

文章目录
背景
Presto 的架构最初只支持一个 coordinator 和多个 workers。多年来,这种方法一直很有效,但也带来了一些新挑战。
- 使用单个 coordinator,集群可以可靠地扩展到一定数量的 worker。但是运行复杂、多阶段查询的大集群可能会使供应不足的 coordinator 不堪重负,因此需要升级硬件来支持工作负载的增加。
- 单个 coordinator 存在单点故障的风险。
为了克服这些挑战,Facebook 提出了一个新的设计:一个分解的协调器(disaggregated coordinator),允许 coordinator 在单个 workers pool 中横向扩展。
架构
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
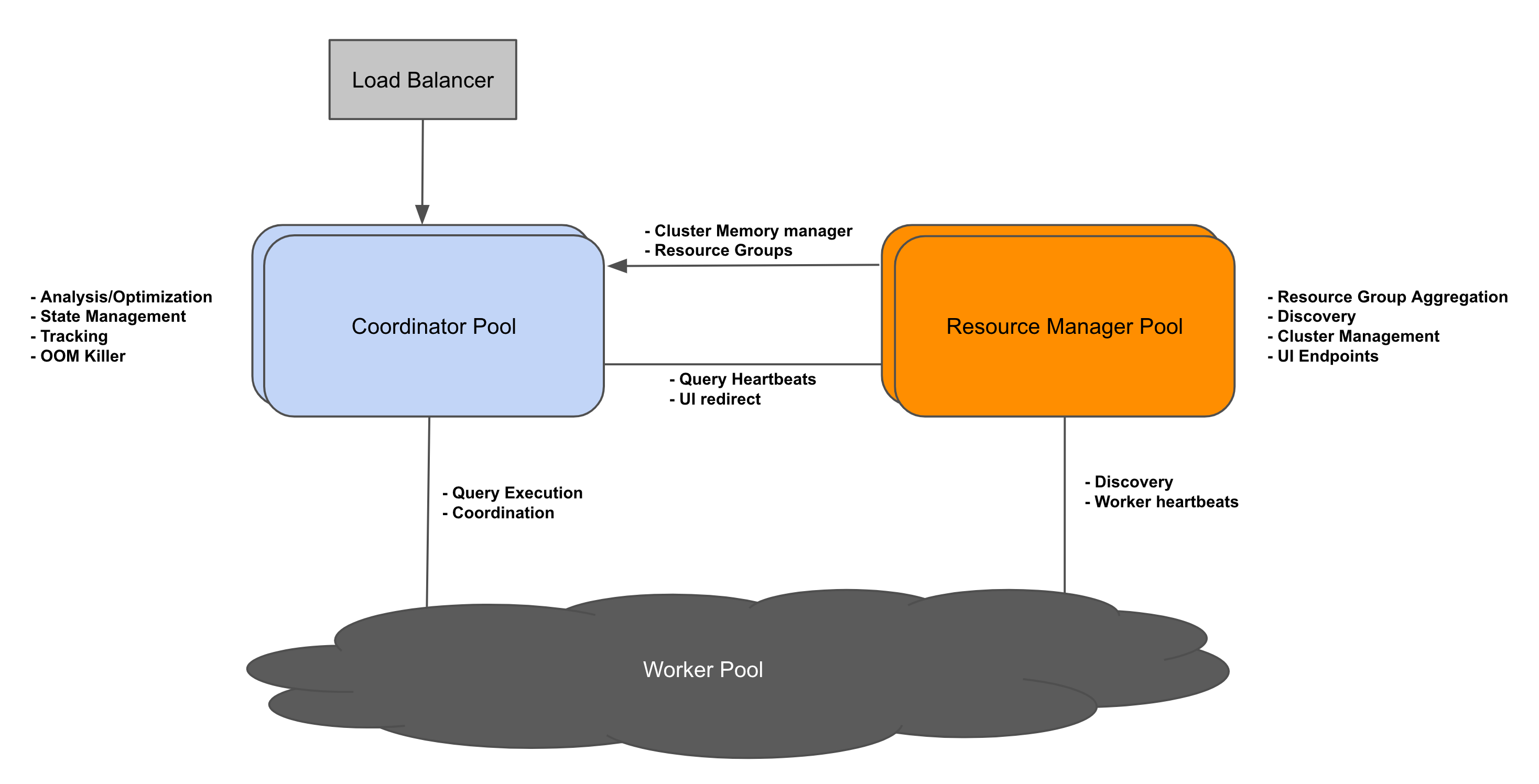
disaggregated coordinator 方案在新组件资源管理器(resource manager)的帮助下支持 coordinators pool。
Resource Manager
资源管理器聚合来自所有 coordinators 和 workers 的数据,并构建集群的全局视图。集群支持多个资源管理器,每个资源管理器充当主资源管理器。discovery service 在每个资源管理器上运行。资源管理器不在查询语句的关键路径上。相反,它是一种互补的过程,可以在短暂的不可用时存活下来。
Coordinator
coordinator 定期向所有资源管理器发送心跳。这些心跳包含有关 coordinator 处理的查询的信息,资源管理器使用这些信息刷新集群的全局视图。coordinator 定期从资源管理器获取聚合的 resource group 信息。
Worker
每个 worker 定期向资源管理器发送包含内存和 cpu 利用率的心跳,资源管理器会跟踪 worker pool 的这些指标。
查询执行流程

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
由于引入了资源管理器,查询执行流程看起来略有不同。
- 查询被提交给集群中的一个 coordinator。
- coordinator 通过解析、分析并将查询分配给给定的 resource group 来准备执行查询。
- 当 coordinator 创建查询时,心跳被发送到每个资源管理器。
- coordinator 定期轮询资源管理器以获取集群级的 resource group 信息。
- coordinator 轮询资源管理器以获取活动 worker 信息,该信息用于查询调度。
- 查询执行的其余部分保持不变。
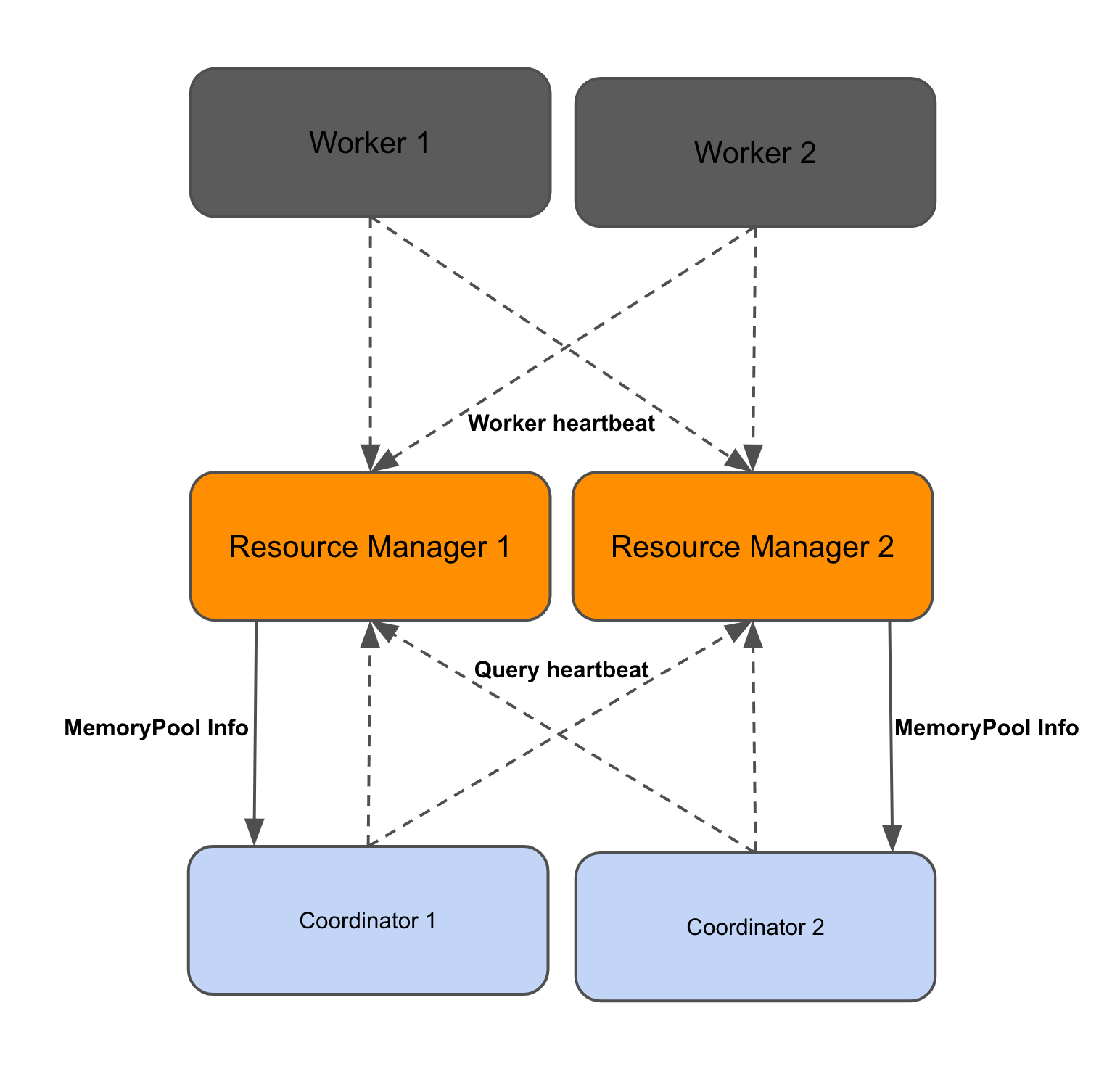
内存管理
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
资源管理器进行 resource group queuing 时需要知道 worker pool 的内存和 cpu 利用率的最新信息。目前,这些信息是由 coordinator 定期收集的。在 disaggregated coordinator 集群设置中,资源管理器接收来自 coordinator 心跳的查询级统计信息,以及来自 worker 心跳的内存池信息。coordinator 会周期性地轮询这些信息,以帮助做出本地决策(例如,排队/运行查询,在集群内存不足时终止查询)。
资源管理

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
资源管理器以 multi-master 模式运行。为了支持这一点,coordinator 向所有资源管理器发布查询更新。资源管理器聚合这些信息。coordinator 轮询资源管理器以获取关于集群中资源组使用情况的最新信息。
资源组一致性模型
disaggregated coordinator 安装中的资源组状态是最终一致性的。虽然在某些场景中,这可能导致接收过多的查询;但在实践中,通过限制资源组只允许在满足某些新鲜度保证时运行查询(而不是之前的每毫秒检查的逻辑),可以缓解这一问题。这可能意味着,如果集群的资源管理器关闭,那么查询可能在 coordinator 的资源组中排队。这是为了确保在资源管理器不可用的情况下,coordinator 不会过度执行查询。
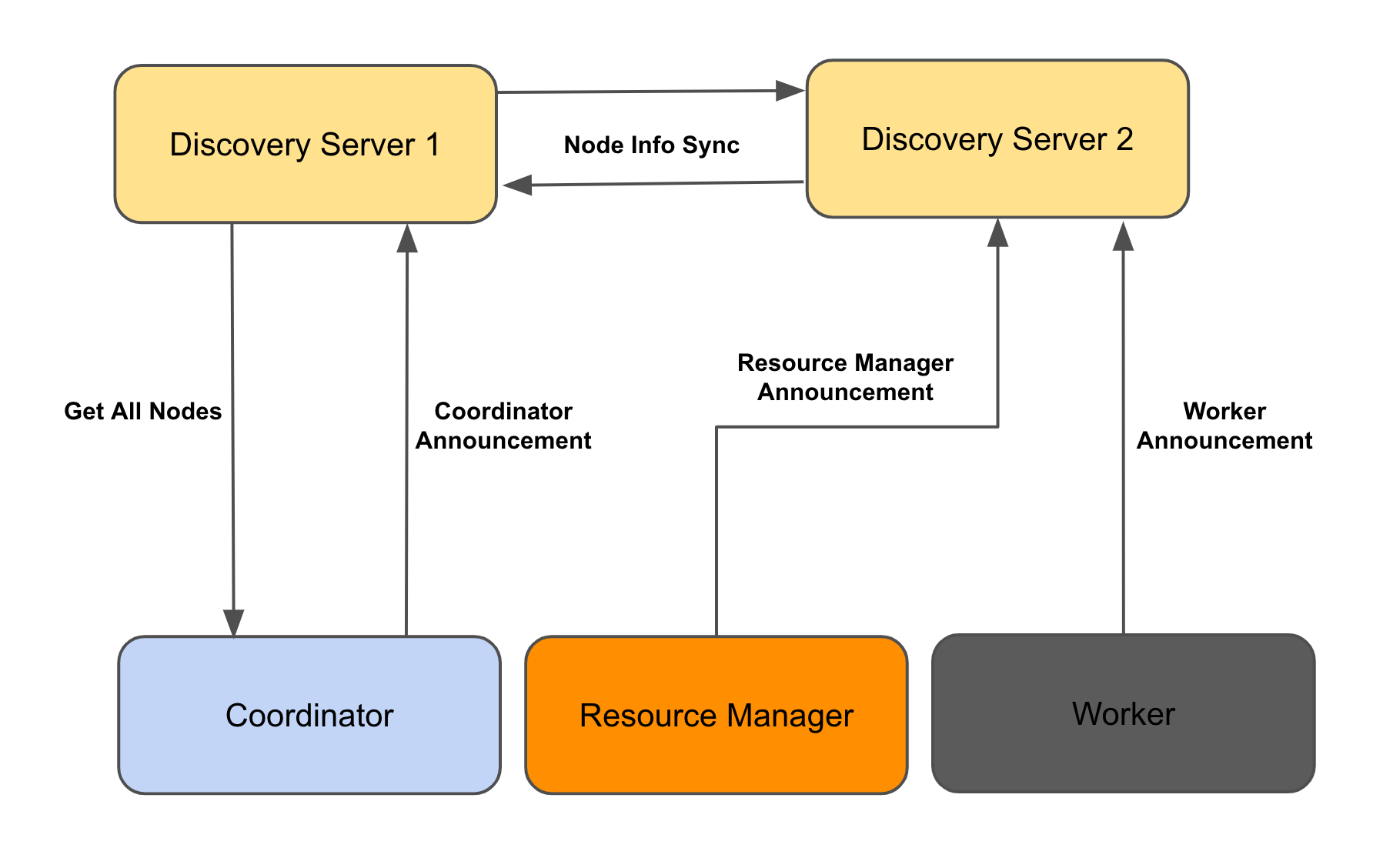
Discovery Service
Discovery Service 的嵌入式版本以分布式模式运行在资源管理器上。Discovery Service 通过将接收到的更新传递给集群中的其他 Discovery Service 来保持同步。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
如何使用 Disaggregated Coordinator
如果需要在生产环境下使用 Disaggregated Coordinator,我们至少需要使用 Presto 0.266,另外,我们至少需要配置一个 Resource Manager,配置如下:
resource-manager=true resource-manager-enabled=true coordinator=false node-scheduler.include-coordinator=false http-server.http.port=8080 thrift.server.port=8081 query.max-memory=50GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery-server.enabled=true discovery.uri=http://example.net:8080 (Point to resource manager host/vip) thrift.server.ssl.enabled=true
Coordinator 的配置如下
coordinator=true node-scheduler.include-coordinator=false http-server.http.port=8080 query.max-memory=50GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery.uri=http://example.net:8080 (Point to resource manager host/vip) resource-manager-enabled=true
Worker 的配置如下
coordinator=false http-server.http.port=8080 query.max-memory=50GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery.uri=http://example.net:8080 (Point to resource manager host/vip) resource-manager-enabled=true
本文翻译自:Disaggregated Coordinator
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Presto multi-master Coordinator 简介】(https://www.iteblog.com/archives/10159.html)







