本书于2017-03由Packt Publishing出版,作者Muhammad Asif Abbasi,全书356页。通过本书你将学到以下知识:Get an overview of big data analytics and its importance for organizations and data professionalsDelve into Spark to see how it is different from existing processing platformsUnderstand the intricacies of various file formats, and how to process them with Apache Spark.Realize how to deploy Spark with YAR 8年前 (2017-07-26) 14791℃ 0评论29喜欢
引言Join是SQL语句中的常用操作,良好的表结构能够将数据分散在不同的表中,使其符合某种范式,减少表冗余、更新容错等。而建立表和表之间关系的最佳方式就是Join操作。SparkSQL作为大数据领域的SQL实现,自然也对Join操作做了不少优化,今天主要看一下在SparkSQL中对于Join,常见的3种实现。Spark SQL中Join常用的实现Broadc 8年前 (2017-07-09) 8372℃ 0评论16喜欢
本书于2017-05由Packt Publishing出版,作者Rishi Yadav,全书294页。从书名就可以看出这是一本讲解技巧的书。本书副标题:Over 70 recipes to help you use Apache Spark as your single big data computing platform and master its libraries。本书适合数据工程师,数据科学家以及那些想使用Spark的读者。阅读本书之前最好有Scala的编程基础。通过本书你将学到以下知识 8年前 (2017-07-07) 4885℃ 0评论16喜欢
本书作者:Bill Chambers、Matei Zaharia、Shrey Mehrotra,由O'Reilly Media出版社于2017年1月出版,全书共450页。这里提供的是本书的 Early Release 版本,正式版尚未出版,而且目前还没有完整的内容。由于这本书有Matei Zaharia参与编写,所有很值得一看。通过本书将学习到以下的知识:Get a gentle overview of big data and SparkLearn about DataFrames, SQL, a 8年前 (2017-06-22) 6875℃ 0评论26喜欢
本书作者:Rajdeep Dua、Manpreet Singh Ghotra、 Nick Pentreath,由Packt出版社于2017年04月出版,全书共532页。本书是2015年02月出版的Machine Learning with Spark的第二版。通过本书将学习到以下的知识:Get hands-on with the latest version of Spark MLCreate your first Spark program with Scala and PythonSet up and configure a development environment for Spark on your own computer, as well 8年前 (2017-05-27) 4580℃ 0评论14喜欢
本书作者:Hanish Bansal、Saurabh Chauhan、Shrey Mehrotra,由Packt出版社于2016年4月出版,全书共486页。通过本书将学习到以下的知识:(1)、Learn different features and offering on the latest Hive(2)、Understand the working and structure of the Hive internals(3)、Get an insight on the latest development in Hive framework(4)、Grasp the concepts of Hive Data Model(5)、M 8年前 (2017-05-26) 6492℃ 0评论22喜欢
本书由Andrew Morgan所著,全书共560页;Packt Publishing出版社于2017年03月出版。通过本书你将学习到以下的知识: 1、Learn the design patterns that integrate Spark into industrialized data science pipelines 2、See how commercial data scientists design scalable code and reusable code for data science services 3、Explore cutting edge data science methods so that you can study tre 8年前 (2017-04-17) 3577℃ 2评论8喜欢
本书由Vaibhav Kohli, Rajdeep Dua, John Wooten所著,全书共290页;Packt Publishing出版社于2017年03月出版。通过本书你将学习到以下的知识: 1、Install Docker ecosystem tools and services, Microservices and N-tier applications 2、Create re-usable, portable containers with help of automation tools 3、Network and inter-link containers 4、Attach volumes securely to containe 8年前 (2017-04-05) 1940℃ 2评论7喜欢
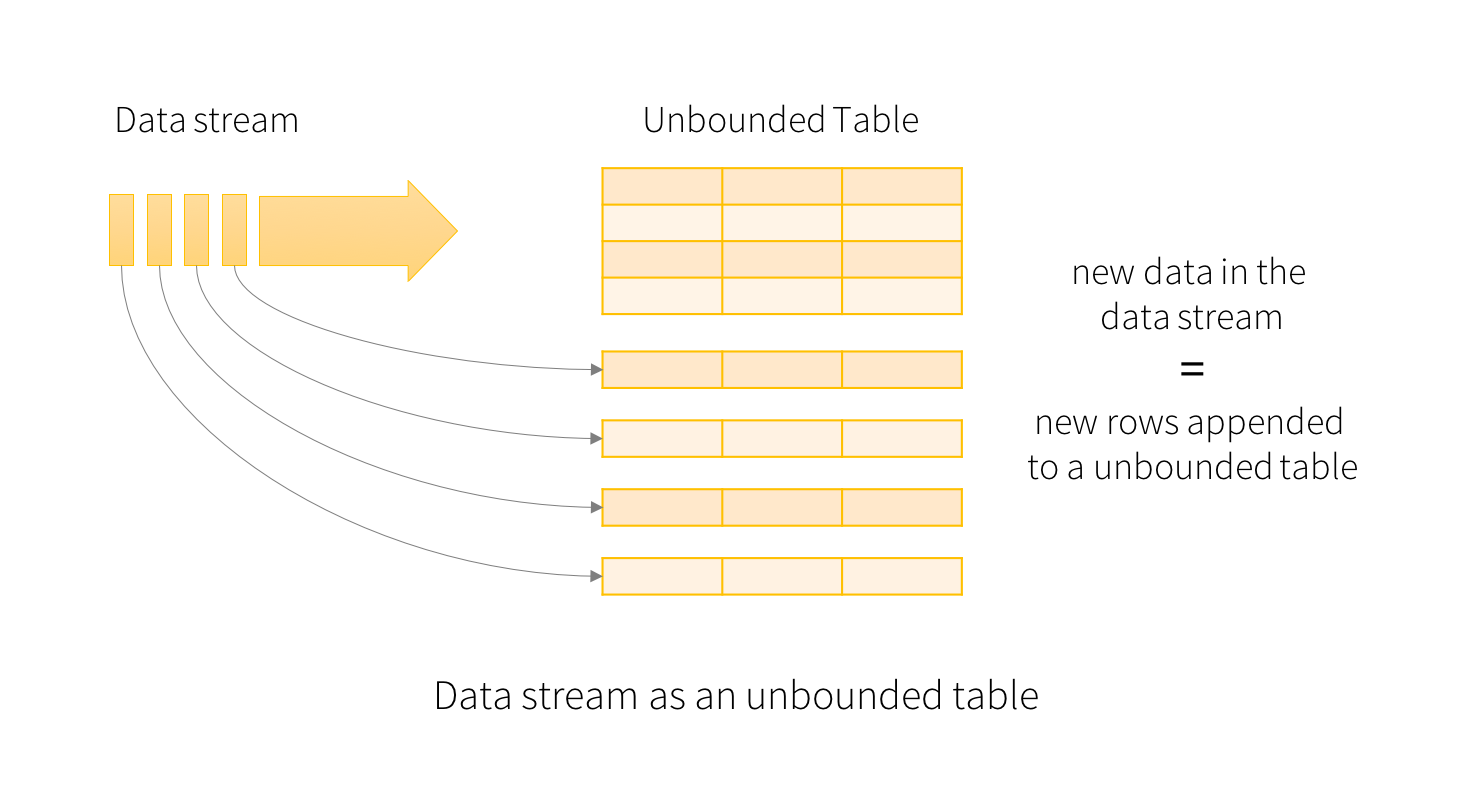
概览 Structured Streaming 是一个可拓展,容错的,基于Spark SQL执行引擎的流处理引擎。使用小量的静态数据模拟流处理。伴随流数据的到来,Spark SQL引擎会逐渐连续处理数据并且更新结果到最终的Table中。你可以在Spark SQL上引擎上使用DataSet/DataFrame API处理流数据的聚集,事件窗口,和流与批次的连接操作等。最后Structured Streaming 8年前 (2017-03-22) 10835℃ 2评论11喜欢
HDFS Federation为HDFS系统提供了NameNode横向扩容能力。然而作为一个已实现多年的解决方案,真正应用到已运行多年的大规模集群时依然存在不少的限制和问题。本文以实际应用场景出发,介绍了HDFS Federation在美团点评的实际应用经验。 背景 2015年10月,经过一段时间的优化与改进,美团点评HDFS集群稳定性和性能有显著 8年前 (2017-03-17) 2078℃ 0评论7喜欢

![[电子书]Learning Apache Spark 2 PDF下载](https://www.iteblog.com/pic/books/Learning-Apache-Spark-2_iteblog.png)

![[电子书]Apache Spark 2.x Cookbook, 2nd Edition PDF下载](https://www.iteblog.com/pic/books/apache-spark-2x-cookbook_iteblog.png)
![[电子书]Spark: The Definitive Guide Early Release PDF下载](https://www.iteblog.com/pic/books/Spark_The_Definitive_Guide_iteblog.jpg)
![[电子书]Machine Learning with Spark Second Edition PDF下载](https://www.iteblog.com/pic/books/Machine_Learning_with_Spark_Second_Edition_iteblog.jpg)
![[电子书]Apache Hive Cookbook PDF下载](https://www.iteblog.com/pic/Apache_Hive_Cookbook-iteblog.jpg)
![[电子书]Mastering Spark for Data Science PDF下载](https://www.iteblog.com/pic/books/mastering-spark-data-science_iteblog.jpg)
![[电子书]Troubleshooting Docker PDF下载](https://www.iteblog.com/pic/books/Troubleshooting_Docker_iteblog.png)