

最近,数砖大佬们给 VLDB 投了一篇名为《Delta Lake: High-Performance ACID Table Storage overCloud Object Stores》的论文,并且被 VLDB 收录了,这是第一篇比较系统介绍数砖开发 Delta Lake 的论文。
随着云对象存储(Cloud object stores)的普及,因为其廉价的成本,越来越多的企业都选择对象存储作为其海量数据的存储引擎。但是由于对象存储的特点,其主要有两个比较严重的问题:correctness 和 performance 问题,具体如下:
- 首先,因为多对象的更新不是原子的,所以查询之间不存在隔离(First, because multi-object updates are not atomic, there is no isolation between queries)。例如,如果一个查询需要更新表中的多个对象,那么我们查询的时候可以看到数据一部分更新了,一部分没有更新。
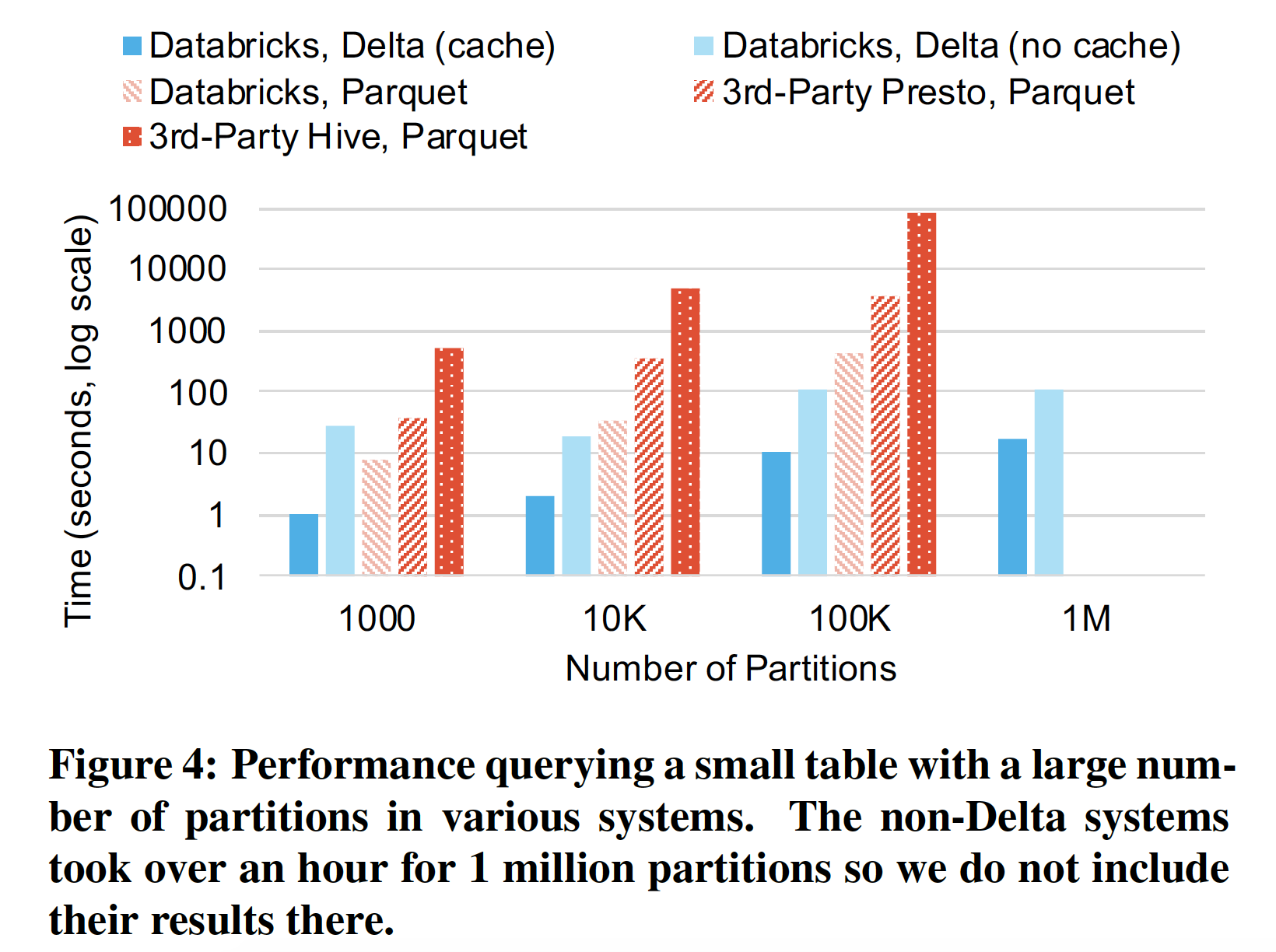
- 其次,对于具有数百万个对象的大表,元数据操作的开销很大(Second, for large tables with millions of objects, metadata operations are expensive)。例如,Parquet 文件在页脚部分包含最小/最大统计信息,查询的时候可以利用这些信息跳过一些不用的文件。 在 HDFS 上读取这些文件的页脚信息可能要花费几毫秒,但是云对象存储的延迟要高得多,甚至读取这些统计信息以便跳过一些不必要读取的文件可能比实际查询花费更长的时间。
在过去(2014 - 2016),数砖大约花费一半的时间用于解决对象存储导致的数据损坏、一致性以及性能问题。为了解决这个问题,数砖开发了 Delta Lake,并于 2017 年提供给客户使用,2019年开源了这个项目。Delta Lake 解决了上面的问题,同时还带来以下几个传统对象存储没有提供的功能:
- Time travel:这个特性可以让用户查询给定时间点的快照或回滚错误更新到之前正确的数据。
- UPSERT, DELETE 和 MERGE 操作:这些操作可有效地重写相关对象,以实现对存档数据和法规遵从性工作流的更新;
- 高效的流 IO:通过让流作业以低延迟的形式将小对象写入表中,然后以事务形式将它们合并到较大的对象中以提高查询性能。
- 缓存:由于 Delta 表中的对象及其日志是不可变(immutable)的,因此集群节点可以安全地将它们缓存在本地存储中。Databricks 云服务利用此功能为 Delta 表实现透明的 SSD 缓存。
- 数据布局优化:这个功能可自动优化表中对象的大小,并且会对数据记录进行聚类(clustering)(例如,将记录存储存储成 Zorder 形式以实现多个维度上的本地化)而不会影响正在运行的查询。这个功能只有数砖的产品里面有,来源的 Delta Lake 是不包含这个的。
- 模式演变:如果表的模式发生变化,Delta 可以继续读取旧的 Parquet 文件而无需重写它们。
- 审计日志:基于事务日志的审计功能。
在 Delta Lake 之前,很多企业使用对象存储时比较场景的架构如下:
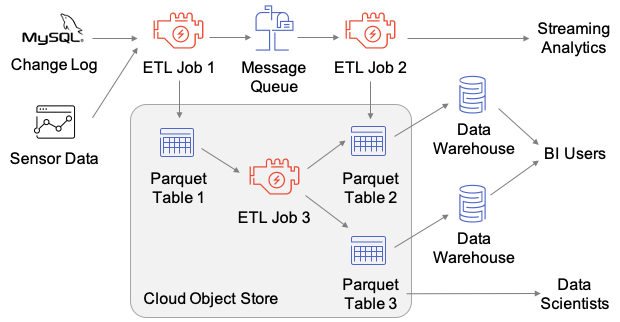
上图使用了三个存储系统:消息队列、对象存储以及数据仓库。有了 Delta Lake 之后,系统架构简化为:

既支持流式数据的写入,又支持离线数据写入。同时去掉了多份数据的拷贝,所有的数据存储都是用廉价的对象存储。
论文的第二部分详细介绍了对象存储的特点及挑战,第三部分介绍了 Delta Lake 的存储格式和访问协议。
在事务日志原子性写入方面,论文进行了详细讨论。比如在写往 Delta Lake 表写数据的时候,最后会生成 xxxx.json 文件用于记录哪些文件是添加的,哪些文件是删除的,这个文件的创建必须是原子性的。换句话说,在并发往一张 Delta Lake 表写数据的时候,只有一个客户端能够成功创建 xxxx.json 文件,其他客户端检测出 xxxx.json 文件已经创建需要失败。但是不幸的是,并非所有的存储系统支持 put-if-absent 原子操作,需要为不同的存储系统实现不同的方式:
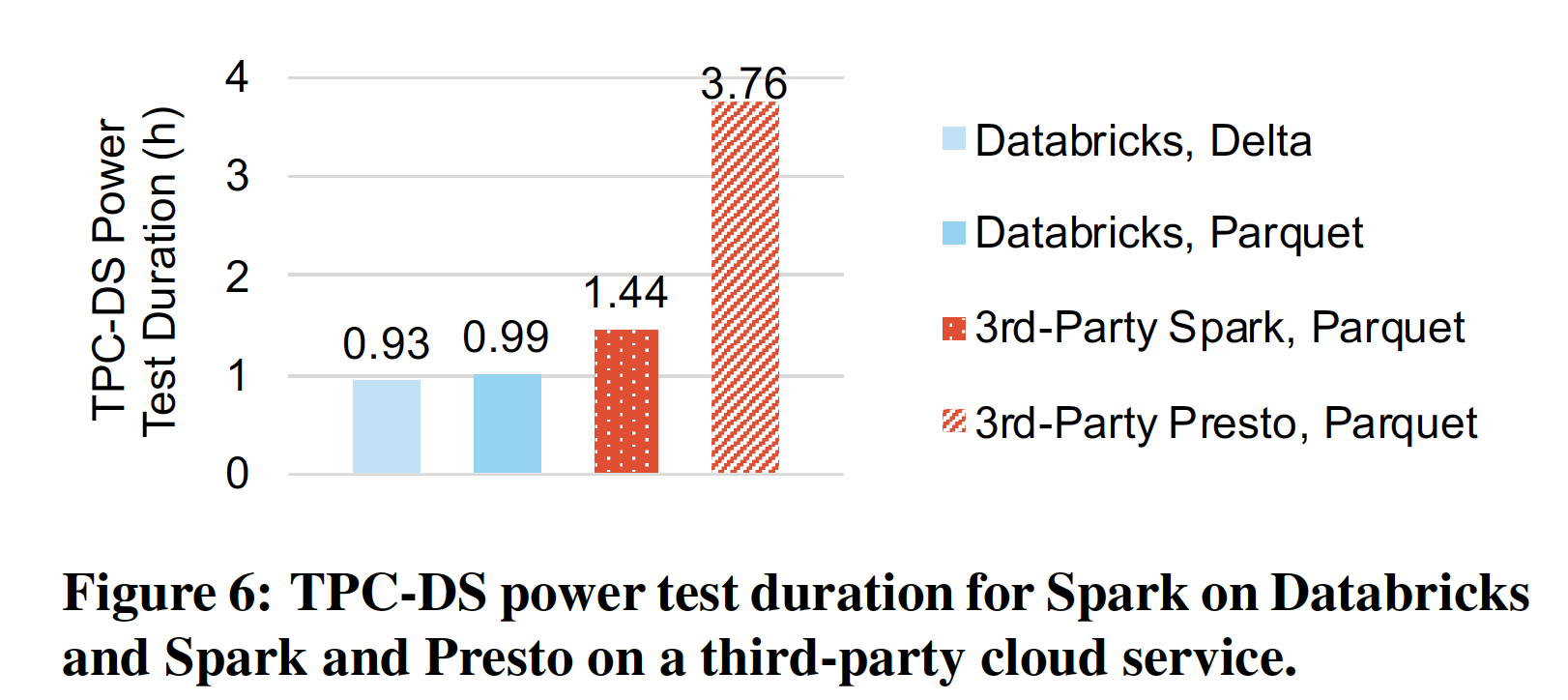
第四部分从高层次介绍了 Delta Lake 提供的特性;第五部分介绍了 Delta Lake 的用户案例;第六部分主要和其他系统进行性能对比。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
感兴趣的同学可以去看下这篇论文,论文下载地址: Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores,
CSDN 免积分下载:https://download.csdn.net/download/w397090770/12741763
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Delta Lake 第一篇论文发布了】(https://www.iteblog.com/archives/9852.html)







