如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop尽管 IntelliJ IDEA 2020.2 版本发布不久,但我们已经带着一个改进版 IntelliJ IDEA 回来了。这个版本主要对 2020.2 版本进行了一些的调整,帮助您更加专注和高效。重要更新如下: 修复了 Lombok 插件被异常阻止的问题 经调试后,MacBook Touch Bar 不再 w397090770 4年前 (2020-08-25) 641℃ 0评论1喜欢
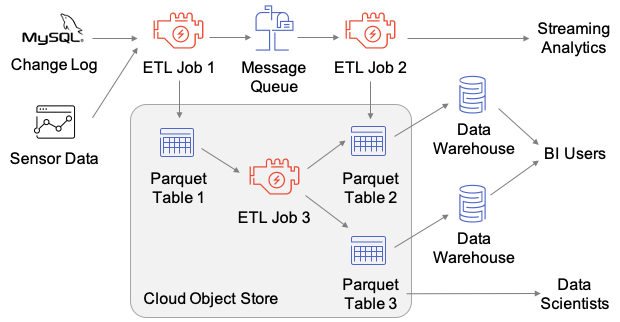
最近,数砖大佬们给 VLDB 投了一篇名为《Delta Lake: High-Performance ACID Table Storage overCloud Object Stores》的论文,并且被 VLDB 收录了,这是第一篇比较系统介绍数砖开发 Delta Lake 的论文。随着云对象存储(Cloud object stores)的普及,因为其廉价的成本,越来越多的企业都选择对象存储作为其海量数据的存储引擎。但是由于对象存储的特点 w397090770 4年前 (2020-08-25) 992℃ 0评论2喜欢
Apache Kafka 2.6.0 于2020年08月03日正式发布。在这个版本中,社区做了很多显著的性能改进,特别是当 Broker 有非常多的分区时。Broker 关闭性能得到了显著提高;当生产者使用压缩时,性能也得到了显著提高。ACL 使用的各个方面都有不同程度的提升,并且需要更少的内存。这个版本还增加了对 Java 14 的支持。在过去的几个版本中,社 w397090770 4年前 (2020-08-23) 829℃ 0评论0喜欢
桔妹导读:滴滴ElasticSearch平台承接了公司内部所有使用ElasticSearch的业务,包括核心搜索、RDS从库、日志检索、安全数据分析、指标数据分析等等。平台规模达到了3000+节点,5PB 的数据存储,超过万亿条数据。平台写入的峰值写入TPS达到了2000w/s,每天近 10 亿次检索查询。为了承接这么大的体量和丰富的使用场景,滴滴ElasticSearch需要 w397090770 4年前 (2020-08-19) 1327℃ 0评论6喜欢
前言Facebook 的数据仓库构建在 HDFS 集群之上。在很早之前,为了能够方便分析存储在 Hadoop 上的数据,Facebook 开发了 Hive 系统,使得科学家和分析师可以使用 SQL 来方便的进行数据分析,但是 Hive 使用的是 MapReduce 作为底层的计算框架,随着数据分析的场景和数据量越来越大,Hive 的分析速度越来越慢,可能得花费数小时才能完成 w397090770 4年前 (2020-08-09) 1507℃ 0评论4喜欢
在 《Apache Spark 自定义优化规则:Custom Strategy》 文章中我们介绍了如何自定义策略,策略是用在逻辑计划转换到物理计划阶段。而本文将介绍如何自定义逻辑计划优化规则,主要用于优化逻辑计划,和前文不一样的地方是,逻辑优化规则只是等价变换逻辑计划,也就是 Logic Plan -> Login Plan,这个是在应用策略前进行的。如果想及时 w397090770 4年前 (2020-08-07) 1124℃ 0评论2喜欢
这篇文章本来19年5月份就想写的,最终拖到今天才整理出来😂。Spark 内置给我们带来了非常丰富的各种优化,这些优化基本可以满足我们日常的需求。但是我们知道,现实场景中会有各种各样的需求,总有一些场景在 Spark 得到的执行计划不是最优的,社区的大佬肯定也知道这个问题,所以从 Spark 1.3.0 开始,Spark 为我们提供 w397090770 4年前 (2020-08-05) 1046℃ 2评论3喜欢
微信公众号开发者模式可以支持自动回复回复文本、图片、图文、语音、视频以及音乐(参见 被动回复用户消息),下面是回复图片消息的返回结果格式:[code lang="xml"]<xml> <ToUserName><![CDATA[toUser]]></ToUserName> <FromUserName><![CDATA[fromUser]]></FromUserName> <CreateTime>12345678</CreateTime> <MsgType> w397090770 4年前 (2020-08-04) 644℃ 0评论1喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop假设我们有以下表:[code lang="scala"]scala> spark.sql("""CREATE TABLE iteblog_test (name STRING, id int) using orc PARTITIONED BY (id)""").show(100)[/code]我们往里面插入一些数据:[code lang="sql"]scala> spark.sql("insert into table iteblog_test select w397090770 4年前 (2020-08-03) 3075℃ 0评论4喜欢