背景如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据在 Uber,数据影响着每一个决定。Presto 是推动 Uber 各种数据分析的核心引擎之一。例如,运营团队在仪表盘等服务中大量使用 Presto;Uber Eats 和营销团队依靠这些查询的结果来决定价格。此外, Presto 还被用于 Uber 的合规部门、增长营销部 w397090770 2年前 (2022-11-14) 861℃ 0评论3喜欢
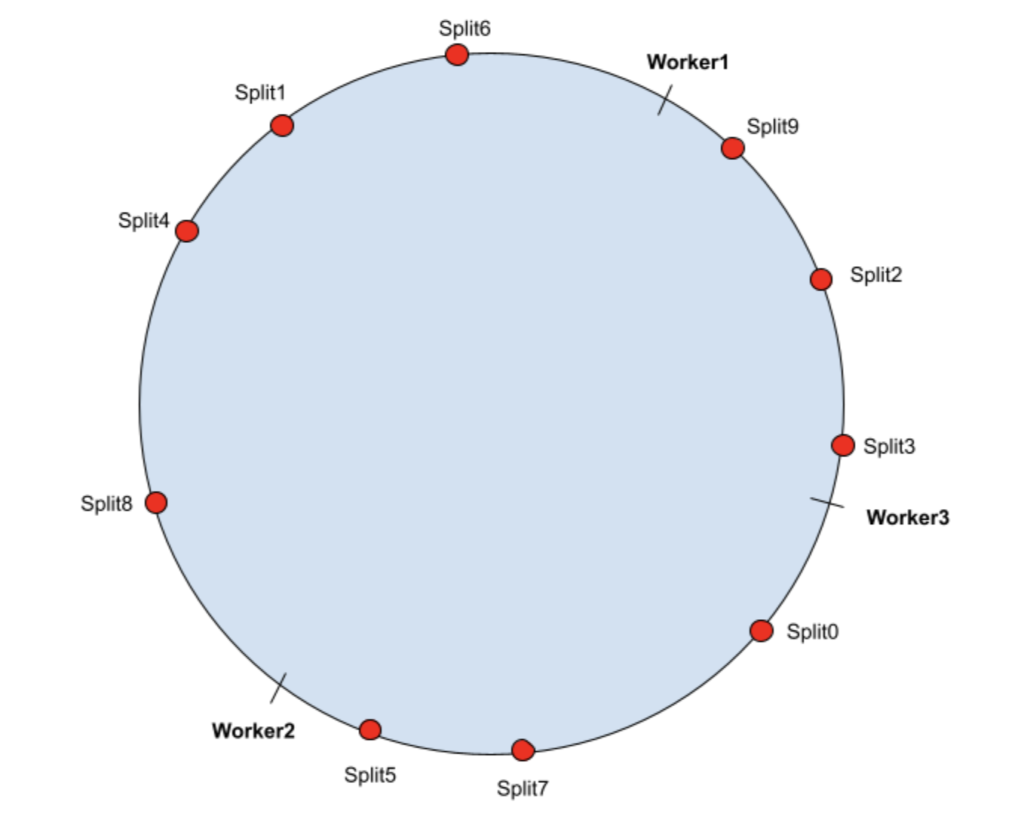
R目前,越来越多的用户开始在 Presto 里面使用 Alluxio,它通过利用 SSD 或内存在 Presto workers 上缓存热数据集,避免从远程存储读取数据。 Presto 支持基于哈希的软亲和调度(hash-based soft affinity scheduling),强制在整个集群中只缓存一到两份相同的数据,通过允许本地缓存更多的热数据来提高缓存效率。 但是,当前使用的哈希算法在集 w397090770 3年前 (2022-04-01) 488℃ 0评论1喜欢
金山云-企业云团队(赵侃、李金辉)在交互查询场景下对Presto与Alluxio相结合进行了一系列测试,并总结了一些Presto搭配Alluxio使用的建议。本次测试未使用对象存储,计算引擎与存储间的网络延时也比较低。如果存储IO耗时和网络耗时较大时,Alluxio加速收益应会更明显。测试目的验证影响Alluxio加速收益的各种因素记录Alluxio w397090770 3年前 (2022-03-29) 827℃ 0评论2喜欢
什么是 Alluxio Local Cache随着云计算在基础设施领域的市场份额持续上升,主流数据分析引擎纷纷选择独立扩展存储、计算来适配云基础设施,并以此为云提供商降低成本。但是,存储计算分离也为查询延迟带来了新的挑战,因为当网络饱和时,通过网络扫描大量数据将受到 IO 限制。此外,元数据也面临远程网络来检索的性能问题。 w397090770 3年前 (2022-03-21) 750℃ 0评论3喜欢
本资料来自2022年03月03日举办的 Alluxio Day 活动。分享议题 《Speed Up Uber’s Presto with Alluxio》,分享者 Liang Chen 和王北南。Uber 的 Liang Chen 和 Alluxio 的王北南将为大家呈现 Alluxio Local Cache 上线过程中遇到的实际问题和有趣的发现。他们的演讲涵盖了 Uber 的 Presto 团队如何解决 Alluxio 的本地缓存失效的问题。Liang Chen 还将分享他使用定 w397090770 3年前 (2022-03-07) 367℃ 0评论2喜欢
存储计算分离是整个行业的发展趋势,这种架构的存储和计算可以各自独立发展,它帮助云提供商降低成本。Presto 原生就支持这样的架构,数据可以从 Presto 服务器之外的远程存储节点传输过来。然而,存储计算分解也为查询延迟带来了新的挑战,因为当网络饱和时,通过网络扫描大量数据将受到 IO 限制。 此外,元数据的读取 w397090770 3年前 (2021-12-05) 813℃ 0评论2喜欢
本文介绍了如何使用 Presto 通过 Alluxio 查询 Iceberg 表。由于这项功能目前处于试验阶段,此处提供的信息可能会发生变化,请及时参考官方文档了解最新功能。关于如何使用 Presto 读取 Iceberg 上的数据请参考这里。我们知道,在 Hive 数据源上,Presto 支持两种形式的 Alluxio 缓存:通过 Alluxio local cache 以及 Alluxio Cluster,截止到本文章 w397090770 3年前 (2021-11-18) 1266℃ 0评论6喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Apache Hudi : The Path Forward》的分享,作者来自Apache Hudi 项目的原始创建者和副总裁 Vinoth Chandar 和 Zendesk 的 Raymond Xu。Raymond Xu leads the Data Lake team at Zendesk. He is also a PMC member and committer for Apache Hudi.Vinoth Chandar is the original creator & VP of the Apache Hudi project, which has changed the face of data lake archi w397090770 3年前 (2021-11-16) 495℃ 0评论1喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Improve Presto Architectural Decisions with Shadow Cache at Facebook》的分享,作者来自 Facebook 的 Ke Wang 和 普林斯顿CS系的 Zhenyu Song。Ke Wang is a software engineer at Facebook. She is currently developing solutions to help low latency queries in Presto at Facebook.Zhenyu Song is a Ph.D. student at Princeton CS Department. He works on using mach w397090770 3年前 (2021-11-16) 282℃ 0评论1喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Best Practice in Accelerating Data Applications with Spark+Alluxio》的分享,作者来自 Alluxio 的 David Zhu。本次演讲将分享 Alluxio 和 Spark 集成解决方案的设计和用例,以及在设计和实现 Alluxio分 布式系统时的最佳实践以及不要做什么。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 3年前 (2021-10-28) 586℃ 0评论1喜欢