代码生成是很多计算引擎中常用的执行优化技术,比如我们熟悉的 Apache Spark 和 Presto 在表达式等地方就使用到代码生成技术。这两个计算引擎虽然都用到了代码生成技术,但是实现方式完全不一样。在 Spark 中,代码生成其实就是在 SQL 运行的时候根据相关算子动态拼接 Java 代码,然后使用 Janino 来动态编译生成相关的 Java 字节码并 w397090770 3年前 (2021-09-28) 705℃ 0评论3喜欢
导语:此套面试题来自于各大厂的真实面试题及常问的知识点。如果能理解吃透这些问题,你的大数据能力将会大大提升,进入大厂指日可待。如果公司急招人,你回答出来面试官70%,甚至50%的问题他都会要你,如果这个公司不是真正缺人,或者只是作人才储备,那么你回答很好,他也可能不要你,只是因为没有眼缘;所以面 zz~~ 3年前 (2021-09-24) 2336℃ 0评论9喜欢
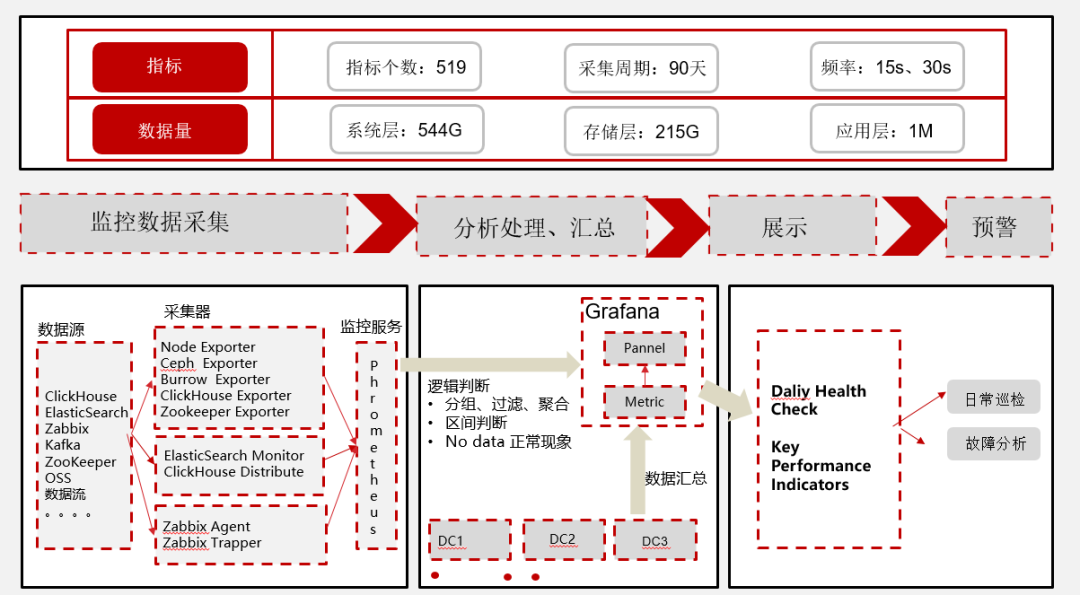
导语:随着互联网业务的迅速发展,用户对系统的要求也越来越高,而做好监控为系统保驾护航,能有效提高系统的可靠性、可用性及用户体验。监控系统是整个运维环节乃至整个项目及产品生命周期中最重要的一环。百分点大数据技术团队基于大数据平台项目,完成了百亿流量、约3000+台服务器集群规模的大数据平台服务的监控, zz~~ 3年前 (2021-09-24) 609℃ 0评论4喜欢
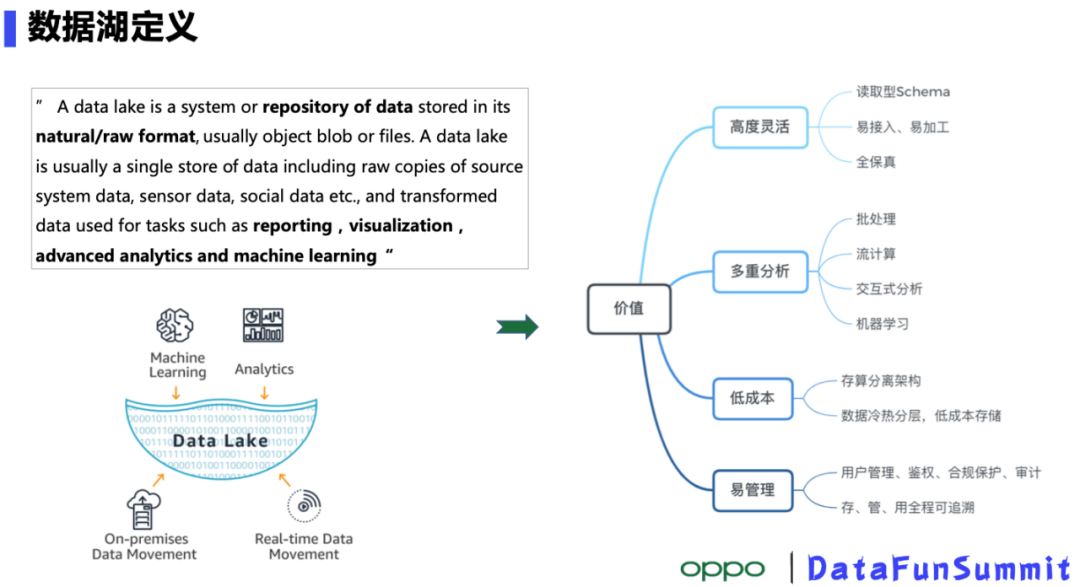
导读:OPPO是一家智能终端制造公司,有着数亿的终端用户,手机 、IoT设备产生的数据源源不断,设备的智能化服务需要我们对这些数据做更深层次的挖掘。海量的数据如何低成本存储、高效利用是大数据部门必须要解决的问题。目前业界流行的解决方案是数据湖,本次Xiaochun He老师介绍的OPPO自研数据湖存储系统CBFS在很大程度上可 zz~~ 3年前 (2021-09-24) 459℃ 0评论2喜欢
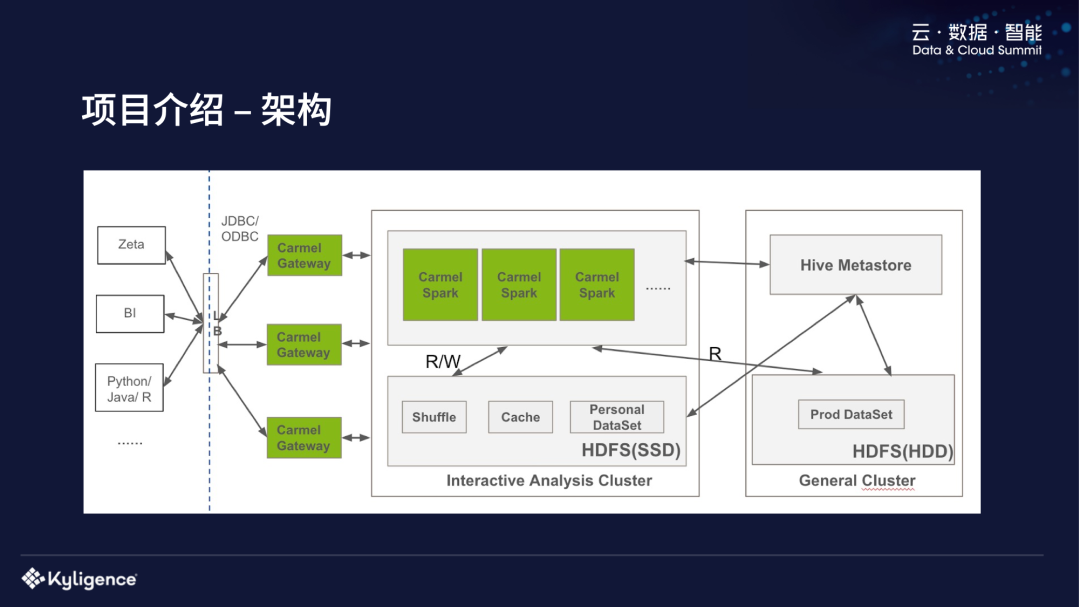
系统介绍我们这个系统的名字叫 Carmel,它是基于开源的 Hadoop 和 Spark 来替换传统的数据仓库,我们是 2019 年开始做我们这个项目的,当时是基于 Spark 2.3.1,最近刚刚升到 Spark 3.0。面临的主要技术挑战,第一个是功能方面的缺失,包括访问控制,还有一些 Update 和 Delete 的支持;在性能方面跟传统数仓,特别是交互式的分析查询中性 zz~~ 3年前 (2021-09-24) 672℃ 0评论2喜欢
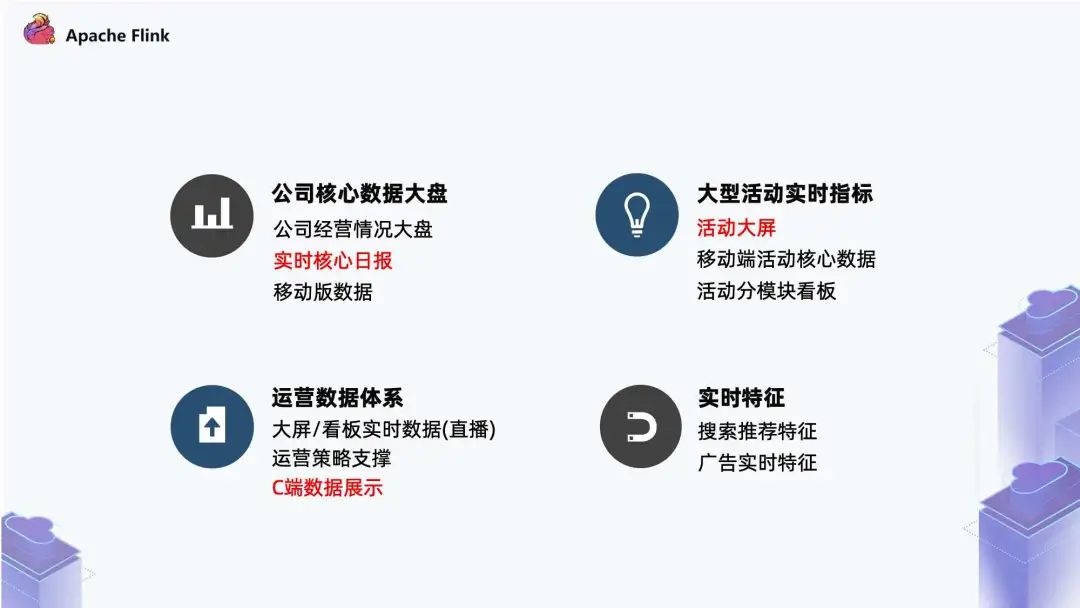
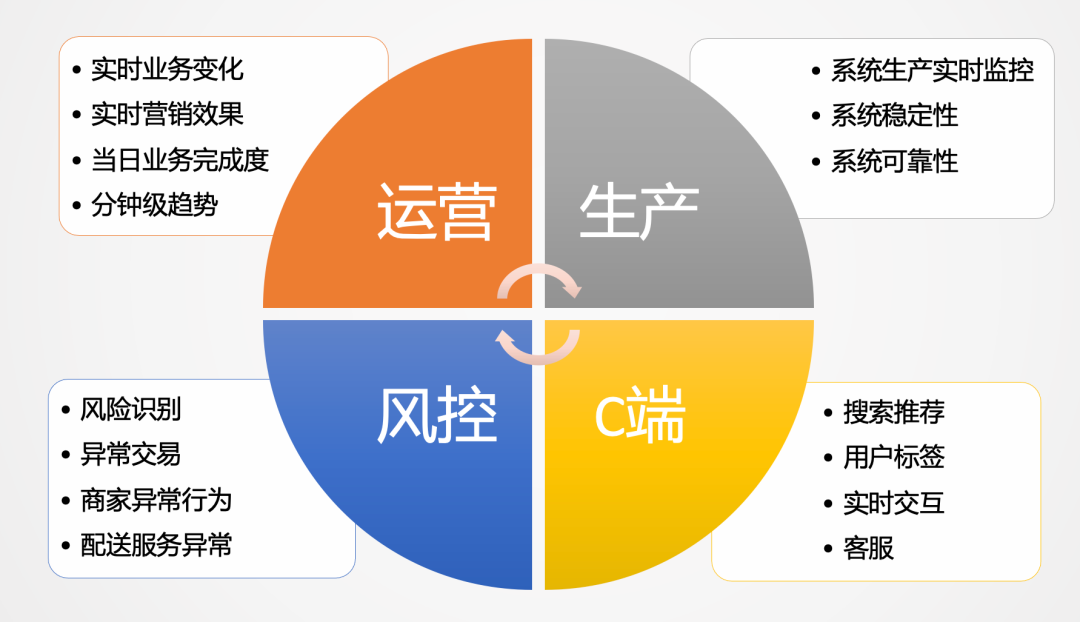
一、快手实时计算场景快手业务中的实时计算场景主要分为四块: 公司级别的核心数据:包括公司经营大盘,实时核心日报,以及移动版数据。相当于团队会有公司的大盘指标,以及各个业务线,比如视频相关、直播相关,都会有一个核心的实时看板; 大型活动实时指标:其中最核心的内容是实时大屏。例如快手的春晚 zz~~ 3年前 (2021-09-24) 791℃ 0评论5喜欢
什么是数据迁移Apache Kafka 对于数据迁移的官方说法是分区重分配。即重新分配分区在集群的分布情况。官方提供了kafka-reassign-partitions.sh脚本来执行分区重分配操作。其底层实现主要有如下三步: 通过副本复制的机制将老节点上的分区搬迁到新的节点上。 然后再将Leader切换到新的节点。 最后删除老节点上的分区。重分 zz~~ 3年前 (2021-09-24) 947℃ 0评论5喜欢
本文主要介绍一种通用的实时数仓构建的方法与实践。实时数仓以端到端低延迟、SQL标准化、快速响应变化、数据统一为目标。美团外卖数据智能组总结的最佳实践是:一个通用的实时生产平台跟一个通用交互式实时分析引擎相互配合,同时满足实时和准实时业务场景。两者合理分工,互相补充,形成易开发、易维护且效率高的流 zz~~ 3年前 (2021-09-24) 622℃ 0评论2喜欢
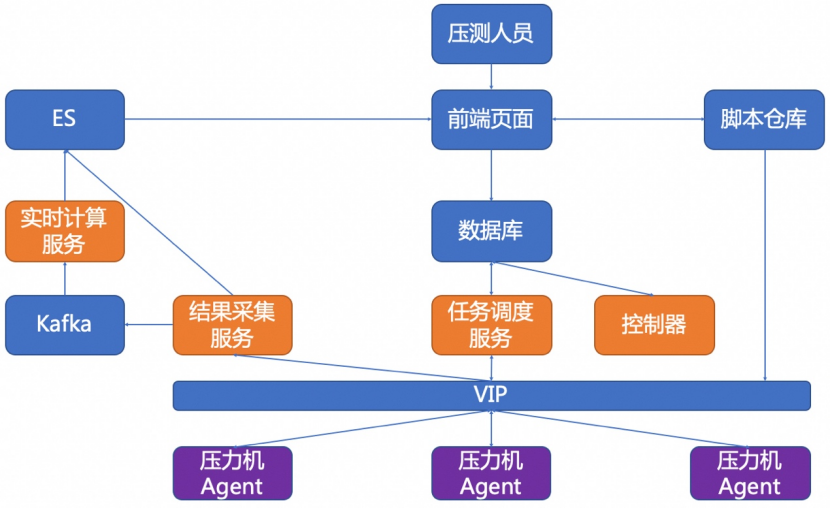
导读:压测是目前科技企业及传统企业进行系统容量评估、容量规划的最佳实践方式,本文将基于京东ForceBot平台在大促(京东618、京东双11)备战中的实践历程,给大家分享平台在压测方面的技术变革。ForceBot平台是一款分布式性能测试平台,能够为全链路压测构造千万量级的压测流量,并结合全域流量录制回放、瞬时发压、智能寻点 zz~~ 3年前 (2021-09-24) 331℃ 0评论1喜欢
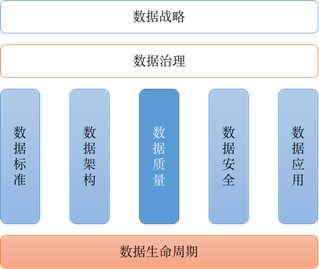
大数据平台的核心理念是构建于业务之上,用数据为业务创造价值。大数据平台的搭建之初,优先满足业务的使用需求,数据质量往往是被忽视的一环。但随着业务的逐渐稳定,数据质量越来越被人们所重视。千里之堤,溃于蚁穴,糟糕的数据质量往往就会带来低效的数据开发,不准确的数据分析,最终导致错误的业务决策。而 zz~~ 3年前 (2021-09-24) 285℃ 0评论2喜欢