全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于美国时间 2022 年 6 月 16 日 宣布,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)。 以下内容译自 Apache Doris 官网(https://doris.apache.org/ )。Apache Doris 是一个基于 MPP 的现代化、高性能、实时的分析型数据库,以极速易用的 3年前 (2022-06-16) 733℃ 0评论2喜欢
一个功能健全的kafka集群可以处理相当大的数据量,由于消息系统是很多大型应用的基石,因此broker集群在性能上的缺陷,都会引起整个应用栈的各种问题。Kafka的度量指标主要有以下三类:1.Kafka服务器(Kafka)指标2.生产者指标3.消费者指标另外,由于Kafka的状态靠Zookeeper来维护,对于Zookeeper性能的监控也成为了整个Ka 3年前 (2022-05-01) 1517℃ 0评论0喜欢
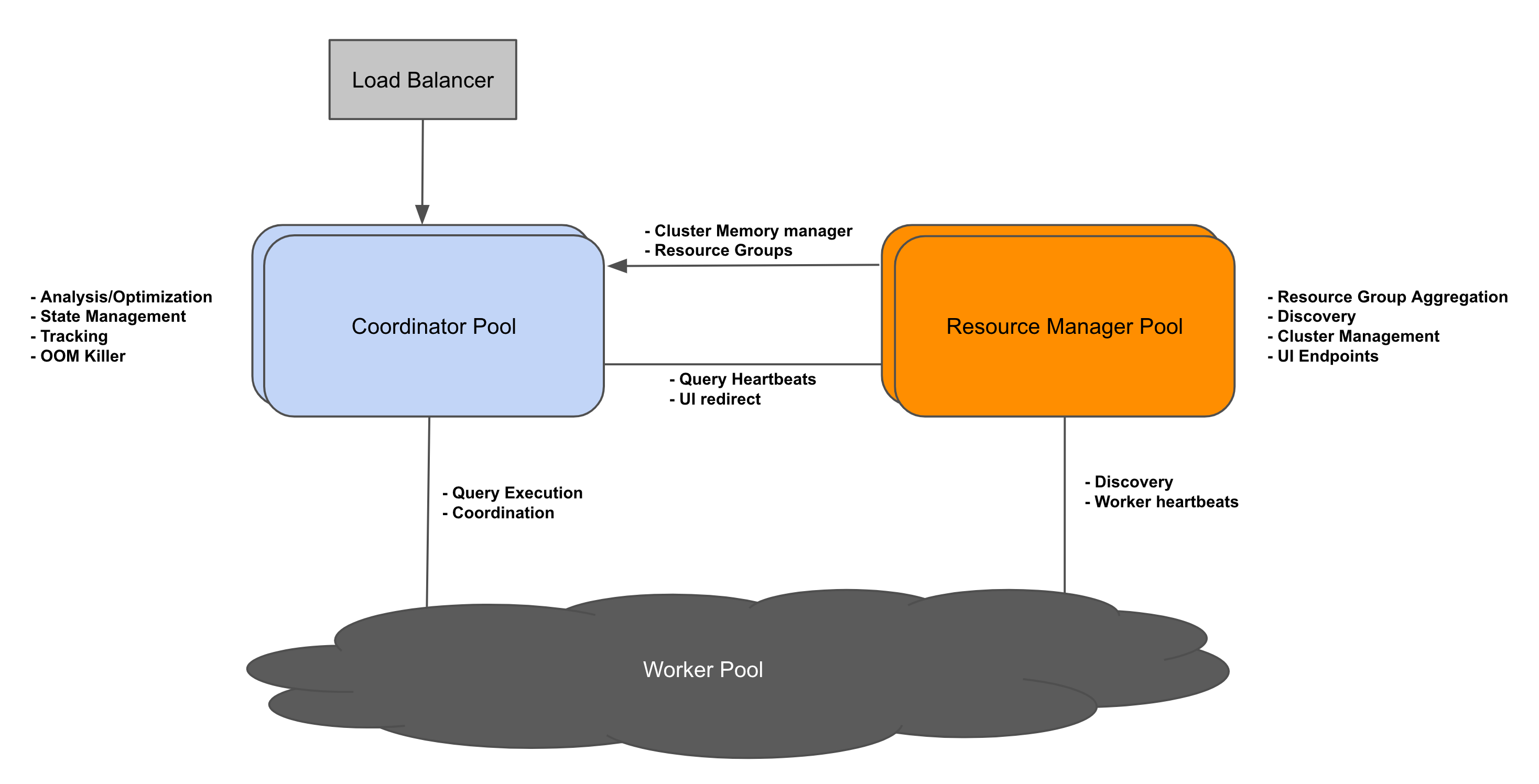
背景Presto 的架构最初只支持一个 coordinator 和多个 workers。多年来,这种方法一直很有效,但也带来了一些新挑战。使用单个 coordinator,集群可以可靠地扩展到一定数量的 worker。但是运行复杂、多阶段查询的大集群可能会使供应不足的 coordinator 不堪重负,因此需要升级硬件来支持工作负载的增加。单个 coordinator 存在单点故障 3年前 (2022-04-22) 1025℃ 0评论1喜欢
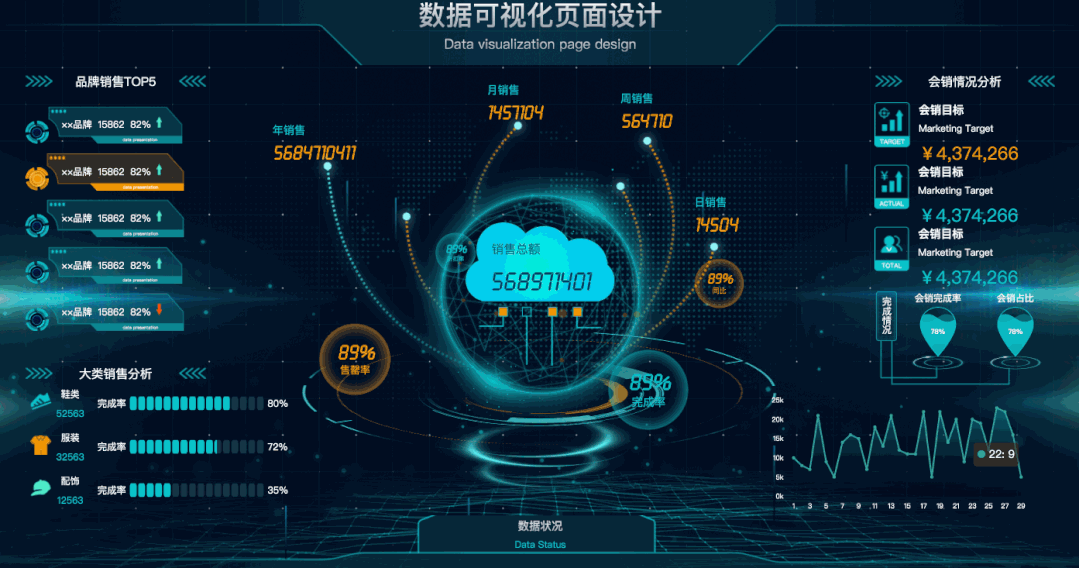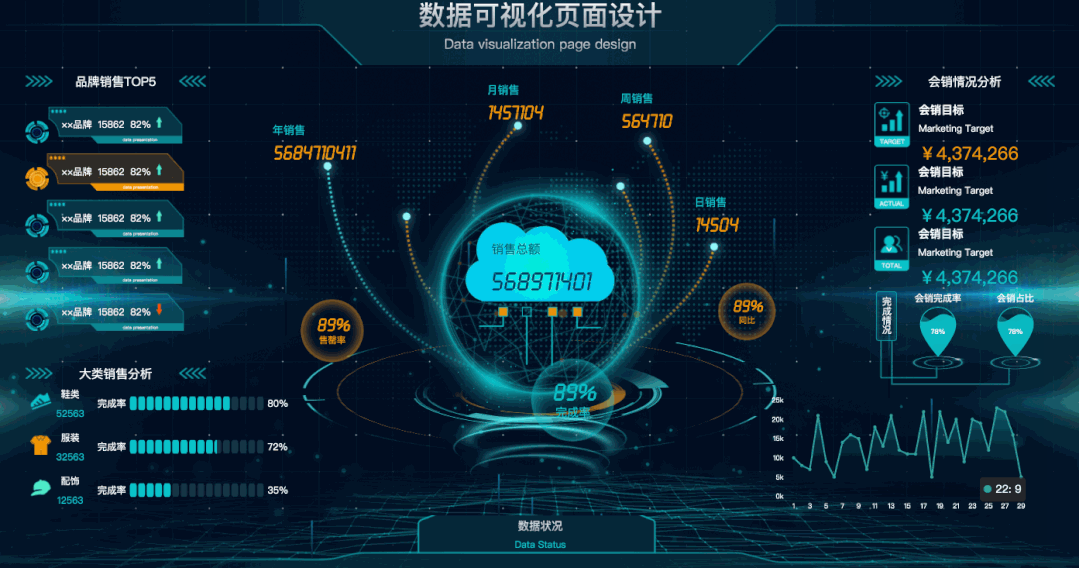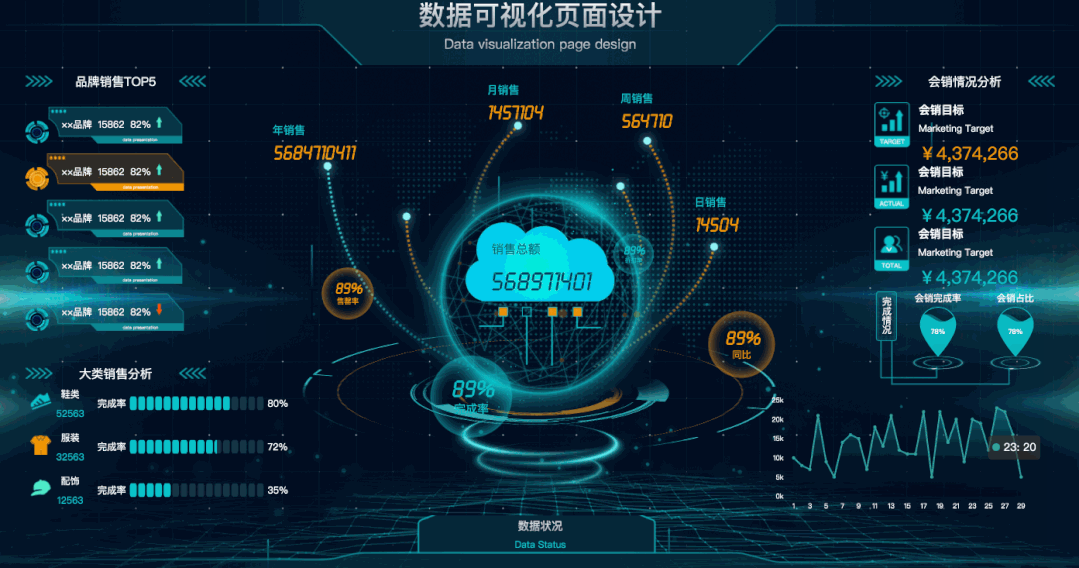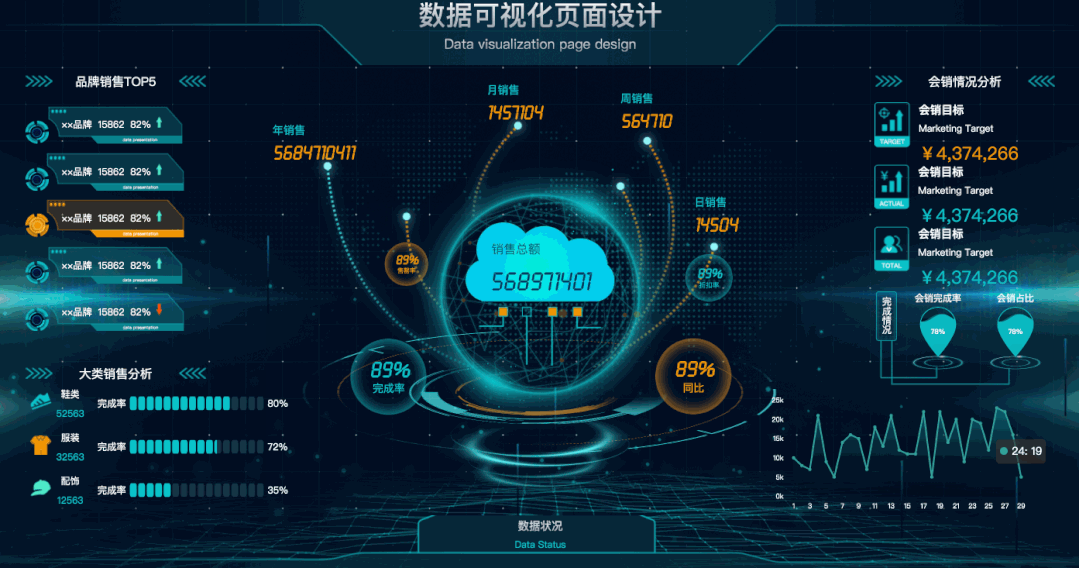
今天给大家分享30款开源的可视化大屏(含源码)。下载到本地后,直接运行文件夹中的index.html,即可看到大屏。01 数据可视化页面设计有动画效果,显得高大上!主要图表:柱状图、水球图、折线图等。02 数据可视化演示系统不仅有动画效果,还有科技感光效。主要图表:柱状图、折线图、饼图、地图等 4年前 (2021-12-23) 4221℃ 0评论4喜欢
分享的内容主要包括三个内容:1)Kyuubi是什么?介绍Kyuubi的核心功能以及Kyuubi在各个使用场景中的解决方案;2)Kyuubi在网易内部的定位、角色和实际使用场景;3)通过案例分享Kyuubi在实际过程中如何起到作用。Kyuubi是什么开源Kyuubi是网易秉持开源理念的作品。Kyuubi是网易第一款贡献给Apache并进入孵化的开源项目。Kyuubi主要 4年前 (2021-12-23) 2549℃ 0评论4喜欢
Linux(vi/vim)一般模式语法功能描述yy复制光标当前一行y数字y复制一段(从第几行到第几行)p箭头移动到目的行粘贴u撤销上一步dd删除光标当前行d数字d删除光标(含)后多少行x删除一个字母,相当于delX删除一个字母,相当于Backspaceyw复制一个词dw删除一个词 4年前 (2021-12-01) 202℃ 0评论0喜欢
背景 随着公司这两年业务的迅速扩增,业务数据量和数据处理需求也是呈几何式增长,这对底层的存储和计算等基础设施建设提出了较高的要求。本文围绕计算集群资源使用和资源调度展开,将带大家了解集群资源调度的整体过程、面临的问题,以及我们在底层所做的一系列开发优化工作。资源调度框架---YarnYarn的总体结 4年前 (2021-11-16) 614℃ 0评论0喜欢
背景随着同程旅行业务和数据规模越来越大,原有的机房不足以支撑未来几年的扩容需求,同时老机房的保障优先级也低于新机房。为了不受限于机房的压力,公司决定进行机房迁移。为了尽快完成迁移,需要1个月内完成上百PB数据量的集群迁移,迁移过程不允许停止服务。目前HADOOP集群主要有多个2.X版本,2019年升级到联 4年前 (2021-11-16) 706℃ 0评论1喜欢
在 Apache 软件基金会近期发布的年度报告中,Apache Flink 再次跻身最活跃项目前 5 名!该项目最新发布的 1.14.0 版本同样体现了其非凡的活跃力,囊括了来自超过 200 名贡献者的 1000 余项贡献。整个社区为项目的推进付出了持之以恒的努力,我们引以为傲。新版本在 SQL API、更多连接器支持、Checkpoint 机制、PyFlink 等多个方面带来了大 4年前 (2021-10-09) 985℃ 0评论5喜欢
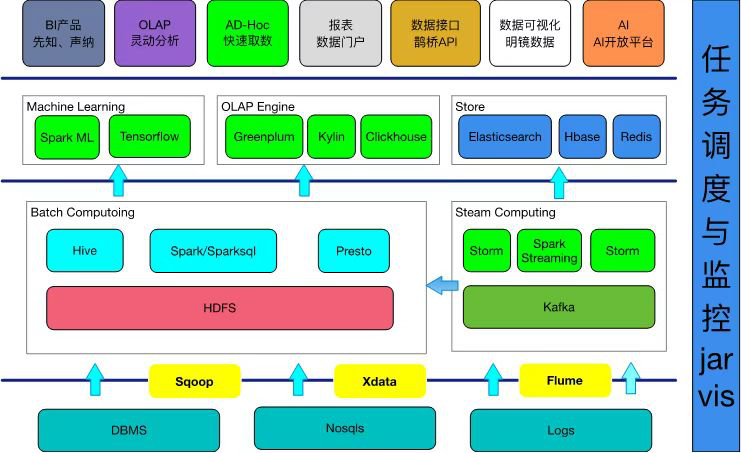
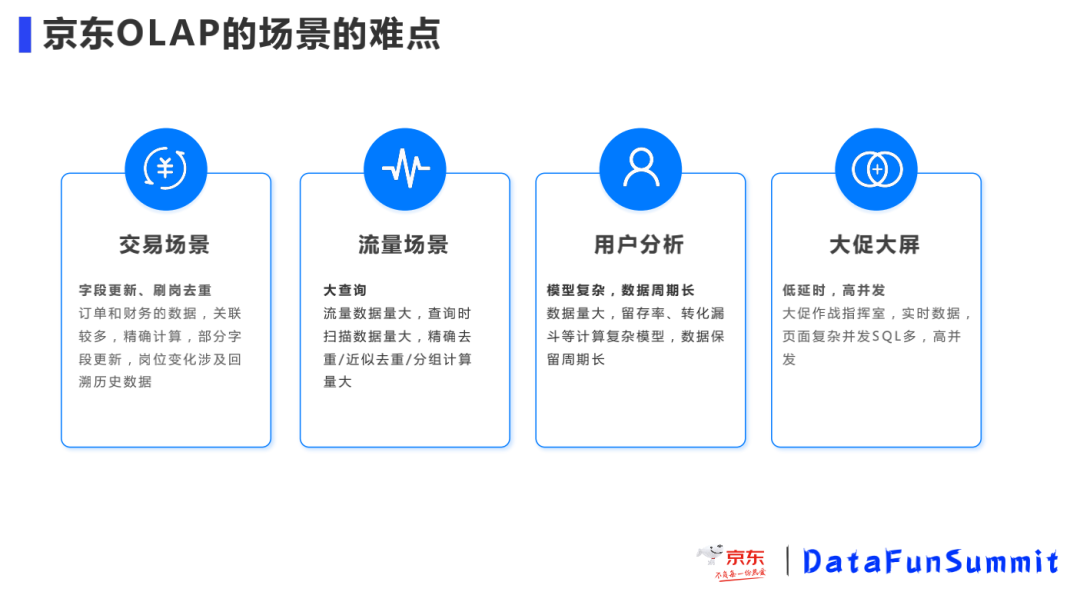
导读:京东OLAP采取ClickHouse为主Doris为辅的策略,有3000台服务器,每天亿次查询万亿条数据写入,广泛服务于各个应用场景,经过历次大促考验,提供了稳定的服务。本文介绍了ClickHouse在京东的高可用实践,包括选型过程、集群部署、高可用架构、问题和规划。01应用场景和选型京东数据分析的场景非常多,在交易、流量、大屏 4年前 (2021-10-08) 1225℃ 0评论3喜欢