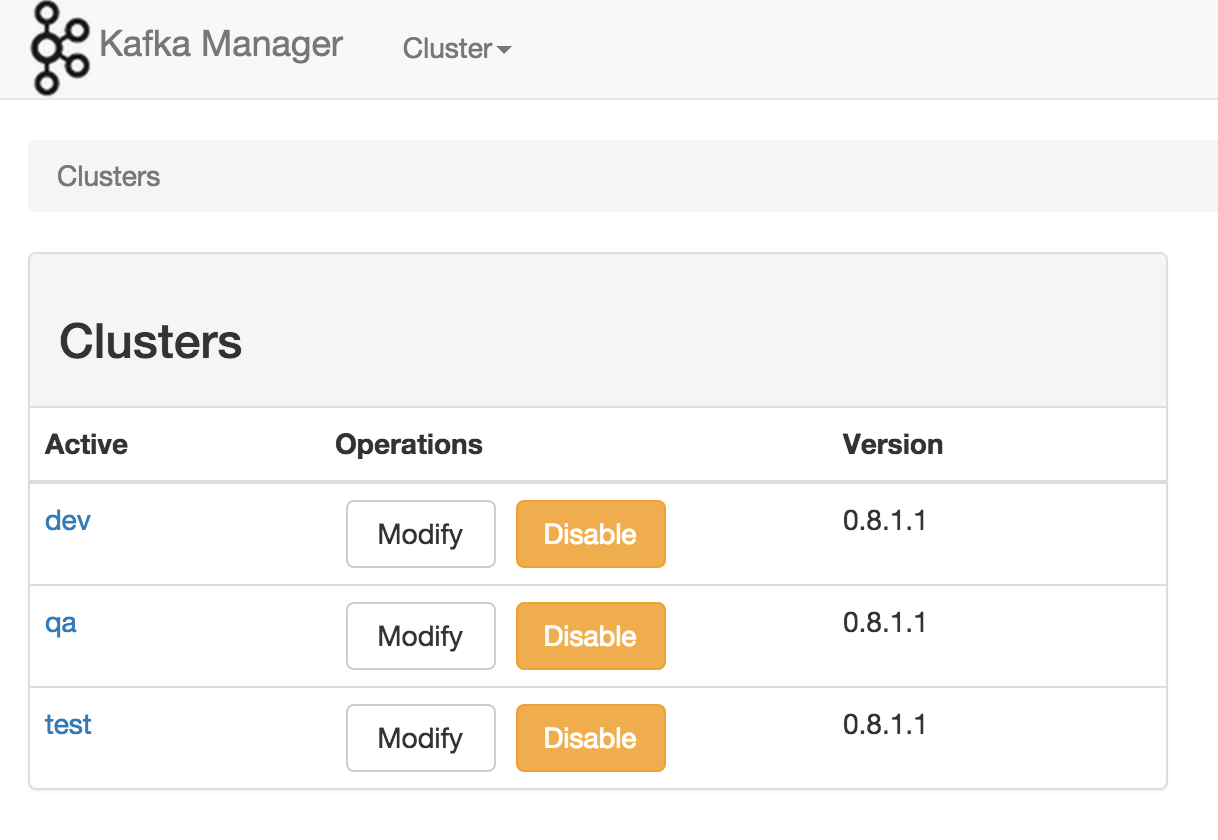
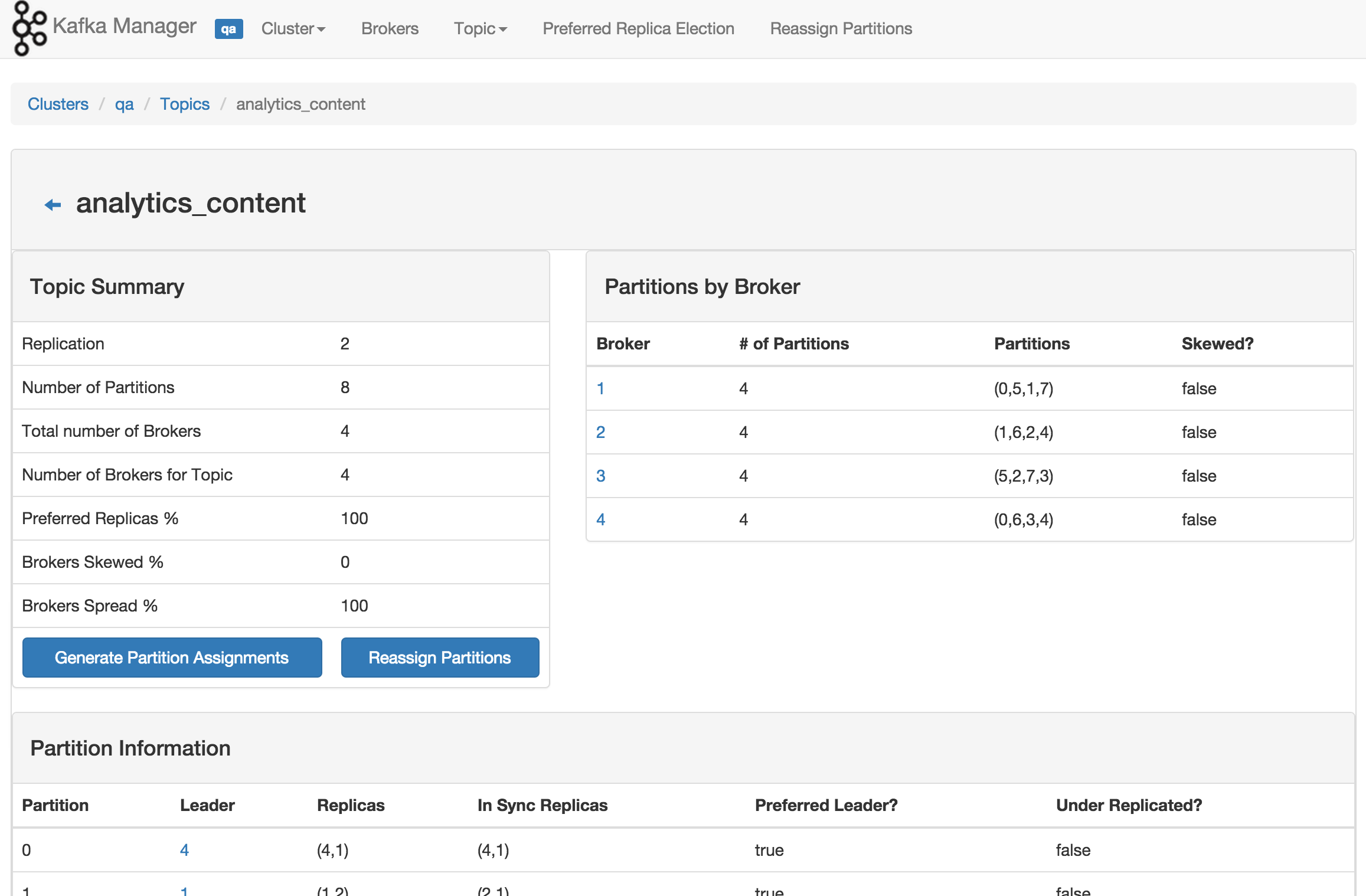
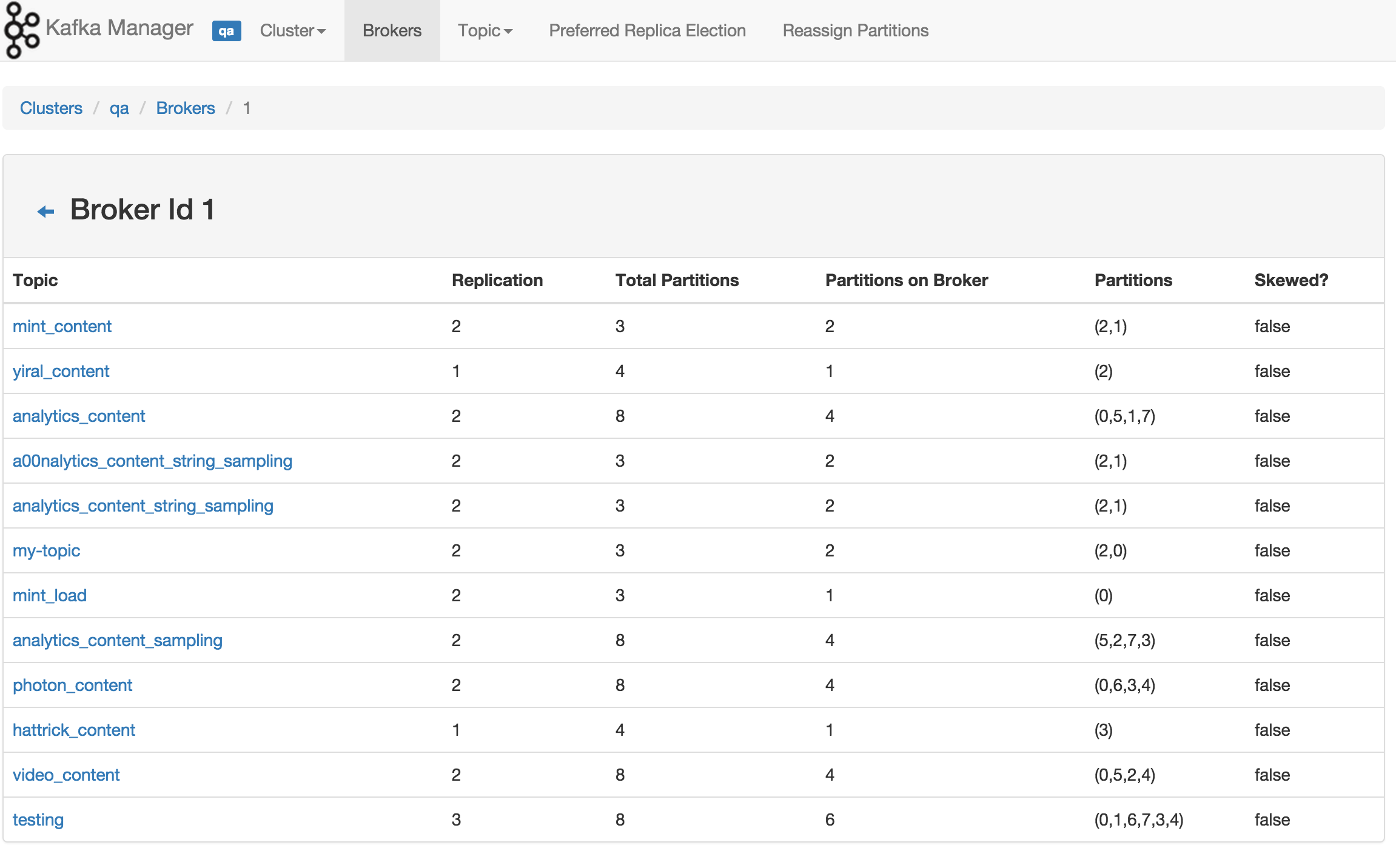
为了简化开发者和服务工程师维护Kafka集群的工作,构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka Manager。这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具。
该软件是用Scala语言编写的。目前(2015年02月03日)雅虎已经开源了Kafka Manager工具。这款Kafka集群管理工具主要支持以下几个功能:
- 管理几个不同的集群;
- 很容易地检查集群的状态(topics, brokers, 副本的分布, 分区的分布);
- 选择副本;
- 产生分区分配(Generate partition assignments)基于集群的当前状态;
- 重新分配分区。
以下是该集群管理工具的截图:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
该软件安装需要条件如下:
- Kafka 0.8.1.1或 0.8.2-beta
- sbt 0.13.x
- Java 7+
系统配置
系统最少需要配置zookeeper集群的地址,可以在kafka-manager安装包的conf目录下面的application.conf文件中进行配置。例如:
/** * User: 过往记忆 * Date: 15-02-05 * Time: 上午02:30 * bolg: https://www.iteblog.com * 本文地址:https://www.iteblog.com/archives/1264 * 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量的干货 * 过往记忆博客微信公共帐号:iteblog_hadoop */ kafka-manager.zkhosts="www.iteblog.com:2181"
部署kafka manager
下面的命令可以创建一个zip压缩包,而这个压缩包可以用来部署该应用:
/** * User: 过往记忆 * Date: 15-02-05 * Time: 上午02:30 * bolg: https://www.iteblog.com * 本文地址:https://www.iteblog.com/archives/1264 * 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量的干货 * 过往记忆博客微信公共帐号:iteblog_hadoop */ sbt clean dist
生成环境的部署情况可以查看play framework 的官方文档。github下载地址请看这里:
点击这下载该项目源码
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【雅虎开源的Kafka集群管理器(Kafka Manager)】(https://www.iteblog.com/archives/1264.html)




