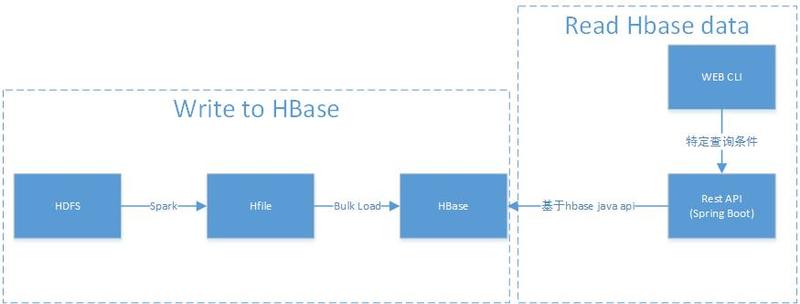
背景介绍本项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询。原实现基于 Oracle 提供存储查询服务,随着数据量的不断增加,在写入和读取过程中面临性能问题,且历史数据仅供业务查询参考,并不影响实际流程,从系统结构上来说,放在业务链条上游比较重。 w397090770 7年前 (2017-10-28) 2719℃ 0评论7喜欢
MMLSpark为Apache Spark提供了大量深度学习和数据科学工具,包括将Spark Machine Learning管道与Microsoft Cognitive Toolkit(CNTK)和OpenCV进行无缝集成,使您能够快速创建功能强大,高度可扩展的大型图像和文本数据集分析预测模型。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopMMLSpark需要Scala 2.11,Spark 2 w397090770 7年前 (2017-10-24) 4231℃ 0评论9喜欢
这次整理的PPT来自于2017年09月11日至13日在 Berlin 进行的 Flink forward 会议,这种性质的会议和大家熟知的 Spark summit 类似。本次会议的官方日程参见:https://berlin-2017.flink-forward.org/kb_day/day-1/。因为原始的PPT是在 http://www.slideshare.net/ 网站,这个网站需要翻墙;为了学习交流的方便,这里收集了本次会议所有课下载的PPT(共45个),希望对 zz~~ 7年前 (2017-10-18) 2730℃ 0评论18喜欢
本书书名全名:Learning Spark Streaming:Best Practices for Scaling and Optimizing Apache Spark,于2017-06由 O'Reilly Media出版,作者 Francois Garillot, Gerard Maas,全书300页。本文提供的是本书的预览版。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Understand how Spark Streaming fits in the big pictureLearn c zz~~ 7年前 (2017-10-18) 6484℃ 0评论21喜欢
就在前几天,Apache Hadoop 3.0.0-beta1 正式发布了,这是3.0.0的第一个 beta 版本。本版本基于 3.0.0-alpha4 版本进行了Bug修复、性能提升以及其他一些加强。好消息是,这个版本之后会正式发行 Apache Hadoop 3.3.0 GA(General Availability,正式发布的版本)版本,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!目前预计 Apache Hadoop 3.3.0 GA 将会在 201 w397090770 7年前 (2017-10-11) 2257℃ 0评论15喜欢



![[电子书]Learning Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Spark_Streaming_iteblog.jpg)
