

Apache Flink是一个高效、分布式、基于Java和Scala(主要是由Java实现)实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。
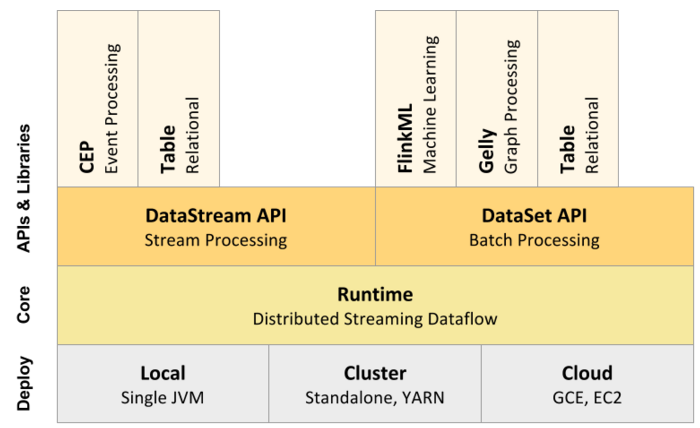
从Flink官方文档可以知道,目前Flink支持三大部署模式:Local、Cluster以及Cloud,如下图所示:
本文将简单地介绍如何部署Apache Flink On YARN(也就是如何在YARN上运行Flink作业),本文是基于Apache Flink 1.0.0以及Hadoop 2.2.0。
在YARN上启动一个Flink主要有两种方式:(1)、启动一个YARN session(Start a long-running Flink cluster on YARN);(2)、直接在YARN上提交运行Flink作业(Run a Flink job on YARN)。下面将分别进行介绍。
Flink YARN Session
这种模式下会启动yarn session,并且会启动Flink的两个必要服务:JobManager和TaskManagers,然后你可以向集群提交作业。同一个Session中可以提交多个Flink作业。需要注意的是,这种模式下Hadoop的版本至少是2.2,而且必须安装了HDFS(因为启动YARN session的时候会向HDFS上提交相关的jar文件和配置文件)。我们可以通过./bin/yarn-session.sh脚本启动YARN Session,由于我们第一次使用这个脚本,我们先看看这个脚本支持哪些参数:
[iteblog@www.iteblog.com flink]$ ./bin/yarn-session.sh
Usage:
Required
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
Optional
-D <arg> Dynamic properties
-d,--detached Start detached
-jm,--jobManagerMemory <arg> Memory for JobManager Container [in MB]
-nm,--name <arg> Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-st,--streaming Start Flink in streaming mode
-tm,--taskManagerMemory <arg> Memory per TaskManager Container [in MB]
各个参数的含义里面已经介绍的很详细了。在启动的是可以指定TaskManager的个数以及内存(默认是1G),也可以指定JobManager的内存,但是JobManager的个数只能是一个。好了,我们开启动一个YARN session吧:
./bin/yarn-session.sh -n 4 -tm 8192 -s 8
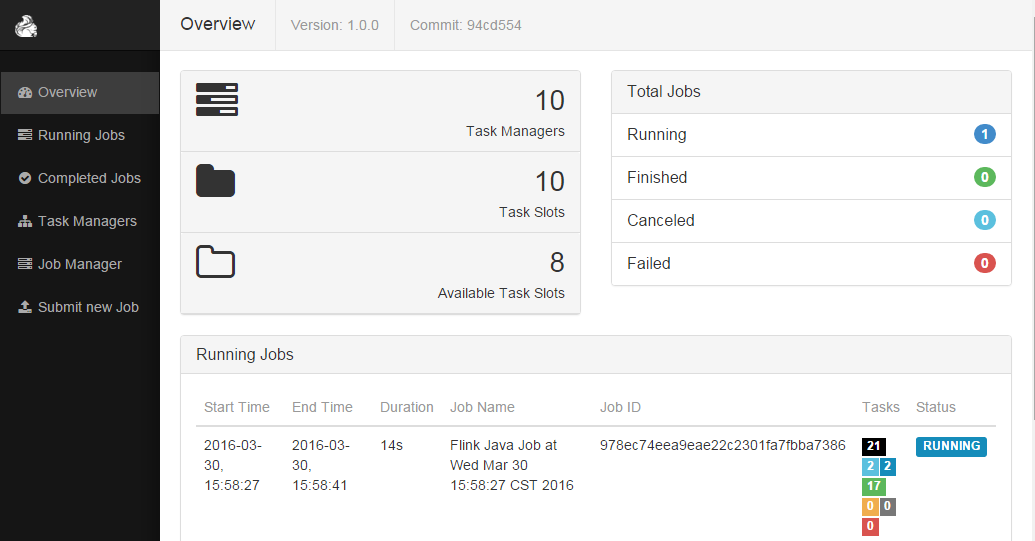
上面命令启动了4个TaskManager,每个TaskManager内存为8G且占用了8个核(是每个TaskManager,默认是1个核)。在启动YARN session的时候会加载conf/flink-config.yaml配置文件,我们可以根据自己的需求去修改里面的相关参数(关于里面的参数含义请参见Flink官方文档介绍吧)。一切顺利的话,我们可以在https://www.iteblog.com:9981/proxy/application_1453101066555_2766724/#/overview上看到类似于下面的页面:
启动了YARN session之后我们如何运行作业呢?很简单,我们可以使用./bin/flink脚本提交作业,同样我们来看看这个脚本支持哪些参数:
[iteblog@www.iteblog.com flink-1.0.0]$ bin/flink
./flink <ACTION> [OPTIONS] [ARGUMENTS]
The following actions are available:
Action "run" compiles and runs a program.
Syntax: run [OPTIONS] <jar-file> <arguments>
"run" action options:
-c,--class <classname> Class with the program entry point
("main" method or "getPlan()" method.
Only needed if the JAR file does not
specify the class in its manifest.
-C,--classpath <url> Adds a URL to each user code
classloader on all nodes in the
cluster. The paths must specify a
protocol (e.g. file://) and be
accessible on all nodes (e.g. by means
of a NFS share). You can use this
option multiple times for specifying
more than one URL. The protocol must
be supported by the {@link
java.net.URLClassLoader}.
-d,--detached If present, runs the job in detached
mode
-m,--jobmanager <host:port> Address of the JobManager (master) to
which to connect. Specify
'yarn-cluster' as the JobManager to
deploy a YARN cluster for the job. Use
this flag to connect to a different
JobManager than the one specified in
the configuration.
-p,--parallelism <parallelism> The parallelism with which to run the
program. Optional flag to override the
default value specified in the
configuration.
-q,--sysoutLogging If present, supress logging output to
standard out.
-s,--fromSavepoint <savepointPath> Path to a savepoint to reset the job
back to (for example
file:///flink/savepoint-1537).
我们可以使用run选项运行Flink作业。这个脚本可以自动获取到YARN session的地址,所以我们可以不指定--jobmanager参数。我们以Flink自带的WordCount程序为例进行介绍,先将测试文件上传到HDFS上:
hadoop fs -copyFromLocal LICENSE hdfs:///user/iteblog/
然后将这个文件作为输入并运行WordCount程序:
./bin/flink run ./examples/batch/WordCount.jar --input hdfs:///user/iteblog/LICENSE
一切顺利的话,可以看到在终端会显示出计算的结果:
(0,9) (1,6) (10,3) (12,1) (15,1) (17,1) (2,9) (2004,1) (2010,2) (2011,2) (2012,5) (2013,4) (2014,6) (2015,7) (2016,2) (3,6) (4,4) (5,3) (50,1) (6,3) (7,3) (8,2) (9,2) (a,25) (above,4) (acceptance,1) (accepting,3) (act,1)
如果我们不想将结果输出在终端,而是保存在文件中,可以使用--output参数指定保存结果的地方:
./bin/flink run ./examples/batch/WordCount.jar \
--input hdfs:///user/iteblog/LICENSE \
--output hdfs:///user/iteblog/result.txt
然后我们可以到hdfs:///user/iteblog/result.txt文件里面查看刚刚运行的结果。
--input和--output参数并不是Flink内部的参数,而是WordCount程序中定义的;2、指定路径的时候一定记得需要加上模式,比如上面的
hdfs://,否者程序会在本地寻找文件。Run a single Flink job on YARN
上面的YARN session是在Hadoop YARN环境下启动一个Flink cluster集群,里面的资源是可以共享给其他的Flink作业。我们还可以在YARN上启动一个Flink作业。这里我们还是使用./bin/flink,但是不需要事先启动YARN session:
./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar \
--input hdfs:///user/iteblog/LICENSE \
--output hdfs:///user/iteblog/result.txt
上面的命令同样会启动一个类似于YARN session启动的页面。其中的-yn是指TaskManager的个数,必须指定。
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Flink on YARN部署快速入门指南】(https://www.iteblog.com/archives/1620.html)






您好,我我部署安装了flink1.03 ,在statdalone 模式下都没问题,但是在yarn之上就会一直报错如下,您见过吗?希望能指点
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
Failing this attempt. Failing the application.
If log aggregation is enabled on your cluster, use this command to further investigate the issue:
yarn logs -applicationId application_1466234607023_0003
at org.apache.flink.yarn.FlinkYarnClientBase.deployInternal(FlinkYarnClientBase.java:669)
at org.apache.flink.yarn.FlinkYarnClientBase.deploy(FlinkYarnClientBase.java:346)
at org.apache.flink.client.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:419)
at org.apache.flink.client.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:362)
是否还有更详细的错误信息?
这是报错全部内容
[hadoop@dqe1v1 bin]$ ./yarn-session.sh -n 4 -tm 8192 -s 8
2016-06-20 13:30:40,285 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at dqe1v1/192.168.100.101:8032
2016-06-20 13:30:40,397 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2016-06-20 13:30:40,735 WARN org.apache.flink.yarn.FlinkYarnClient - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2016-06-20 13:30:40,735 INFO org.apache.flink.yarn.FlinkYarnClient - Using values:
2016-06-20 13:30:40,736 INFO org.apache.flink.yarn.FlinkYarnClient - TaskManager count = 4
2016-06-20 13:30:40,736 INFO org.apache.flink.yarn.FlinkYarnClient - JobManager memory = 1024
2016-06-20 13:30:40,736 INFO org.apache.flink.yarn.FlinkYarnClient - TaskManager memory = 8192
2016-06-20 13:30:40,937 WARN org.apache.flink.yarn.FlinkYarnClient - This YARN session requires 33792MB of memory in the cluster. There are currently only 24576MB available.
The Flink YARN client will try to allocate the YARN session, but maybe not all TaskManagers are connecting from the beginning because the resources are currently not available in the cluster. The allocation might take more time than usual because the Flink YARN client needs to wait until the resources become available.
2016-06-20 13:30:40,938 WARN org.apache.flink.yarn.FlinkYarnClient - There is not enough memory available in the YARN cluster. The TaskManager(s) require 8192MB each. NodeManagers available: [8192, 8192, 8192]
After allocating the JobManager (1024MB) and (2/4) TaskManagers, the following NodeManagers are available: [7168, 0, 0]
The Flink YARN client will try to allocate the YARN session, but maybe not all TaskManagers are connecting from the beginning because the resources are currently not available in the cluster. The allocation might take more time than usual because the Flink YARN client needs to wait until the resources become available.
2016-06-20 13:30:40,938 WARN org.apache.flink.yarn.FlinkYarnClient - There is not enough memory available in the YARN cluster. The TaskManager(s) require 8192MB each. NodeManagers available: [8192, 8192, 8192]
After allocating the JobManager (1024MB) and (3/4) TaskManagers, the following NodeManagers are available: [7168, 0, 0]
The Flink YARN client will try to allocate the YARN session, but maybe not all TaskManagers are connecting from the beginning because the resources are currently not available in the cluster. The allocation might take more time than usual because the Flink YARN client needs to wait until the resources become available.
2016-06-20 13:30:41,388 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink1.03/lib/flink-dist_2.11-1.0.3.jar to hdfs://192.168.100.101:9000/user/hadoop/.flink/application_1466400511474_0001/flink-dist_2.11-1.0.3.jar
2016-06-20 13:30:45,538 INFO org.apache.flink.yarn.Utils - Copying from /home/hadoop/flink1.03/conf/flink-conf.yaml to hdfs://192.168.100.101:9000/user/hadoop/.flink/application_1466400511474_0001/flink-conf.yaml
2016-06-20 13:30:45,588 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink1.03/lib/flink-python_2.11-1.0.3.jar to hdfs://192.168.100.101:9000/user/hadoop/.flink/application_1466400511474_0001/flink-python_2.11-1.0.3.jar
2016-06-20 13:30:45,646 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink1.03/lib/log4j-1.2.17.jar to hdfs://192.168.100.101:9000/user/hadoop/.flink/application_1466400511474_0001/log4j-1.2.17.jar
2016-06-20 13:30:45,712 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink1.03/lib/slf4j-log4j12-1.7.7.jar to hdfs://192.168.100.101:9000/user/hadoop/.flink/application_1466400511474_0001/slf4j-log4j12-1.7.7.jar
2016-06-20 13:30:45,751 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink1.03/conf/logback.xml to hdfs://192.168.100.101:9000/user/hadoop/.flink/application_1466400511474_0001/logback.xml
2016-06-20 13:30:45,787 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink1.03/conf/log4j.properties to hdfs://192.168.100.101:9000/user/hadoop/.flink/application_1466400511474_0001/log4j.properties
2016-06-20 13:30:45,834 INFO org.apache.flink.yarn.FlinkYarnClient - Submitting application master application_1466400511474_0001
2016-06-20 13:30:46,194 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1466400511474_0001
2016-06-20 13:30:46,194 INFO org.apache.flink.yarn.FlinkYarnClient - Waiting for the cluster to be allocated
2016-06-20 13:30:46,196 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
2016-06-20 13:30:47,199 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
2016-06-20 13:30:48,201 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
2016-06-20 13:30:49,205 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
2016-06-20 13:30:50,207 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
2016-06-20 13:30:51,209 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
2016-06-20 13:30:52,212 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
2016-06-20 13:30:53,214 INFO org.apache.flink.yarn.FlinkYarnClient - YARN application has been deployed successfully.
2016-06-20 13:30:53,377 INFO org.apache.flink.yarn.FlinkYarnCluster - Start actor system.
2016-06-20 13:30:53,717 INFO akka.event.slf4j.Slf4jLogger - Slf4jLogger started
2016-06-20 13:30:53,764 INFO Remoting - Starting remoting
2016-06-20 13:30:53,904 INFO Remoting - Remoting started; listening on addresses :[akka.tcp://flink@192.168.100.101:50415]
2016-06-20 13:30:53,925 INFO org.apache.flink.yarn.FlinkYarnCluster - Start application client.
Flink JobManager is now running on 192.168.100.102:39246
JobManager Web Interface: http://dqe1v1:8088/proxy/application_1466400511474_0001/
2016-06-20 13:30:53,938 INFO org.apache.flink.yarn.ApplicationClient - Notification about new leader address akka.tcp://flink@192.168.100.102:39246/user/jobmanager with session ID null.
2016-06-20 13:30:53,940 INFO org.apache.flink.yarn.ApplicationClient - Received address of new leader akka.tcp://flink@192.168.100.102:39246/user/jobmanager with session ID null.
2016-06-20 13:30:53,941 INFO org.apache.flink.yarn.ApplicationClient - Disconnect from JobManager null.
2016-06-20 13:30:53,945 INFO org.apache.flink.yarn.ApplicationClient - Trying to register at JobManager akka.tcp://flink@192.168.100.102:39246/user/jobmanager.
2016-06-20 13:30:54,466 INFO org.apache.flink.yarn.ApplicationClient - Trying to register at JobManager akka.tcp://flink@192.168.100.102:39246/user/jobmanager.
2016-06-20 13:30:54,545 INFO org.apache.flink.yarn.ApplicationClient - Successfully registered at the JobManager Actor[akka.tcp://flink@192.168.100.102:39246/user/jobmanager#609545764]
2016-06-20 13:30:54,547 INFO org.apache.flink.yarn.ApplicationClient - Successfully registered at the JobManager Actor[akka.tcp://flink@192.168.100.102:39246/user/jobmanager#609545764]
2016-06-20 13:30:55,035 WARN akka.remote.ReliableDeliverySupervisor - Association with remote system [akka.tcp://flink@192.168.100.102:39246] has failed, address is now gated for [5000] ms. Reason is: [Disassociated].
2016-06-20 13:30:56,956 WARN org.apache.flink.yarn.FlinkYarnCluster - YARN reported application state FAILED
2016-06-20 13:30:56,957 WARN org.apache.flink.yarn.FlinkYarnCluster - Diagnostics: Application application_1466400511474_0001 failed 1 times due to AM Container for appattempt_1466400511474_0001_000001 exited with exitCode: -103
For more detailed output, check application tracking page:http://dqe1v1:8088/cluster/app/application_1466400511474_0001Then, click on links to logs of each attempt.
Diagnostics: Container [pid=2612,containerID=container_1466400511474_0001_01_000001] is running beyond virtual memory limits. Current usage: 278.8 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1466400511474_0001_01_000001 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 2612 2610 2612 2612 (bash) 0 0 115838976 299 /bin/bash -c /usr/lib/jvm/jre-1.8.0/bin/java -Xmx424M -Dlog.file=/home/hadoop/hadoop2.7/logs/userlogs/application_1466400511474_0001/container_1466400511474_0001_01_000001/jobmanager.log -Dlogback.configurationFile=file:logback.xml -Dlog4j.configuration=file:log4j.properties org.apache.flink.yarn.ApplicationMaster 1>/home/hadoop/hadoop2.7/logs/userlogs/application_1466400511474_0001/container_1466400511474_0001_01_000001/jobmanager.out 2>/home/hadoop/hadoop2.7/logs/userlogs/application_1466400511474_0001/container_1466400511474_0001_01_000001/jobmanager.err
|- 2621 2612 2612 2612 (java) 1039 84 2363568128 71061 /usr/lib/jvm/jre-1.8.0/bin/java -Xmx424M -Dlog.file=/home/hadoop/hadoop2.7/logs/userlogs/application_1466400511474_0001/container_1466400511474_0001_01_000001/jobmanager.log -Dlogback.configurationFile=file:logback.xml -Dlog4j.configuration=file:log4j.properties org.apache.flink.yarn.ApplicationMaster
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
Failing this attempt. Failing the application.
The YARN cluster has failed
2016-06-20 13:30:56,958 INFO org.apache.flink.yarn.FlinkYarnCluster - Sending shutdown request to the Application Master
2016-06-20 13:30:56,960 INFO org.apache.flink.yarn.ApplicationClient - Sending StopYarnSession request to ApplicationMaster.
2016-06-20 13:31:00,567 WARN Remoting - Tried to associate with unreachable remote address [akka.tcp://flink@192.168.100.102:39246]. Address is now gated for 5000 ms, all messages to this address will be delivered to dead letters. Reason: Connection refused: /192.168.100.102:39246
2016-06-20 13:31:06,550 WARN Remoting - Tried to associate with unreachable remote address [akka.tcp://flink@192.168.100.102:39246]. Address is now gated for 5000 ms, all messages to this address will be delivered to dead letters. Reason: Connection refused: /192.168.100.102:39246
2016-06-20 13:31:06,960 WARN org.apache.flink.yarn.FlinkYarnCluster - Error while stopping YARN Application Client
java.util.concurrent.TimeoutException: Futures timed out after [10000 milliseconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219)
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:153)
at scala.concurrent.Await$$anonfun$ready$1.apply(package.scala:169)
at scala.concurrent.Await$$anonfun$ready$1.apply(package.scala:169)
at scala.concurrent.BlockContext$DefaultBlockContext$.blockOn(BlockContext.scala:53)
at scala.concurrent.Await$.ready(package.scala:169)
at scala.concurrent.Await.ready(package.scala)
at org.apache.flink.yarn.FlinkYarnCluster.shutdown(FlinkYarnCluster.java:449)
at org.apache.flink.client.FlinkYarnSessionCli.runInteractiveCli(FlinkYarnSessionCli.java:324)
at org.apache.flink.client.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:465)
at org.apache.flink.client.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:362)
2016-06-20 13:31:06,965 INFO org.apache.flink.yarn.ApplicationClient - Stopped Application client.
2016-06-20 13:31:06,965 INFO org.apache.flink.yarn.ApplicationClient - Disconnect from JobManager Actor[akka.tcp://flink@192.168.100.102:39246/user/jobmanager#609545764].
2016-06-20 13:31:06,970 INFO akka.remote.RemoteActorRefProvider$RemotingTerminator - Shutting down remote daemon.
2016-06-20 13:31:06,970 INFO akka.remote.RemoteActorRefProvider$RemotingTerminator - Remote daemon shut down; proceeding with flushing remote transports.
2016-06-20 13:31:06,989 INFO akka.remote.RemoteActorRefProvider$RemotingTerminator - Remoting shut down.
2016-06-20 13:31:07,012 INFO org.apache.flink.yarn.FlinkYarnCluster - Deleting files in hdfs://192.168.100.101:9000/user/hadoop/.flink/application_1466400511474_0001
2016-06-20 13:31:07,014 INFO org.apache.flink.yarn.FlinkYarnCluster - Application application_1466400511474_0001 finished with state FAILED and final state FAILED at 1466400655132
2016-06-20 13:31:07,017 WARN org.apache.flink.yarn.FlinkYarnCluster - Application failed. Diagnostics Application application_1466400511474_0001 failed 1 times due to AM Container for appattempt_1466400511474_0001_000001 exited with exitCode: -103
For more detailed output, check application tracking page:http://dqe1v1:8088/cluster/app/application_1466400511474_0001Then, click on links to logs of each attempt.
Diagnostics: Container [pid=2612,containerID=container_1466400511474_0001_01_000001] is running beyond virtual memory limits. Current usage: 278.8 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1466400511474_0001_01_000001 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 2612 2610 2612 2612 (bash) 0 0 115838976 299 /bin/bash -c /usr/lib/jvm/jre-1.8.0/bin/java -Xmx424M -Dlog.file=/home/hadoop/hadoop2.7/logs/userlogs/application_1466400511474_0001/container_1466400511474_0001_01_000001/jobmanager.log -Dlogback.configurationFile=file:logback.xml -Dlog4j.configuration=file:log4j.properties org.apache.flink.yarn.ApplicationMaster 1>/home/hadoop/hadoop2.7/logs/userlogs/application_1466400511474_0001/container_1466400511474_0001_01_000001/jobmanager.out 2>/home/hadoop/hadoop2.7/logs/userlogs/application_1466400511474_0001/container_1466400511474_0001_01_000001/jobmanager.err
|- 2621 2612 2612 2612 (java) 1039 84 2363568128 71061 /usr/lib/jvm/jre-1.8.0/bin/java -Xmx424M -Dlog.file=/home/hadoop/hadoop2.7/logs/userlogs/application_1466400511474_0001/container_1466400511474_0001_01_000001/jobmanager.log -Dlogback.configurationFile=file:logback.xml -Dlog4j.configuration=file:log4j.properties org.apache.flink.yarn.ApplicationMaster
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
Failing this attempt. Failing the application.
2016-06-20 13:31:07,017 WARN org.apache.flink.yarn.FlinkYarnCluster - If log aggregation is activated in the Hadoop cluster, we recommend to retrieve the full application log using this command:
yarn logs -applicationId application_1466400511474_0001
(It sometimes takes a few seconds until the logs are aggregated)
2016-06-20 13:31:07,964 INFO org.apache.flink.yarn.FlinkYarnCluster - YARN Client is shutting down
2016-06-20 13:31:11,068 INFO org.apache.flink.client.FlinkYarnSessionCli - Stopping interactive command line interface, YARN cluster has been stopped.
你是不是没配置 HADOOP_CONF_DIR 或者 YARN_CONF_DIR 属性?
设置了export HADOOP_CONF_DIR=/home/hadoop/hadoop2.7/etc/hadoop
已经搞定,是yarn 默认参数问题