本文作者:李寅威,从事大数据、机器学习方面的工作,目前就职于CVTE联系方式:微信(coridc),邮箱(251469031@qq.com)原文链接: Spark2.1.0 + CarbonData1.0.0集群模式部署及使用入门1 引言 Apache CarbonData是一个面向大数据平台的基于索引的列式数据格式,由华为大数据团队贡献给Apache社区,目前最新版本是1.0.0版。介于 8年前 (2017-03-13) 3542℃ 0评论11喜欢
本书将向您展示如何利用Python的强大功能并将其用于Spark生态系统中。您将首先了解Spark 2.0的架构以及如何为Spark设置Python环境。通过本书,你将会使用Python操作RDD、DataFrames、MLlib以及GraphFrames等;在本书结束时,您将对Spark Python API有了全局的了解,并且学习到如何使用它来构建数据密集型应用程序。通过本书你将学习到以下的知识 8年前 (2017-03-09) 10859℃ 0评论12喜欢
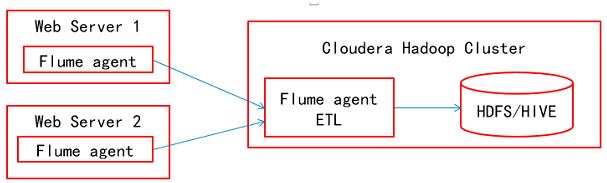
本文来自徐宇辉(微信号:xuyuhui263)的投稿,目前在中国移动从事数字营销的业务支撑工作,感谢他的文章。Apache Flume简介Apache Flume是一个Apache的开源项目,是一个分布的、可靠的软件系统,主要目的是从大量的分散的数据源中收集、汇聚以及迁移大规模的日志数据,最后存储到一个集中式的数据系统中。Apache Flume是由 8年前 (2017-03-08) 7315℃ 0评论19喜欢
本书将为您简要介绍ElasticSearch的基础知识以及Elasticsearch 5的新功能。通过本书将学习到Elasticsearch的基本功能和高级功能,例如查询,索引,搜索和修改数据。本书还介绍了一些高级知识,包括聚合,索引控制,分片,复制和聚类。中间部分介绍了ElasticSearch集群相关的知识,包括备份、监控、恢复等。读完本书,您将掌握Elastics 8年前 (2017-02-28) 5008℃ 0评论13喜欢
Learning Apache Flink又名Mastering Apache Flink,是由Tanmay Deshpande所著,2017年02月在Packt出版,全书共280页。这本书是学习Apache Flink进行批处理和流数据处理的入门指南。本书首先介绍Apache Flink生态系统,然后介绍如何设置Apache Flink,并使用DataSet和DataStream API分别处理静态数据和流数据。本书将探讨如何在数据集上使用Table API。在本书的 8年前 (2017-02-24) 16430℃ 0评论19喜欢
Introduce Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。 容错机制通过持续创建分布式数据流的快照来实现。对于状态占用空间小的流应用,这些快照非常轻量,可以高频率创建而对性能影 9年前 (2017-02-08) 4610℃ 0评论7喜欢
如果你对Hadoop有基本的了解,并希望将您的知识用于企业的大数据解决方案,那你就来阅读本书吧。本书提供了六个使用Hadoop生态系统解决实际问题的例子,使得您的Hadoop知识提升到一个新的水平。本书作者:Anurag Shrivastava,由Packt出版社于2016年9月出版,全书共316页。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关 9年前 (2016-12-20) 3260℃ 1评论6喜欢
本书介绍了如何使用 Spark Streaming 开发应用程序已经一些最佳实践。适合数据科学家、大数据专家、BI分析以及数据架构师阅读。全书名称:Pro Spark Streaming The Zen of Real-Time Analytics Using Apache Spark,作者Nabi, Zubair,由Apress于2016-07-01出版,全书共231页。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog 9年前 (2016-12-18) 4624℃ 0评论6喜欢
本书是《Hadoop权威指南》第三版,新版新特色,内容更详细。本书是为程序员写的,可帮助他们分析任何大小的数据集。本书同时也是为管理员写的,帮助他们了解如何设置和运行Hadoop集群。 本书通过丰富的案例学习来解释Hadoop的幕后机理,阐述了Hadoop如何解决现实生活中的具体问题。第3版覆盖Hadoop的新动态,包括新增 9年前 (2016-12-16) 17488℃ 0评论43喜欢
本书作者Venkat Ankam,由Packt Publishing出版社在2016年09月发行,全书供326页。本书基于Spark 2.0和Hadoop 2.7版本介绍,是适合数据分析师和数据科学家的参考手册,当然也适合那些想入门的人。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[code lang="bash"]Chapter 1: Big Data Analytics at a 10 9年前 (2016-11-21) 4811℃ 0评论6喜欢


![[电子书]Learning PySpark PDF下载](https://www.iteblog.com/pic/books/Learning_PySpark_iteblog.jpg)
![[电子书]Mastering Elasticsearch 5.x - Third Edition PDF下载](https://www.iteblog.com/pic/elastic/Mastering_Elasticsearch_5.x-Third_Edition_iteblog.jpg)
![[电子书]Learning Apache Flink PDF下载](https://www.iteblog.com/pic/flink/Mastering_Apache_Flink_iteblog.png)

![[电子书]Hadoop Blueprints pdf下载](https://www.iteblog.com/pic/Hadoop_Blueprints-iteblog.jpg)
![[电子书]Pro Spark Streaming pdf电子书下载](https://www.iteblog.com/pic/Pro_Spark_Streaming.jpg)
![[电子书]Hadoop权威指南第3版中文版PDF下载](https://www.iteblog.com/pic/Hadoop_the_definitive_guide_Third_Edition.jpg)
![[电子书]Big Data Analytics pdf下载](https://www.iteblog.com/pic/big-data-analytics-iteblog.jpg)