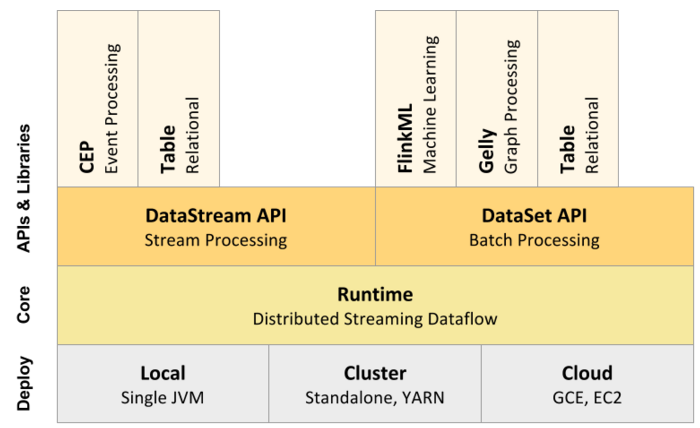
Apache Flink是一个高效、分布式、基于Java和Scala(主要是由Java实现)实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。 从Flink官方文档可以知道,目前Flink支持三大部署模式:Local、Cluster以及Cloud w397090770 9年前 (2016-03-30) 24293℃ 6评论22喜欢
我们往Kafka发送消息时一般都是将消息封装到KeyedMessage类中:[code lang="scala"]val message = new KeyedMessage[String, String](topic, key, content)producer.send(message)[/code]Kafka会根据传进来的key计算其分区ID。但是这个Key可以不传,根据Kafka的官方文档描述:如果key为null,那么Producer将会把这条消息发送给随机的一个Partition。If the key is null, the w397090770 9年前 (2016-03-30) 16383℃ 0评论10喜欢
我们都知道,使用Kafka Producer往Kafka的Broker发送消息的时候,Kafka会根据消息的key计算出这条消息应该发送到哪个分区。默认的分区计算类是HashPartitioner,其实现如下:[code lang="scala"]class HashPartitioner(props: VerifiableProperties = null) extends Partitioner { def partition(data: Any, numPartitions: Int): Int = { (data.hashCode % numPartitions) }}[/code] w397090770 9年前 (2016-03-29) 9245℃ 0评论9喜欢
北京第十次Spark Meetup活动于北京时间2016年03月27日在北京市海淀区丹棱街5号微软亚太研发集团总部大厦1号楼进行。活动内容如下:1. Spark in TalkingData,阎志涛.TalkingData研发副总裁2. Spark in GrowingIO,田毅,GrowingIO数据平台工程师,主要分享GrowingIO使用Spark进行数据处理过程中的各种小技巧,包括:多数据源的访问和使用Bitmap进行 w397090770 9年前 (2016-03-28) 2131℃ 0评论4喜欢
昨天Kafka集群磁盘容量达到了90%,于是赶紧将Log的保存时间设置成24小时,但是发现设置完之后Log仍然没有被删除。于是今天特意去看了一下Kafka日志删除相关的代码,于是有了这篇文章。 在使用Kafka的时候我们一般都会根据需求对Log进行保存,比如保存1天、3天或者7天之类的,我们可以通过以下的几个参数实现:[code lan w397090770 9年前 (2016-03-28) 5559℃ 0评论17喜欢
7.1 TF-IDF TF-IDF是一种特征向量化方法,这种方法多用于文本挖掘,通过算法可以反应出词在语料库中某个文档中的重要性。文档中词记为t,文档记为d , 语料库记为D . 词频TF(t,d) 是词t 在文档d 中出现的次数。文档频次DF(t,D) 是语料库中包括词t的文档数。如果使用词在文档中出现的频次表示词的重要程度,那么很容易取出反例, w397090770 9年前 (2016-03-27) 6054℃ 0评论6喜欢
JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序、设备、系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。启动JMX监控,在启动java程序的时候最少需要在环境变量里面配置以下的选项:[code lang="bash"]-Dcom.sun.m w397090770 9年前 (2016-03-25) 6274℃ 0评论10喜欢
当一个broker停止或者crashes时,所有本来将它作为leader的分区将会把leader转移到其它broker上去。这意味着当这个broker重启时,它将不再担任何分区的leader,kafka的client也不会从这个broker来读取消息,从而导致资源的浪费。比如下面的broker 7是挂掉重启的,我们可以发现Partition 1虽然在broker 7上有数据,但是由于它挂了,所以Kafka重新 w397090770 9年前 (2016-03-24) 8388℃ 0评论5喜欢
hljs.initHighlightingOnLoad(); 我们往已经部署好的Kafka集群里面添加机器是最正常不过的需求,而且添加起来非常地方便,我们需要做的事是从已经部署好的Kafka节点中复制相应的配置文件,然后把里面的broker id修改成全局唯一的,最后启动这个节点即可将它加入到现有Kafka集群中。 但是问题来了,新添加的Kafka节点并不会 w397090770 9年前 (2016-03-24) 12800℃ 2评论23喜欢
商业敏感数据虽然难以获取,但好在仍有相当多有用数据可公开访问。它们中的不少常用来作为特定机器学习问题的基准测试数据。常见的有以下几个:UCL机器学习知识库包括近300个不同大小和类型的数据集,可用于分类、回归、聚类和推荐系统任务。数据集列表位于:http://archive.ics.uci.edu/ml/Amazon AWS公开数据集包含的 w397090770 9年前 (2016-03-22) 8388℃ 0评论9喜欢