2020年12月27日,Martin Traverso、 Dain Sundstrom 以及 David Phillips 大佬们宣布将 PrestoSQL 项目的名字更名为 Trino。新的项目地址为 https://trino.io/。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop正如上图的描述,这个仅仅是更改名字,之前的社区和软件都还在那的,这个项目还是由 Presto 的创始人和创 w397090770 4年前 (2020-12-28) 2054℃ 0评论1喜欢
Apache Kafka 2.7.0 于2020年12月21日正式发布,这个版本是目前 Kafka 最新稳定版本,大家可以根据需要自行决定是否需要升级到次版本,关于各个版本升级到 Apache Kafka 2.7.0 请参见《Upgrading to 2.7.0 from any version 0.8.x through 2.6.x》。在这个版本中,社区仍然在推进从 Kafka 移除对 ZooKeeper 的依赖,比如这个版本在 KIP-497 里面添加了可以修改 IS w397090770 4年前 (2020-12-27) 714℃ 0评论1喜欢
前言本文讨论了京东搜索在实时流量数据分析方面,利用Apache Flink和Apache Doris进行的探索和实践。流式计算在近些年的热度与日俱增,从Google Dataflow论文的发表,到Apache Flink计算引擎逐渐站到舞台中央,再到Apache Druid等实时分析型数据库的广泛应用,流式计算引擎百花齐放。但不同的业务场景,面临着不同的问题,没有哪一种引 w397090770 4年前 (2020-12-25) 1317℃ 0评论4喜欢
本文作者:车好多大数据 OLAP 团队-王培,由车好多大数据 OLAP 团队相关同事投稿。Presto 简介简介Presto 最初是由 Facebook 开发的一个分布式 SQL 执行引擎, 它被设计为用来专门进行高速、实时的数据分析,以弥补 Hive 在速度和对接多种数据源上的短板。发展历史如下:2012年秋季,Facebook启动Presto项目2013年冬季,Presto开源 w397090770 4年前 (2020-12-21) 964℃ 0评论3喜欢
一、前言本文主要介绍了 Presto 的简单原理,以及 Presto 在有赞的实践之路。二、Presto 介绍Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎。起初,Facebook 使用 Hive 来进行交互式查询分析,但 Hive 是基于 MapReduce 为批处理而设计的,延时很高,满足不了用户对于交互式查询想要快速出结果的场景。为了解决 Hive w397090770 4年前 (2020-12-21) 831℃ 0评论2喜欢
前言当开发人员通过我们提供的 API 使用公开的 Twitter 数据时,他们需要可靠性、高效的性能以及稳定性。因此,在前一段时间,我们为 Account Activity API 启动了 Account Activity Replay API ,让开发人员将稳定性融入到他们的系统中。Account Activity Replay API 是一个数据恢复工具,它允许开发人员检索5天前的事件。并且提供了恢复由于各种 w397090770 4年前 (2020-12-17) 577℃ 0评论0喜欢
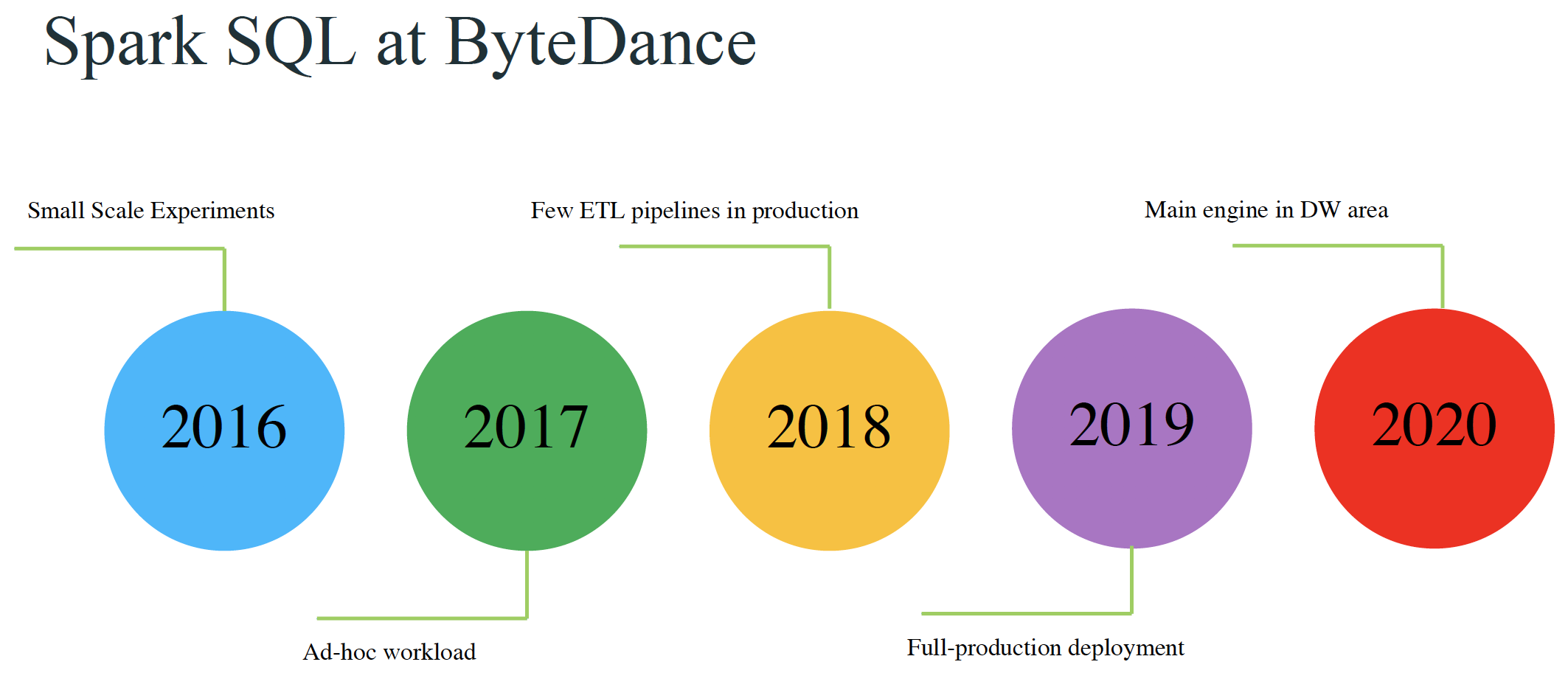
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Improving Spark SQL Performance by 30%: How We Optimize Parquet Filter Pushdown and Parquet Reader》的分享,作者为字节跳动的孙科和郭俊。相关 PPT 可以关注 Java与大数据架构 公众号并回复 9912 获取。Parquet 是一种非常流行的列式存储格式。Spark 的算子下推(pushdown filters)可以利用 P w397090770 4年前 (2020-12-14) 2533℃ 2评论4喜欢
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Materialized Column- An Efficient Way to Optimize Queries on Nested Columns》的分享,作者为字节跳动的郭俊。本文相关 PPT 可以关注 Java与大数据架构 公众号并回复 9910 获取。在数据仓库领域,使用复杂类型(如map)中的一列或多列,或者将许多子字段放入其中的场景是非常 w397090770 4年前 (2020-12-13) 903℃ 0评论3喜欢
2020年12月01日,IntelliJ IDEA 2020.3 正式发布,这是2020年的第三个里程碑版本。2020年其他两个版本可以参见IntelliJ IDEA 2020.2 稳定版发布 和 IntelliJ IDEA 2020.1 稳定版发布。本文主要介绍 IntelliJ IDEA 2020.3 的新功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop用户体验重新设置欢迎界面这个 w397090770 4年前 (2020-12-10) 1083℃ 0评论0喜欢
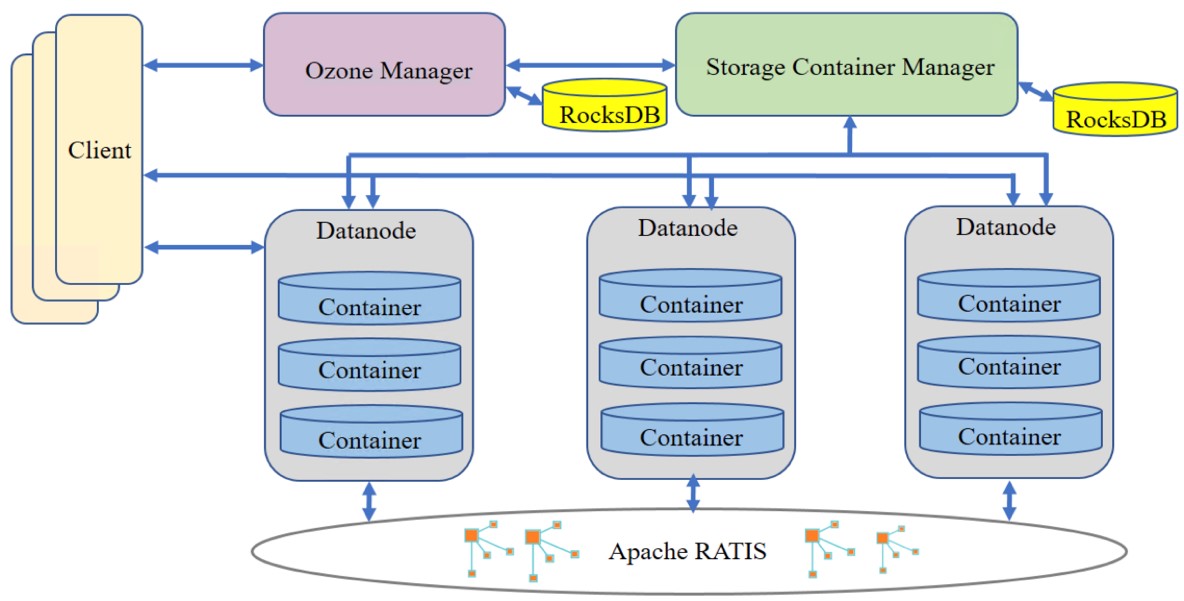
刚刚获悉,Apache基金董事会通过一致表决,正式批准分布式文件对象存储Ozone从Hadoop社区孵化成功,成为独立的Apache顶级开源项目。这意味着,作为腾讯大数据团队首个参与和主导的开源项目,Ozone已得到全球Apache技术专家的一致认可,成为世界顶级的存储开源项目之一。Ozone 是Apache Hadoop社区推出的面向大数据领域的新一代分布 w397090770 4年前 (2020-12-09) 1126℃ 0评论7喜欢