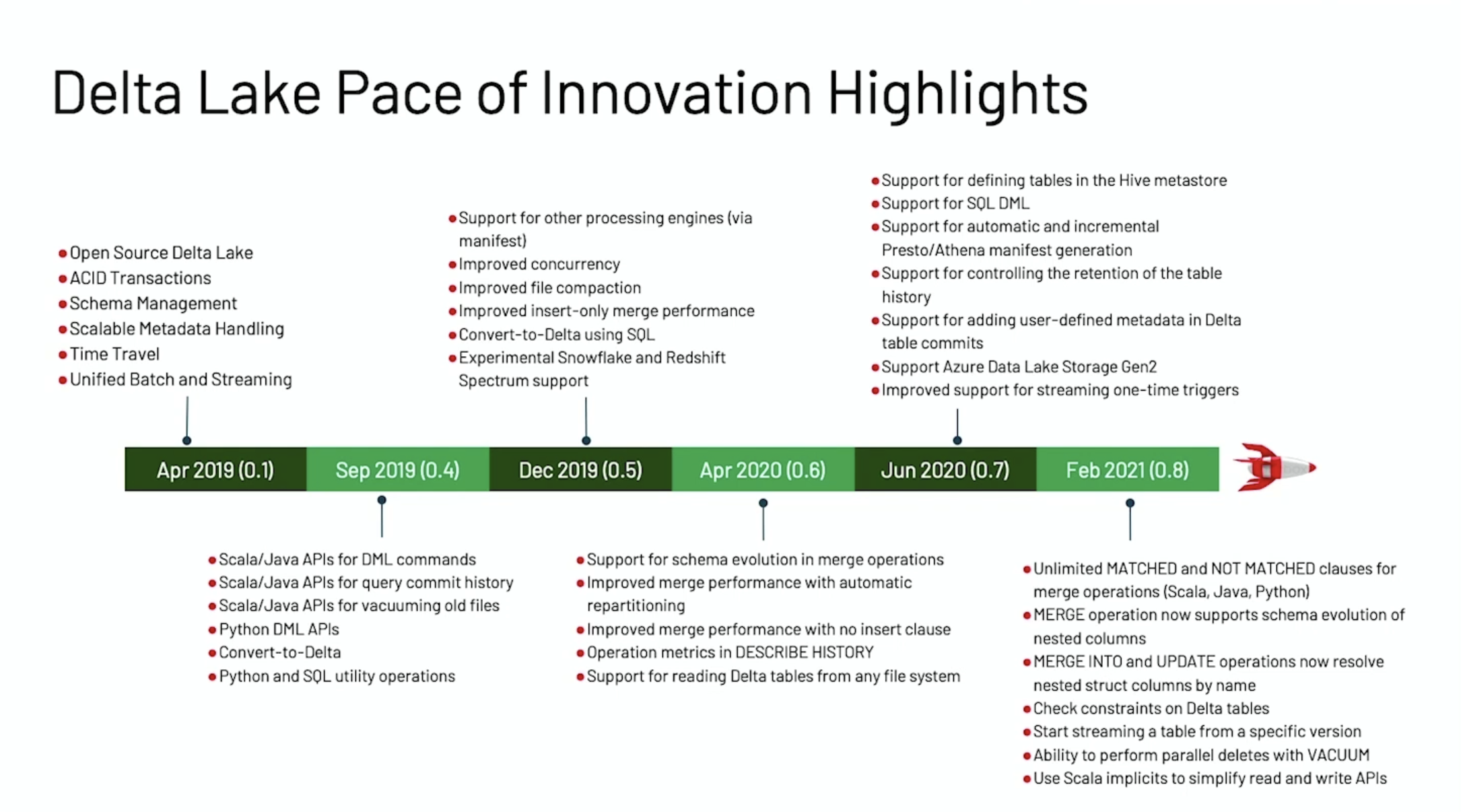
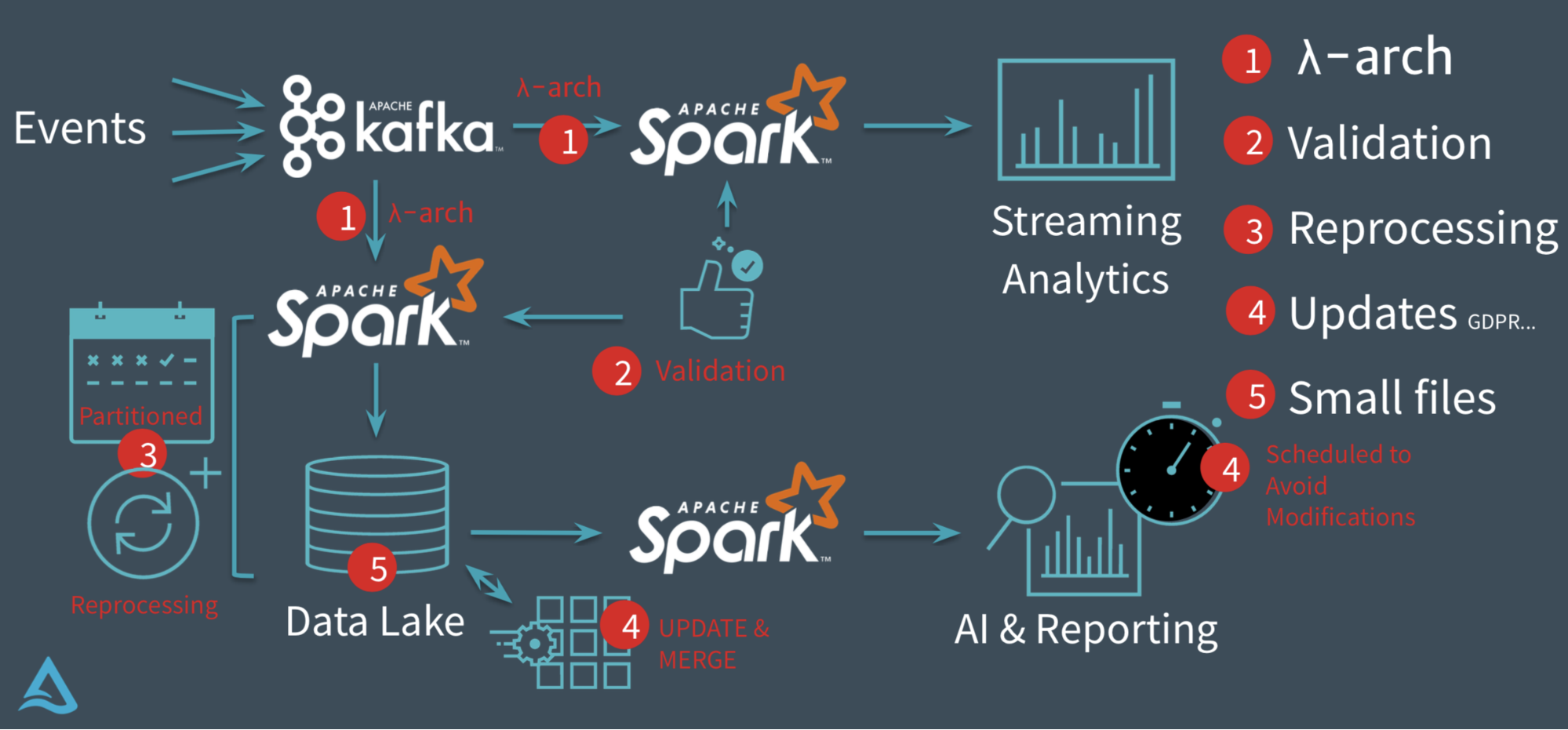
赶在 Data + AI Summit 2021 之前,Delta Lake 1.0.0 重磅发布,这个版本是基于 Spark 3.1 的,带来了许多新特性。本文将结合 Michael Armbrust 大牛在 Data + AI Summit 2021 的演讲《Announcing Delta Lake 1.0》来介绍 Delta Lake 1.0.0 版本的一些重要的新特性。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据Delta Lake 0.1 w397090770 4年前 (2021-05-27) 887℃ 0评论2喜欢
本书作者 Denny Lee, Tathagata Das, Vini Jaiswal,预计2022年4月出版,出版社 O'Reilly Media, Inc.,ISBN:9781098104528分析和机器学习模型的好坏取决于它们所依赖的数据。查询处理过的数据并从中获得见解需要一个健壮的数据管道——以及一个有效的存储解决方案,以确保数据质量、数据完整性和性能。本指南向您介绍 Delta Lake,这是一种开 w397090770 4年前 (2021-05-27) 588℃ 0评论2喜欢
本文是 Forest Rim Technology 数据团队撰写的,作者 Bill Inmon 和 Mary Levins,其中 Bill Inmon 被称为是数据仓库之父,最早的数据仓库概念提出者,被《计算机世界》评为计算机行业历史上最具影响力的十大人物之一。原始数据的挑战随着大量应用程序的出现,产生了相同的数据在不同地方出现不同值的情况。为了做出决定,用户必须找 w397090770 4年前 (2021-05-25) 636℃ 0评论0喜欢
最近,Delta Lake 发布了一项新功能,也就是支持直接使用 Scala、Java 或者 Python 来查询 Delta Lake 里面的数据,这个是不需要通过 Spark 引擎来实现的。Scala 和 Java 读取 Delta Lake 里面的数据是通过 Delta Standalone Reader 实现的;而 Python 则是通过 Delta Rust API 实现的。Delta Lake 是一个开源存储层,为数据湖带来了可靠性。Delta Lake 提供 ACID 事务 w397090770 4年前 (2021-01-05) 1162℃ 0评论0喜欢
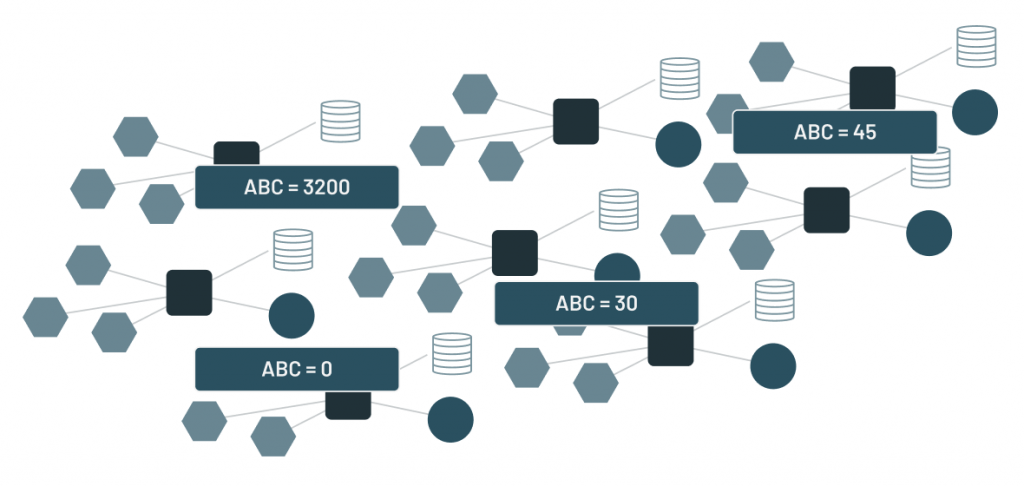
背景数据湖(Data Lake),湖仓一体(Data Lakehouse)俨然已经成为了大数据领域最为火热的流行词,在接受这些流行词洗礼的时候,身为技术人员我们往往会发出这样的疑问,这是一种新的技术吗,还是仅仅只是概念上的翻新(新瓶装旧酒)呢?它到底解决了什么问题,拥有什么样新的特性呢?它的现状是什么,还存在什么问题呢? w397090770 4年前 (2020-11-28) 5736℃ 0评论7喜欢
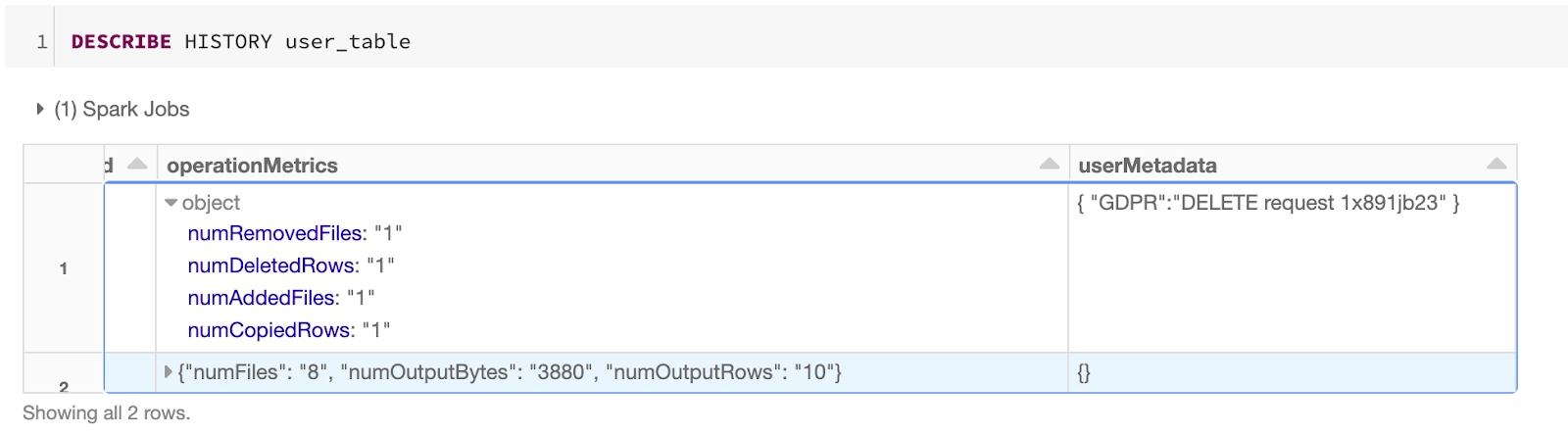
Delta Lake 支持 DML 命令,包括 DELETE, UPDATE, 以及 MERGE,这些命令简化了 CDC、审计、治理以及 GDPR/CCPA 工作流等业务场景。在这篇文章中,我们将演示如何使用这些 DML 命令,并会介绍这些命令的后背实现,同时也会介绍对应命令的一些性能调优技巧。Delta Lake: 基本原理如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 4年前 (2020-10-12) 1535℃ 0评论0喜欢
在实践经验中,我们知道数据总是在不断演变和增长,我们对于这个世界的心智模型必须要适应新的数据,甚至要应对我们从前未知的知识维度。表的 schema 其实和这种心智模型并没什么不同,需要定义如何对新的信息进行分类和处理。这就涉及到 schema 管理的问题,随着业务问题和需求的不断演进,数据结构也会不断发生变化。 w397090770 4年前 (2020-09-12) 615℃ 0评论0喜欢
Delta Lake 0.7.0 是随着 Apache Spark 3.0 版本发布之后发布的,这个版本比较重要的特性就是支持使用 SQL 来操作 Delta 表,包括 DDL 和 DML 操作。本文将详细介绍如何使用 SQL 来操作 Delta Lake 表,关于 Delta Lake 0.7.0 版本的详细 Release Note 可以参见这里。使用 SQL 在 Hive Metastore 中创建表Delta Lake 0.7.0 支持在 Hive Metastore 中定义 Delta 表,而且这 w397090770 4年前 (2020-09-06) 1181℃ 0评论0喜欢
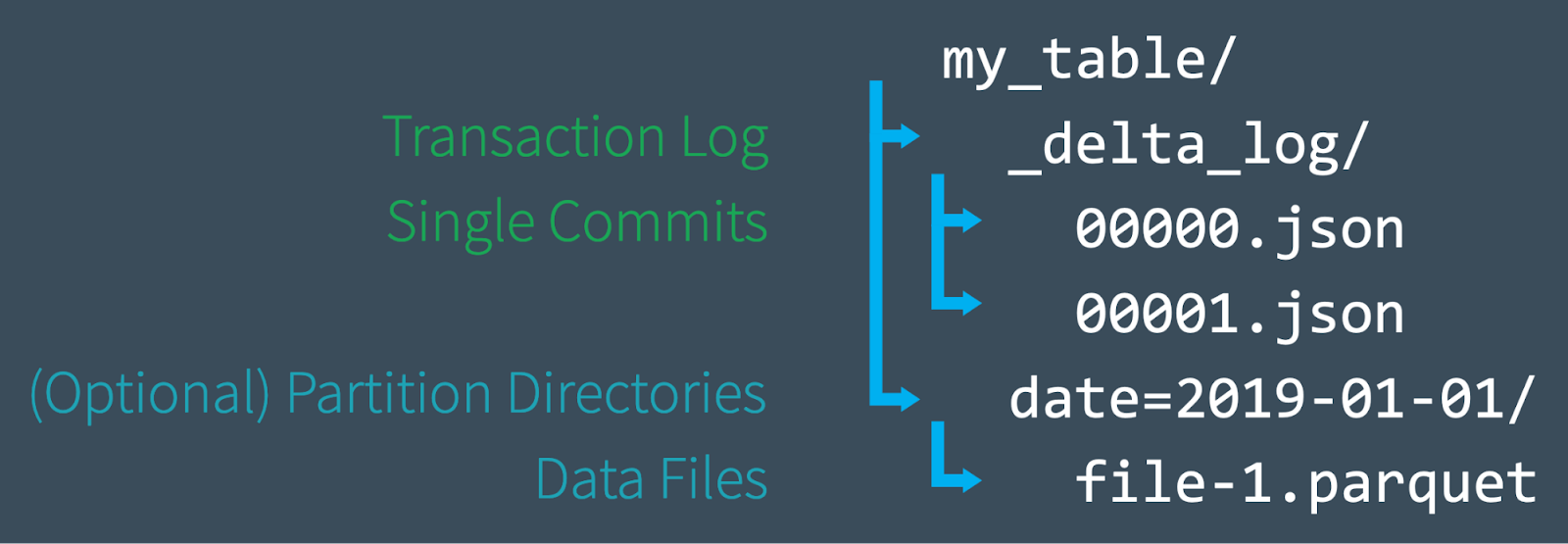
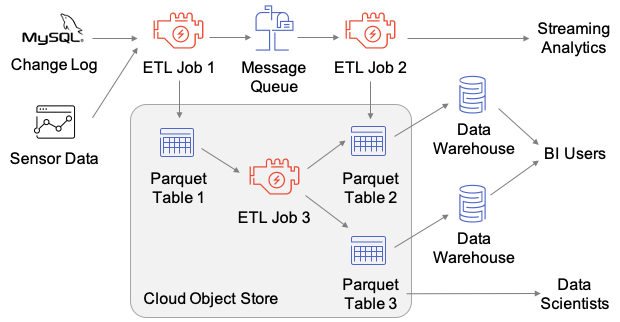
最近,数砖大佬们给 VLDB 投了一篇名为《Delta Lake: High-Performance ACID Table Storage overCloud Object Stores》的论文,并且被 VLDB 收录了,这是第一篇比较系统介绍数砖开发 Delta Lake 的论文。随着云对象存储(Cloud object stores)的普及,因为其廉价的成本,越来越多的企业都选择对象存储作为其海量数据的存储引擎。但是由于对象存储的特点 w397090770 4年前 (2020-08-25) 1059℃ 0评论2喜欢
目前市面上流行的三大开源数据湖方案分别为:Delta、Apache Iceberg 和 Apache Hudi。其中,由于 Apache Spark 在商业化上取得巨大成功,所以由其背后商业公司 Databricks 推出的 Delta 也显得格外亮眼。Apache Hudi 是由 Uber 的工程师为满足其内部数据分析的需求而设计的数据湖项目,它提供的 fast upsert/delete 以及 compaction 等功能可以说是精准命中 w397090770 5年前 (2020-03-05) 4005℃ 0评论2喜欢