《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 北京第五次Spark meetup会议 w397090770 10年前 (2015-01-31) 3750℃ 0评论4喜欢
DataTables是一款非常简单的前端表格展示插件,它支持排序,翻页,搜索以及在客户端和服务端分页等多种功能。官方介绍:DataTables is a plug-in for the jQuery Javascript library. It is a highly flexible tool, based upon the foundations of progressive enhancement, and will add advanced interaction controls to any HTML table.它的数据源有很多种:主要有HTML (DOM)数据源 w397090770 10年前 (2015-01-28) 14749℃ 0评论16喜欢
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。在本文中的CSV格式的数据就不是简单的逗号分割的),其文件以纯文本形式存储表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字 w397090770 10年前 (2015-01-26) 9698℃ 0评论12喜欢
活动时间 1月24日下午14:00活动地点 地址:海淀区中关村软件园二期,西北旺东路10号院东区,亚信大厦 一层会议室 地图:http://j.map.baidu.com/L_1hq 为了保证大家乘车方便,特提供活动大巴时间:13:20-13:40位置:http://j.map.baidu.com/SJOLy分享内容: 邵赛赛 Intel Spark Streaming driver high availability w397090770 10年前 (2015-01-22) 15591℃ 0评论2喜欢
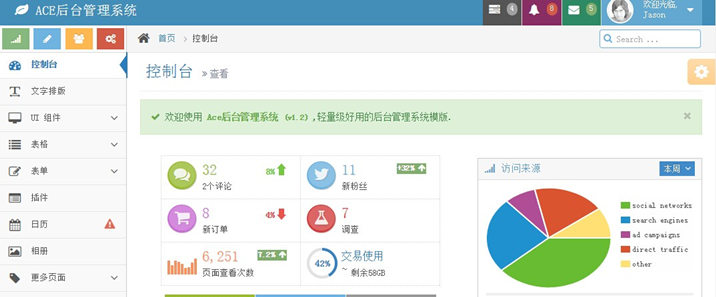
最近一段时间在做一个管理系统,在网上找了很久的前端展示框架,终于找到一款基于Bootstrap的后台管理系统模版:Ace。Bootstrap是Twitter 于2010年开发出来的前端框架,用过的同学应该知道,这款前端框架不仅界面很美观,而且兼容了很多的浏览器,大大加速了我们开发网站的速度!这篇文章讲到的Ace是基于Bootstrap的,所以界面自然 w397090770 10年前 (2015-01-19) 172310℃ 15评论459喜欢
七牛云存储直达地址:(点击这里) 随着网站建设的使用时间越来越长,我们的网站可能使用了越来越多的图片、CSS以及js文件,虽然这些的大小都不大,但如果请求的次数多了,这些文件的大小加起来就是一个可观的大小了!而且,如果你们页面图片或者js等文件多了,并且你的网站访问速度不太快的话,这会严重影响到 w397090770 10年前 (2015-01-12) 8831℃ 0评论11喜欢
这里用到的nginx日志是网站的访问日志,比如:[code lang="java"]180.173.250.74 - - [08/Jan/2015:12:38:08 +0800] "GET /avatar/xxx.png HTTP/1.1" 200 968 "/archives/994" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36"[/code] 这条日志里面有九列(为了展示的美观,我在里面加入了换行 w397090770 10年前 (2015-01-08) 14264℃ 2评论17喜欢
经过这段时间的整理以及格式调整,以及纠正其中的一些错误修改,整理出PDF下载。下载地址:[dl href="http://download.csdn.net/detail/w397090770/8337439"]CSDN免积分下载[/dl] 完整版可以到这里下载Learning Spark完整版下载附录:Learning Spark目录Chapter 1 Introduction to Data Analysis with Spark What Is Apache Spark? A Unified Stack Who Us w397090770 10年前 (2015-01-07) 32571℃ 6评论83喜欢
Spark支持读取很多格式的文件,其中包括了所有继承了Hadoop的InputFormat类的输入文件,以及平时我们常用的Text、Json、CSV (Comma Separated Values) 以及TSV (Tab Separated Values)文件。本文主要介绍如何通过Spark来读取Json文件。很多人会说,直接用Spark SQL模块的jsonFile方法不就可以读取解析Json文件吗?是的,没错,我们是可以通过那个读取Json w397090770 10年前 (2015-01-06) 26978℃ 10评论15喜欢
今天在项目中用到了Scala正则表达式,网上找了好久也没找到很全的资料,这里收集了Scala中很多常用的正则表达式使用方法。关于Scala正则表达式替换请参见:《Scala正则表达式替换》如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="scala"]scala> val regex="""([0-9]+) ([a-z]+)& w397090770 10年前 (2015-01-04) 24920℃ 0评论27喜欢