2010年,几个大胡子年轻人在旧金山成立了一家名为 dotCloud 的 PaaS 平台的公司。dotCloud 主要是基于 PaaS 平台为开发者或开发商提供技术服务。PaaS 的全称是 Platform as a Service,也就是平台即服务。dotCloud 把需要花费大量时间的手工工作和重复劳动抽象成组件和服务,并放到了云端,另外,它还提供了各种监控、告警和控制功能,方便开 w397090770 5年前 (2020-01-15) 868℃ 0评论8喜欢
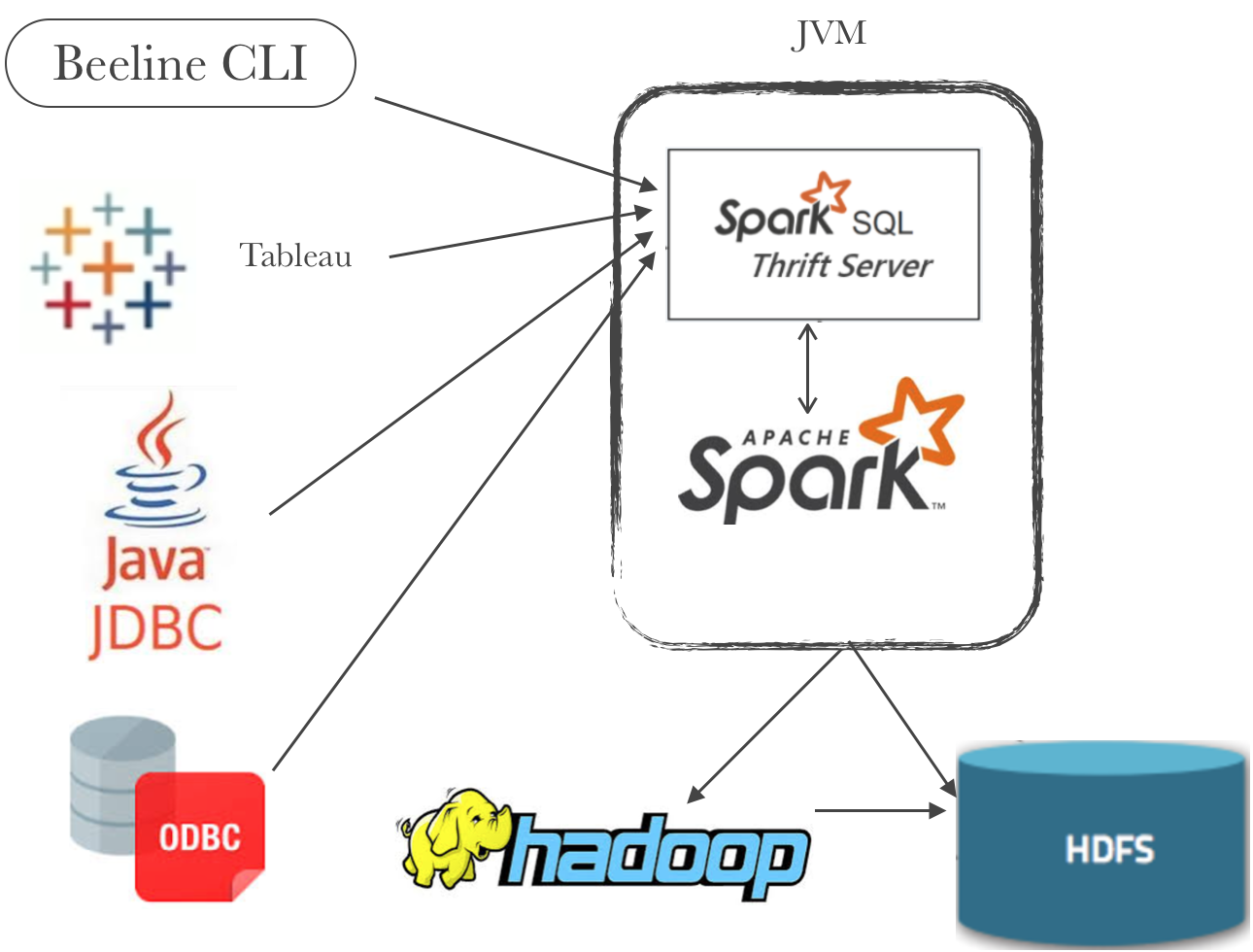
HDFS 简介因为 HDFS 这样一个系统已经存在了非常长的时间,应用的场景已经非常成熟了,所以这部分我们会比较简单地介绍。HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:和本地文件系统一样的目录树视图Append Only 的写入(不支持 w397090770 5年前 (2020-01-10) 2410℃ 0评论4喜欢
背景熟悉 Spark 的同学都知道,Spark 作业启动的时候我们需要指定 Exectuor 的个数以及内存、CPU 等信息。但是在 Spark 作业运行的时候,里面可能包含很多个 Stages,这些不同的 Stage 需要的资源可能不一样,由于目前 Spark 的设计,我们无法对每个 Stage 进行细粒度的资源设置。而且即使是一个资深的工程师也很难准确的预估一个比较 w397090770 5年前 (2020-01-10) 1517℃ 0评论2喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop回望过去10年,数据技术发展迅速,数据也在呈现爆炸式的增长,这也伴随着如下两个现象。一、数据更加分散:企业的数据是散落在不同的数据存储之中,如对象存储OSS,OLTP的MySQL,NoSQL的Mongo及HBase,以及数据仓库ADB之中,甚至是以服务的形式 w397090770 5年前 (2020-01-07) 1197℃ 0评论3喜欢
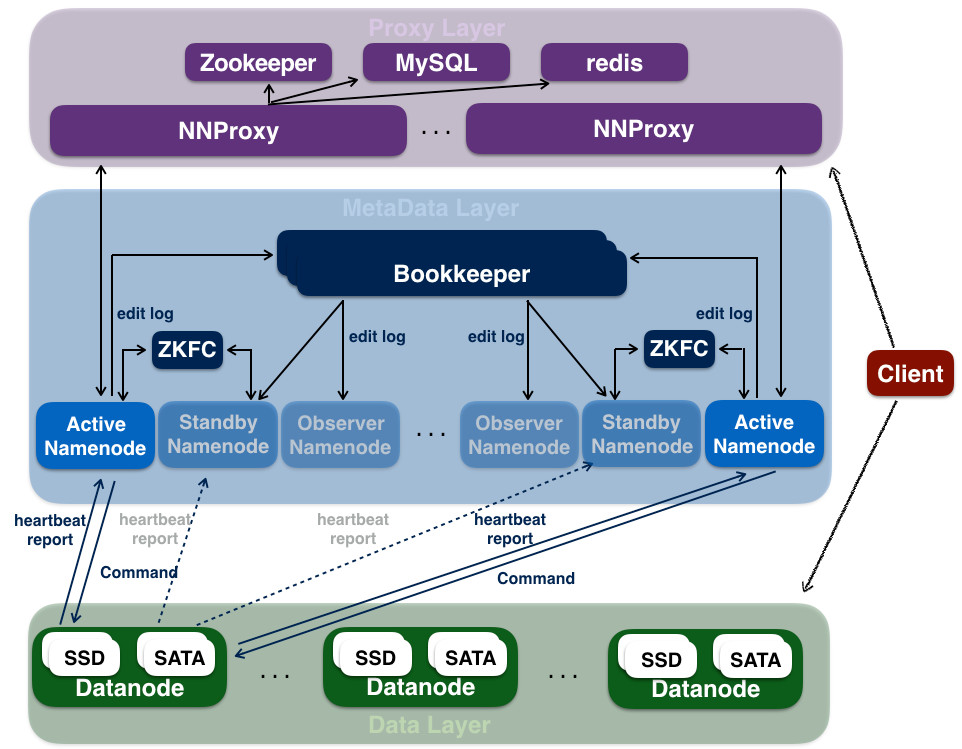
为什么要升级在2017年底, Hadoop3.0 发布了,到目前为止, Hadoop 发布的最新版本为3.2.1。在 Hadoop3 中有很多有用的新特性出现,如支持 ErasureCoding、多 NameNode、Standby NameNode read、DataNode Disk Balance、HDFS RBF 等等。除此之外,还有很多性能优化以及 BUG 修复。其中最吸引我们的就是 ErasureCoding 特性,数据可靠性保持不变的情况下可以降 w397090770 5年前 (2020-01-05) 2605℃ 0评论11喜欢
一、前言在 2019 年 1 月份的时候,我们发表过一篇博客 从 Hive 迁移到 Spark SQL 在有赞的实践,里面讲述我们在 Spark 里所做的一些优化和任务迁移相关的内容。本文会接着上次的话题继续讲一下我们之后在 SparkSQL 上所做的一些改进,以及如何做到 SparkSQL 占比提升到 91% 以上,最后也分享一些在 Spark 踩过的坑和经验希望能帮助到大家 w397090770 5年前 (2020-01-05) 1740℃ 0评论2喜欢
背景随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品、订单等数据的多维度检索。使用 Elasticsearch 存储业务数据可以很好的解决我们业务中的搜索需求。而数据进行异构存储后,随之而来的就是数据同步的问题。现有方法及问题对于数据同步,我们目前 w397090770 5年前 (2020-01-04) 1202℃ 0评论6喜欢
这是一份迟来的年终报告,本来昨天就要发出来的,实在是没忙开,今天我就把它当作新年礼物送给各位看官,以下文章都是我结合日常工作、学习,每当“夜深人静"的时候写出来的一些小总结,希望能给大家一些技术上的帮助。关注我的朋友都知道,我在今年八月份发了一篇文章,里面整理了我五年来写在这个公众号上面的原 w397090770 5年前 (2020-01-04) 1392℃ 0评论1喜欢