当前 Spark 计算引擎能够利用一些统计信息选择合适的 Join 策略(关于 Spark 支持的 Join 策略可以参见每个 Spark 工程师都应该知道的五种 Join 策略),但是由于各种原因,比如统计信息缺失、统计信息不准确等原因,Spark 给我们选择的 Join 策略不是正确的,这时候我们就可以人为“干涉”,Spark 从 2.2.0 版本开始(参见SPARK-16475),支 w397090770 4年前 (2020-09-15) 3542℃ 0评论3喜欢
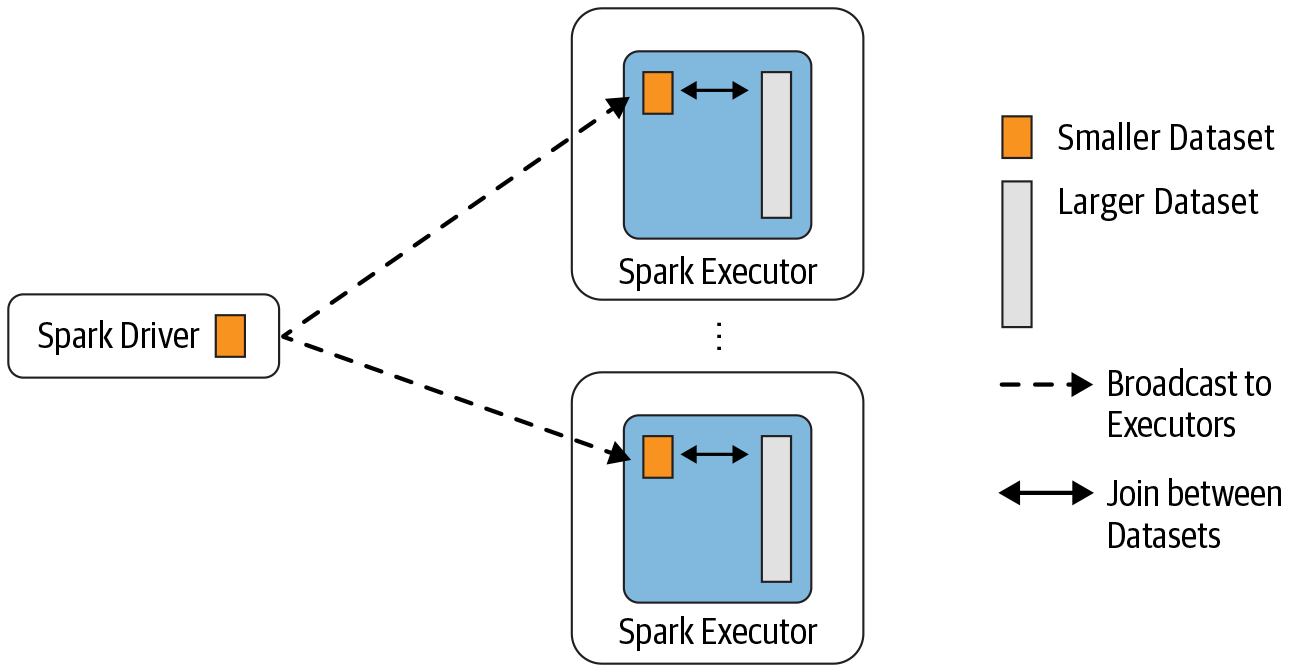
数据分析中将两个数据集进行 Join 操作是很常见的场景。在 Spark 的物理计划(physical plan)阶段,Spark 的 JoinSelection 类会根据 Join hints 策略、Join 表的大小、 Join 是等值 Join(equi-join) 还是不等值(non-equi-joins)以及参与 Join 的 key 是否可以排序等条件来选择最终的 Join 策略(join strategies),最后 Spark 会利用选择好的 Join 策略执行最 w397090770 4年前 (2020-09-13) 5201℃ 0评论13喜欢
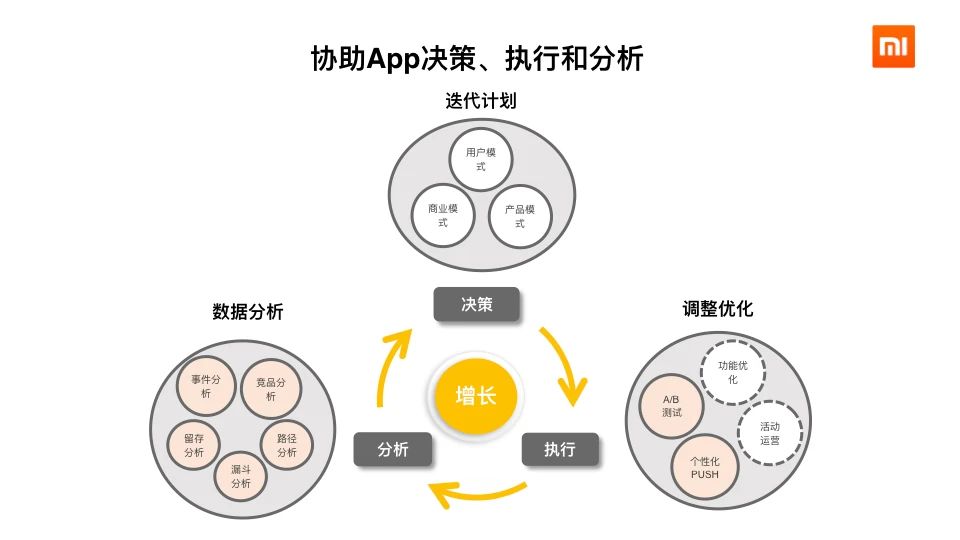
1、背景随着小米互联网业务的发展,各个产品线利用用户行为数据对业务进行增长分析的需求越来越迫切。显然,让每个业务产品线都自己搭建一套增长分析系统,不仅成本高昂,也会导致效率低下。我们希望能有一款产品能够帮助他们屏蔽底层复杂的技术细节,让相关业务人员能够专注于自己的技术领域,从而提高工作效率。 w397090770 4年前 (2020-09-13) 1269℃ 0评论2喜欢
在实践经验中,我们知道数据总是在不断演变和增长,我们对于这个世界的心智模型必须要适应新的数据,甚至要应对我们从前未知的知识维度。表的 schema 其实和这种心智模型并没什么不同,需要定义如何对新的信息进行分类和处理。这就涉及到 schema 管理的问题,随着业务问题和需求的不断演进,数据结构也会不断发生变化。 w397090770 4年前 (2020-09-12) 615℃ 0评论0喜欢
Apache Spark 3.0.0 正式版是2020年6月18日发布的,其为我们带来大量新功能,很多功能加快了数据的计算速度。但是遗憾的是,这个版本并非稳定版。不过就在昨天,Apache Spark 3.0.1 版本悄悄发布了(好像没看到邮件通知)!值得大家高兴的是,这个版本是稳定版,官方推荐所有 3.0 的用户升级到这个版本。Apache Spark 3.0 增加了很多 w397090770 4年前 (2020-09-10) 1292℃ 0评论0喜欢
Efficient processing of big data, especially with Spark, is really all about how much memory one can afford, or how efficient use one can make of the limited amount of available memory. Efficient memory utilization, however, is not what one can take for granted with default configuration shipped with Spark and Yarn. Rather, it takes very careful provisioning and tuning to get as much as possible from the bare metal. In this post I’ll w397090770 4年前 (2020-09-09) 983℃ 0评论0喜欢
我们可以在初始化 SparkSession 的时候进行一些设置:[code lang="scala"]import org.apache.spark.sql.SparkSessionval spark: SparkSession = SparkSession.builder .master("local[*]") .appName("My Spark Application") .config("spark.sql.warehouse.dir", "c:/Temp") (1) .getOrCreateSets spark.sql.warehouse.dir for the Spark SQL session[/code]也可以使用 SQL SET w397090770 4年前 (2020-09-09) 3381℃ 0评论2喜欢
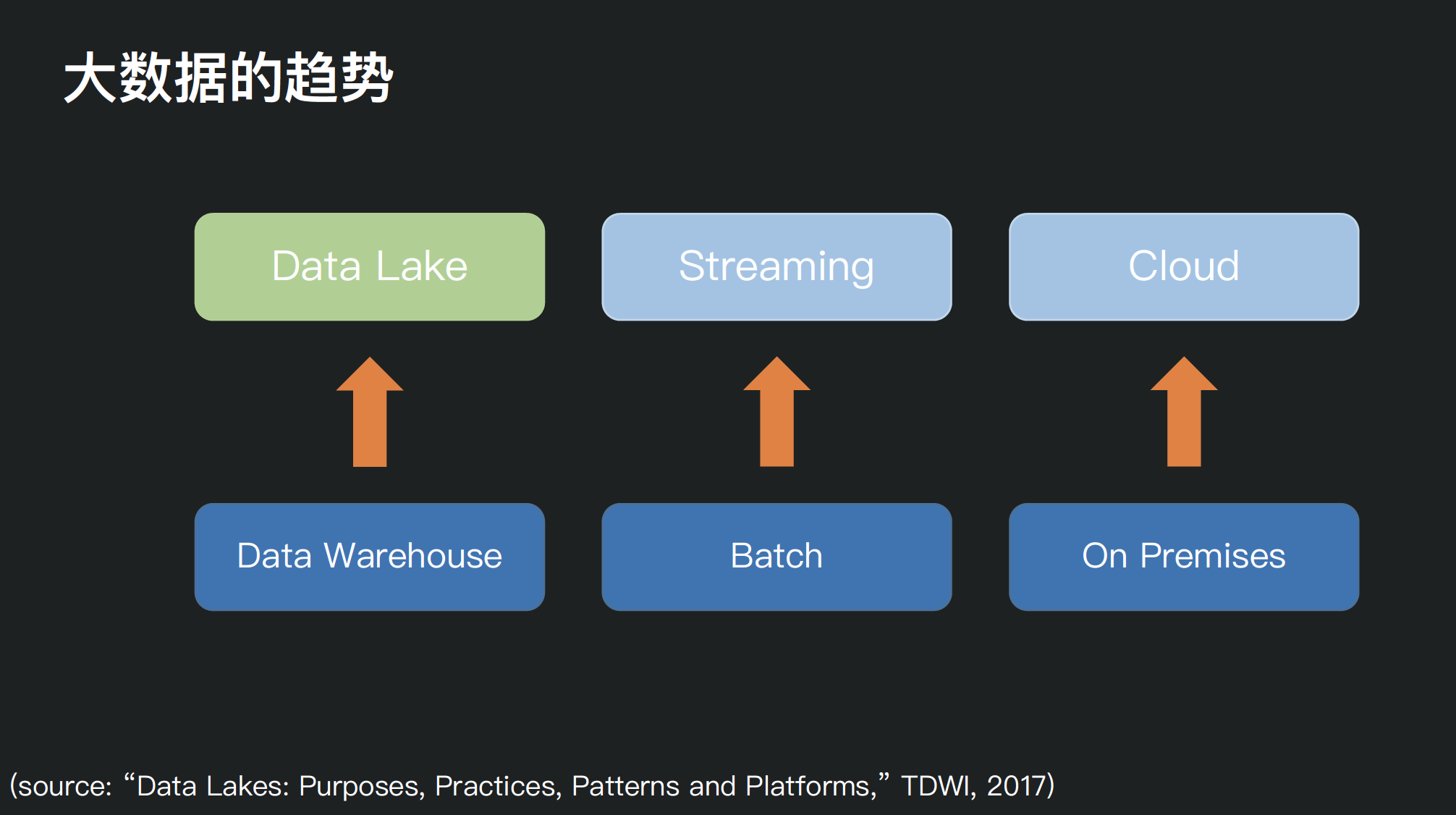
本文资料来自2020年9月5日由快手技术团队主办的快手大数据平台架构技术交流会,分享者邵赛赛,腾讯数据平台部数据湖内核技术负责人,资深大数据工程师,Apache Spark PMC member & committer, Apache Livy PMC member,曾就职于 Hortonworks,Intel 。随着大数据存储和处理需求的多样化,如何构建一个统一的数据湖存储,并在其上进行多种形式 w397090770 4年前 (2020-09-07) 4581℃ 3评论8喜欢
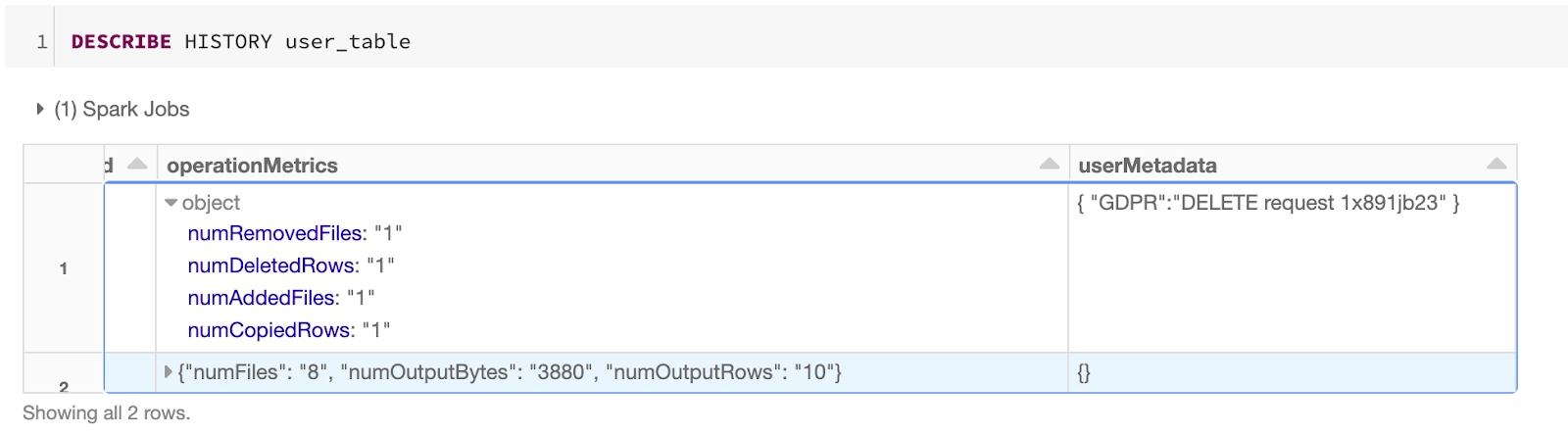
Delta Lake 0.7.0 是随着 Apache Spark 3.0 版本发布之后发布的,这个版本比较重要的特性就是支持使用 SQL 来操作 Delta 表,包括 DDL 和 DML 操作。本文将详细介绍如何使用 SQL 来操作 Delta Lake 表,关于 Delta Lake 0.7.0 版本的详细 Release Note 可以参见这里。使用 SQL 在 Hive Metastore 中创建表Delta Lake 0.7.0 支持在 Hive Metastore 中定义 Delta 表,而且这 w397090770 4年前 (2020-09-06) 1181℃ 0评论0喜欢
《Learning Spark, 2nd Edition》这本书是由 O'Reilly Media 出版社于2020年7月出版的,作者包括 Jules S. Damji, Brooke Wenig, Tathagata Das, Denny Lee。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书介绍第二版已更新包含了 Spark 3.0 的一些东西,本书向数据工程师和数据科学家展示了 Spark 中结构化和统一 w397090770 4年前 (2020-09-03) 2764℃ 0评论10喜欢