最近突然收到线上服务器发出来的磁盘满了的报警,然后到服务器上发现 Apache Spark 的历史服务器(HistoryServer)日志居然占了近 500GB,如下所示:[code lang="bash"][root@iteblog.com spark]# ll -htotal 328-rw-rw-r-- 1 spark spark 15.4G Jul 11 13:09 spark-spark-org.apache.spark.deploy.history.HistoryServer-1-iteblog.com.out-rw-rw-r-- 1 spark spark 369M May 30 09:07 spark-spark-org.a w397090770 6年前 (2018-10-29) 2234℃ 0评论2喜欢
本文来自于2018年10月20日由中国 HBase 技术社区在武汉举办的中国 HBase Meetup 第六次线下交流会。分享者为过往记忆。本文 PPT 下载 请关注 iteblog_hadoop 微信公众号,并回复 HBase 获取。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop本次分享的内容主要分为以下五点:HBase基本知识;HBase读 w397090770 6年前 (2018-10-25) 6433℃ 0评论23喜欢
Alluxio Meetup 上海站由 Alluxio、七牛主办,示说网、过往记忆协办,本次会议将于2018年10月27日 13:30-17:00 在上海市张江高科博霞路66号浦东软件园Q座举行。报名地址扫描下面二维码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动详情Alluxio:未来是数据的时代,数据的高效管理、存储 w397090770 6年前 (2018-10-17) 1316℃ 0评论1喜欢
为期三天的 Spark+AI Summit Europe 于 2018-10-02 ~ 04 在伦敦举行,一如往前,本次会议包含大量 AI 相关的议题,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark+AI Summit Europe 2018 吸引了全球大量技术大咖参会,本次会议议题超过了140多个。会议的全部日程请参见:https://databricks.com/sparkaisummit/europe/schedule。注意 w397090770 6年前 (2018-10-13) 3512℃ 1评论8喜欢
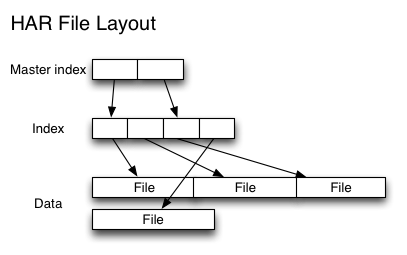
我们知道,HDFS 被设计成存储大规模的数据集,我们可以在 HDFS 上存储 TB 甚至 PB 级别的海量数据。而这些数据的元数据(比如文件由哪些块组成、这些块分别存储在哪些节点上)全部都是由 NameNode 节点维护,为了达到高效的访问, NameNode 在启动的时候会将这些元数据全部加载到内存中。而 HDFS 中的每一个文件、目录以及文件块, w397090770 6年前 (2018-10-09) 9382℃ 2评论31喜欢
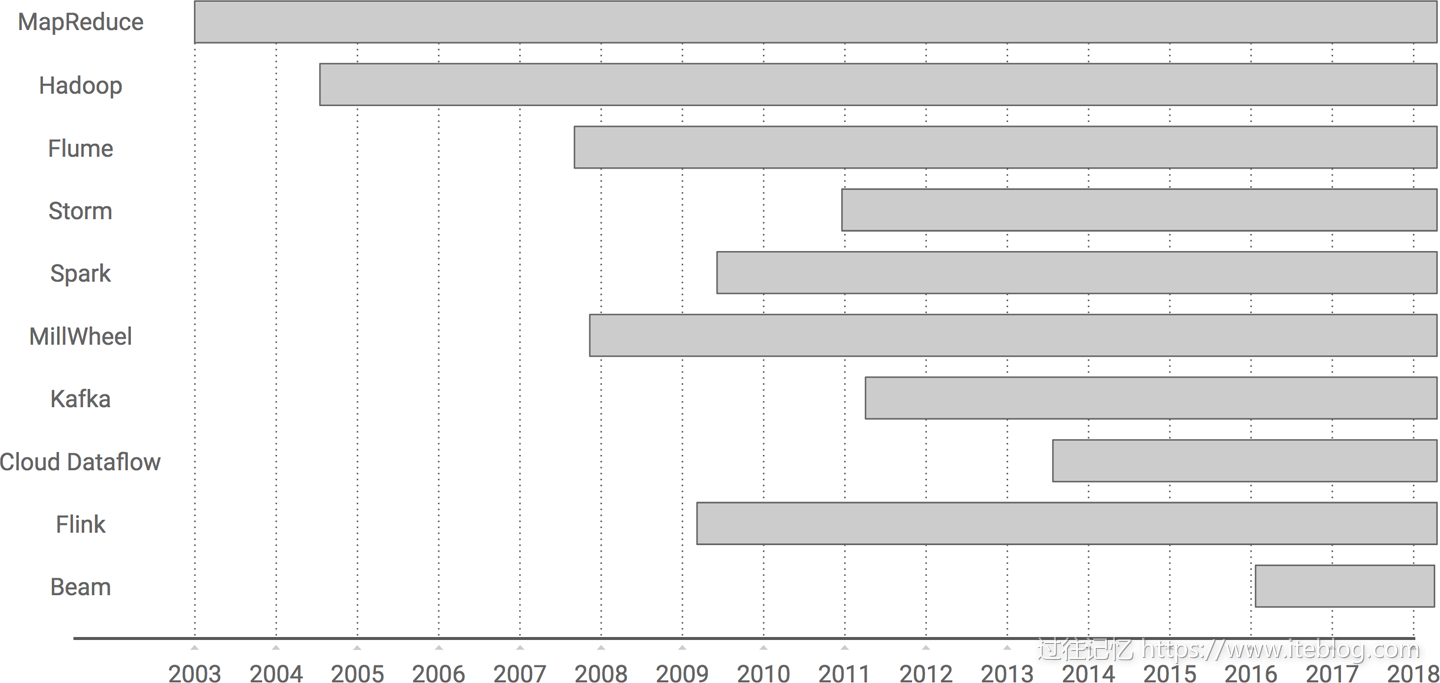
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 6年前 (2018-10-08) 10335℃ 2评论27喜欢



![Spark+AI Summit Europe 2018 PPT下载[共95个]](https://www.iteblog.com/pic/spark/Spark_ai_summit_europe_2018-iteblog.png)