作者:李闯 郭理想
背景
随着有赞实时计算业务场景全部以Flink SQL的方式接入,对有赞现有的引擎版本—Flink 1.10的SQL能力提出了越来越多无法满足的需求以及可以优化的功能点。目前有赞的Flink SQL是在Yarn上运行,但是在公司应用容器化的背景下,可以统一使用公司K8S资源池,同时考虑到任务之间的隔离性以及任务的弹性调度,Flink SQL任务K8S化是必须进行的,所以我们也希望通过这次升级直接利社区的on K8S能力,直接将FlinkSQL集群迁移到K8S上。特别是社区在Flink 1.13中on Native K8S能力的支持完善,为了紧跟社区同时提升有赞实时计算引擎的能力,经过一些列调研,我们决定将有赞实时计算引擎由Flink 1.10升级到Flink 1.13.2。
有赞业务场景下的升级到 Flink 1.13 收益评估
社区在发布Flink 1.13后相比于Flink 1.10有了很多的新特性和优化,有些新特性在有赞场景下可能并未用到,所以接下来将主要从以下几个方面介绍一下在有赞业务场景下升级到Flink 1.13的一些收益。
1、 Flink SQL 相关收益
由于目前几乎所有的实时计算任务都通过Flink SQL方式实现,所以升级后关于Flink SQL上的一些优化是我们十分关注的,其中下面几点在升级后在有赞的实时计算业务场景下有很大的收益的:
(1) Flink SQL语法更为简洁,提高开发效率
Flink 1.10之后,社区提出了新的connector属性key,SQL开发更为简洁,可以提升实时用户的开发作业效率。
(2)时区和时间函数相关优化
由于Flink 1.10的时间函数在时区问题的不完善,用户在使用currenttimestamp和currentday等函数时由于时区问题需要额外的转换。而在 Flink 1.13 中对时区和时间函数进行纠正和优化,包括:
相关时间函数考虑了时区问题
CURRENTTIMESTAMP/CURRENTTIME/CURRENT_DATE/NOW()在Flink 1.13中考虑了时区问题,且为本地时区。
PROCTIME()考虑了时区问题,且为本地时区。

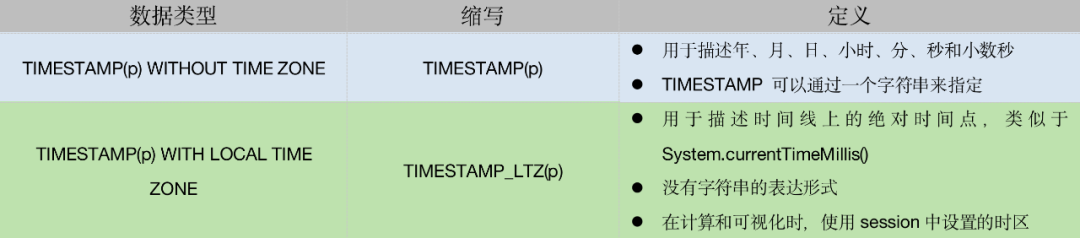
支持了TIMESTAMP_LTZ类型
例如CURRENTTIMESTAMP函数返回值为TIMESTAMPLTZ类型,而不是TIMESTAMP类型。
夏令时支持Flink支持在TIMESTAMPLTZ列上定义时间属性,Flink SQL在window处理时结合TIMESTAMP和TIMESTAMPLTZ,优雅地支持了夏令时。
(3)支持 Window TVF 语法标准化
在官方的介绍中,关于Window TVF包含四部分内容:Window TVF语法,近实时累计计算,Window性能优化,多维数据分析。其中Window TVF语法在Flink 1.13中用Table-Valued Function进行了语法标准化,在新的语法中支持TUMBLE和HOP窗口,我们通过以下两个例子来展示这一特性在某些场景下的应用:
用户在table-valued窗口函数中可以访问窗口的起始和终止时间,从而使用户可以实现新的功能。
例如,除了常规的基于窗口的聚合和Join之外,用户现在也可以实现基于窗口的Top-K聚合:
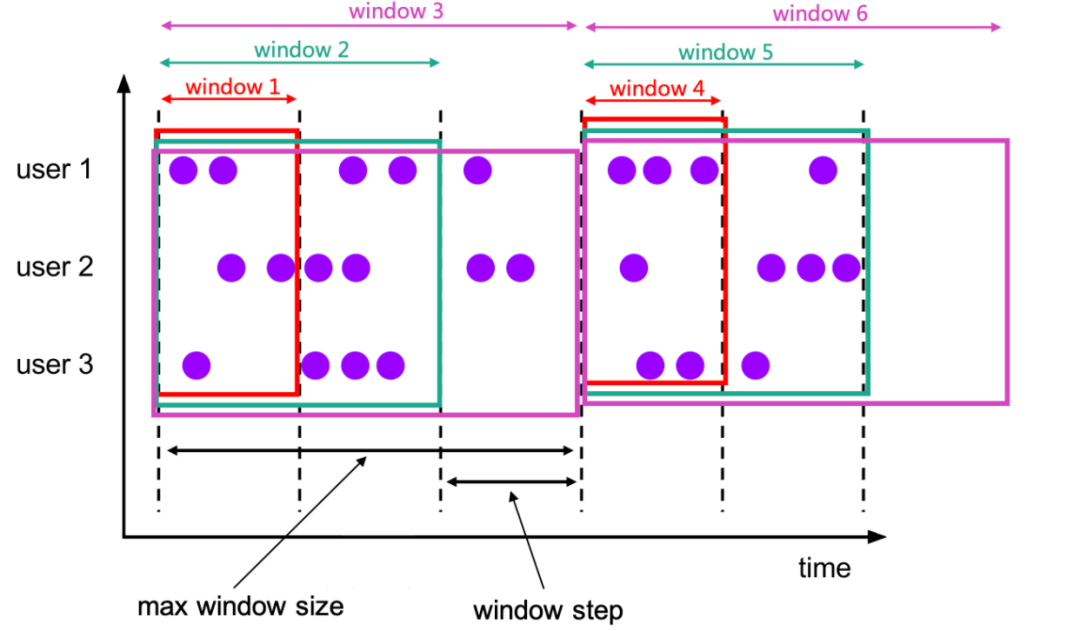
新增了CUMULATE WINDOW窗口,它可以支持按特定步长扩展的窗口,直到达到最大窗口大小,例如计算一段时间内的PV, UV等指标:
SELECT window_time, window_start, window_end, SUM(price) AS total_price
FROM TABLE(CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end, window_time;
window1 统计的是第一个区间的数据;
window2 统计的是第一区间和第二个区间的数据;
window3 统计的是第一区间,第二个区间和第三个区间的数据。
累积窗口可以对迟到的数据进行处理,比如某一个数据是window1的迟到数据,无法被window1统计进去,但是触发window2时,会把window1迟到的数据统计进去,而且window2会复用window1的统计结果,而不是重新计算一遍。
(4)Flink On Hive 的能力
目前在有赞已经开始有部分实时业务方希望Flink能够支持Hive,比如Flink-Hive近实时的数仓中间层【小时表可更快产出】,以及Flink实时任务和离线数据对比功能。而在Flink 1.12中,已经支持生产级别Flink On Hive任务运行(社区Commitor说),所以基于这次Flink 1.13引擎版本升级,能够支持Flink on hive生产功能。因此本次升级可以解决部分实时业务方,Flink On Hive的业务需求,下面是Flink 1.13具体Hive相关功能:
支持 Hive 的 SQL 语法,支持常用的 Hive DML,DQL语法。
Hive 写入:FLIP-115 完善扩展了 FileSystem connector 的基础能力和实现,Table/SQL 层的 sink 可以支持各种格式(CSV、Json、Avro、Parquet、ORC),而且支持 Hive table 的所有格式。
FLIP-123 通过 Hive Dialect 为用户提供语法兼容,可以直接迁移 Hive 脚本到 Flink 中执行等等。
(5)其他功能及需求
支持查看SQL的执行计划
解决复杂Quary语句无法推断出primary key的问题
SQL Connectors中的Metadata处理。如果可以将某些source(和 format)的元数据作为额外字段暴露给用户,对于需要将元数据与记录数据一起处理的用户来说很有意义。一个常见的例子是Kafka,用户可能需要访问offset、partition或topic 信息、读写kafka消息中的key或 使用消息metadata中的时间戳进行时间相关的操作。
CREATEF TABLE table (
id BIGINT,
name STRING,
event_time TIMESTAMP(3) METADATA FROM 'timestamp', -- access Kafka 'timestamp' metadata
headers MAP METADATA -- access Kafka 'headers' metadata
) WITH (
'connector' = 'kafka',
'topic' = 'test-topic',
'format' = 'avro'
);
2、Flink on K8S 相关收益
在 on K8S 层面考虑升级到 Flink 1.13 主要有以下几个方面收益:
(1) Flink 1.13 on K8S更成熟稳定
相比于Flink 1.11 和 Flink 1.12,在Flink 1.13 版本中 on K8S 模式上更加丰富,更为成熟稳定。而且社区后续肯定是在 Native K8S 或者 Application Level K8S 上面发力。目前 社区在Flink 1.13 中关于 K8S 已经有了下面一些优化和新特性:
基于Kubernetes的高可用(HA)方案Flink可以利用Kubernetes提供的内置功能来实现JobManager的failover,而不用依赖ZooKeeper。为了实现不依赖于ZooKeeper的高可用方案,社区在Flink 1.12(FLIP-144)中实现了基于Kubernetes的高可用方案。
引入Application模式按照application粒度来启动一个集群,属于这个application的所有job在这个集群中运行。核心是Job Graph的生成以及作业的提交不在客户端执行,而是转移到JM端执行,这样网络下载上传的负载也会分散到集群中,不再有上述client单点上的瓶颈。
(2)实时离线弹性扩缩容
目前有赞的离线任务已经实现了较好的弹性扩缩容,当Flink SQL任务K8S化之后,可以和离线任务之间实现更好的弹性扩缩容,节省集群资源成本,这是十分有意义的。
3、状态保留和恢复相关收益
(1)基于Savepoint跨集群迁移的能力
在Flink 1.10版本中,Savepoint中meta数据和state数据存放的是绝对路径,这就造成了不能进行集群迁移,否则会造成任务状态丢失。而在Flink 1.10以后savepoint中meta数据和state数据保存在同一目录,方便整体转移和复用;把state引用改成了相对路径,这样即使迁移后路径发生变化依然可用。
(2)生产可用的 Unaligned Checkpoint
用户现在使用Unaligned Checkpoint时也可以扩缩容应用。如果用户需要因为性能原因不能使用Savepoint而必须使用Retained checkpoint时,这一功能会非常方便。
收益:这一特性极大提升我们checkpoint的性能,同时也优化了在反压场景下checkpoint超时失败的问题,解决目前一些大状态任务经常checkpoint超时的问题。同时也符合我们利用checkpoint来做重启状态恢复的场景。
(3)优化失败 Checkpoint 的异常和失败原因的汇报
Flink 1.13现在提供了失败或被取消的Checkpoint的统计,从而使用户可以更简单的判断Checkpoint失败的原因,而不需要去查看日志。Flink 1.13 之前的版本只有在 Checkpoint 成功的时候才会汇报指标(例如持久化数据的大小、触发时间等)。
4、支持 upsert kafka 和 更丰富 Format 格式
(1)支持 upsert kafka
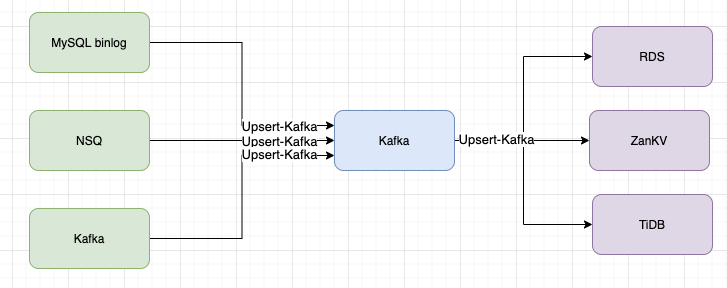
在Flink 1.12中支持了Upsert kafka,这一特性在有赞的实时计算业务场景中可以在某些数据链路中保障数据一致性。对于公司现有的一些场景,Upsert-kafka可以解决一些典型场景的数据重复问题:比如下图展示的在有赞很常见的一条实时链路,上游数据可以能是MySQL binlog或者NSQ -> Kafka进行数据同步,然后下游对Kafka数据进行按照 key聚合,将聚合数据存到mysql , tidb等等。这是很容易产生的问题就是在中间环节写入Kafka时很可能因为容错恢复等一些原因造成数据重复,特别是在checkpoint时间比较大时,造成的重复的数据量会很大,在现有的解决方案中,往往需要业务方在写入Kafka时进行幂等操作,比如存入ZanKV等方式进行幂等。但是现有的方式问题就是现在的幂等方式性能有限,同时不能做到完全幂等。
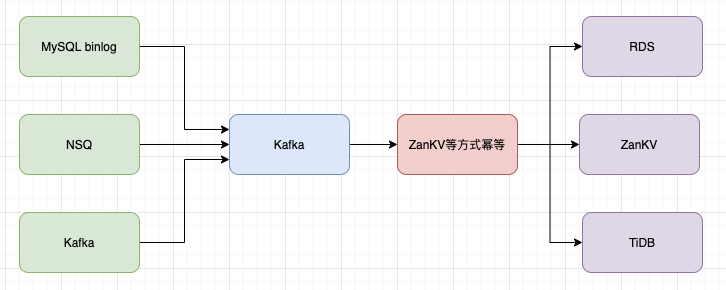
而接入Upsert Kafka连接器支持以 upsert 方式从Kafka topic中读取数据并将数据写入 Kafka topic。作为source,upsert-kafka连接器生产changelog流,其中每条数据记录代表一个更新或删除事件。更准确地说,数据记录中的 value 被解释为同一 key 的最后一个value的UPDATE,如果有这个key(如果不存在相应的 key,则该更新被视为 INSERT)。
作为sink,upsert-kafka连接器可以消费changelog流。它会将INSERT/UPDATE_AFTER数据作为正常的 Kafka 消息写入,并将DELETE数据以value为空的Kafka消息写入(表示对应 key 的消息被删除)。Flink将根据主键列的值对数据进行分区,从而保证主键上的消息有序,因此同一主键上的更新/删除消息将落在同一分区中,实现像Hbase一样的幂等写入。
(2)支持更丰富的 Format 格式
在 Flink1.10 版本中对Source和Sink 的 Format支持是有限的,这也造成了我们业务方有些任务需要 Source 段支持更多的格式,比如Kafka支持Raw、本地调试功能中Filesystem需要支持Json等,这在Flink 1.10版本中是无法做到的。但是如果升级到Flink 1.13则可以完美解决这些问题。
5、其他相关收益
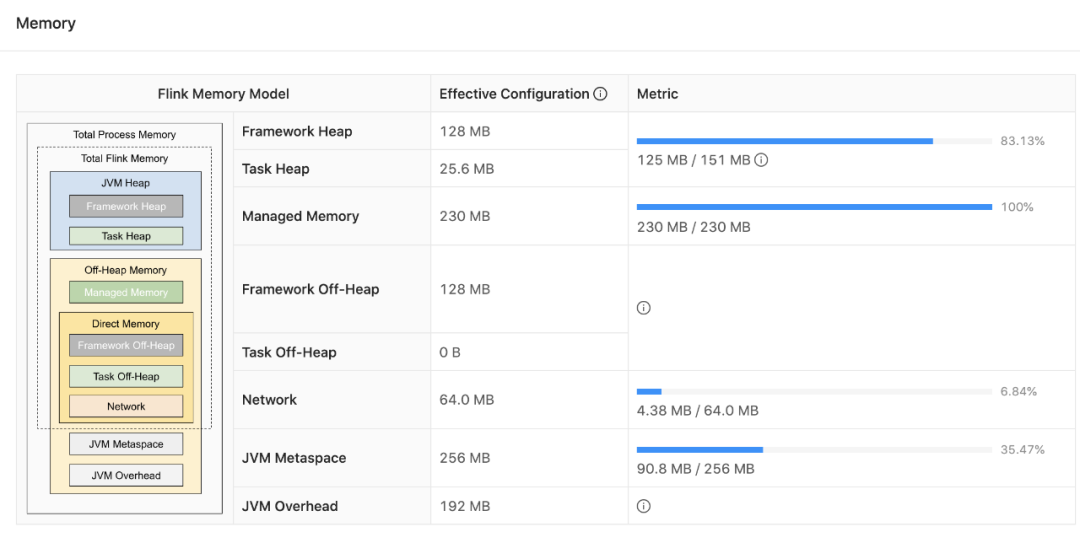
(1)查看JM和TM的内存相关指标
Flink 1.12 在WebUI上暴露了JobManager内存相关的指标和配置参数(FLIP-104)。对于TaskManager的指标页面也进行了更新,为Managed Memory、Network Memory和 Metaspace添加了新的指标,以反映自Flink 1.10(FLIP-102)开始引入的 TaskManager内存模型的更改。
(2)WebUI界面查看被压情况
Flink 1.13带来了一个改进的背压度量系统(使用任务邮箱计时而不是线程堆栈采样),以及一个重新设计的作业数据流图形表示,用颜色编码和繁忙度和背压比率表示。
(3)CPU 火焰图查看
可以直观的看CPU的火焰图来确定以下指标:当前哪些方法在消耗CPU的资源、各个方法消耗的CPU的资源的多少对比、堆栈上的哪些调用会导致执行特定的方法。
(4)Web UI 支持历史异常
Flink Web UI现在可以展示导致作业失败的n次历史异常,从而提升在一个异常导致多个后续异常的场景下的调试体验。用户可以在异常历史中找到根异常。
Flink 1.13 升级过程实践与踩坑
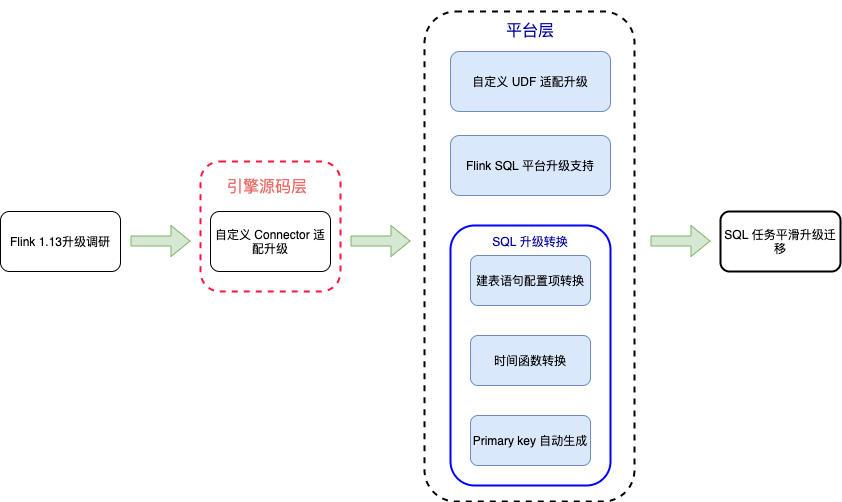
实时计算平台Flink引擎从Flink 1.10升级到Flink 1.13的主要工作将主要集中在自定义connector的升级、SQL语法升级转换、任务迁移验证等几个方面的实践和踩坑来介绍此次升级过程。
1、自定义 connector 升级
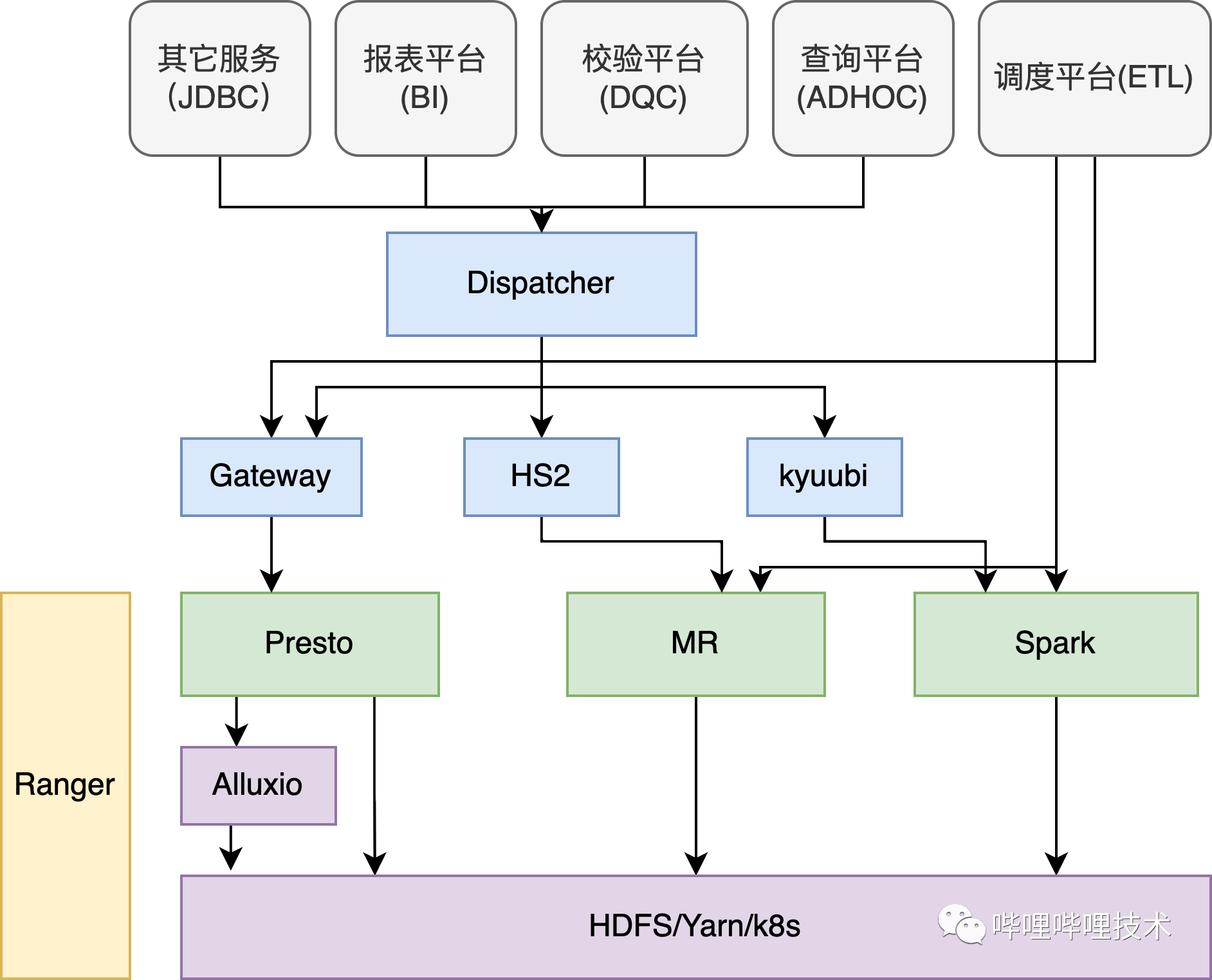
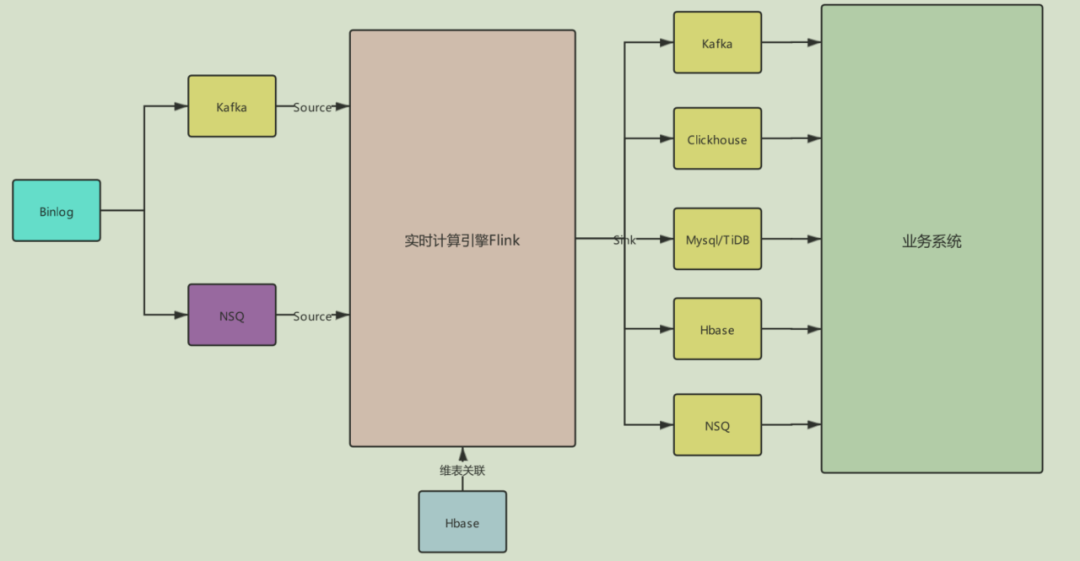
目前有赞的实时计算平台的数据流如下图所示,包括有赞自研的NSQ、Kafka、Mysql、TiDB、Clickhouse、Habse等大数据组件。那么此次升级需要将一些官方没有提供以及一些已经定制化的connector升级,其中包括NSQ connector,定制的无用户名密码的 jdbc connector,clickhouse connector定制的高可用hbase connector等。
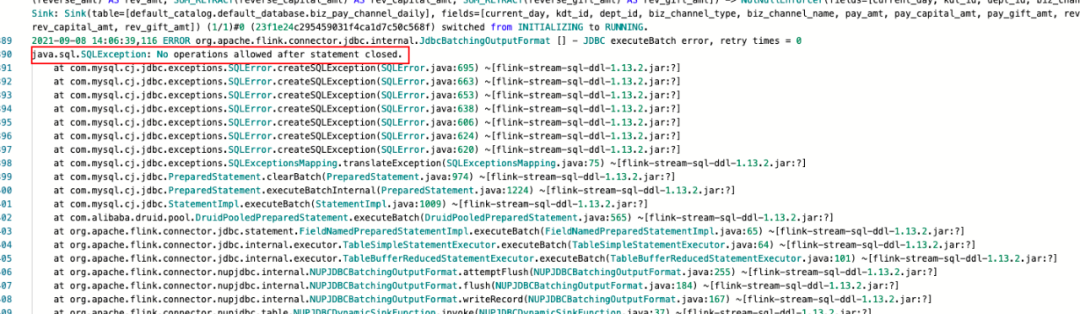
本次升级connector的主要工作是在Flink 1.10中DataStream和Table connector都统一是用到的是Row这种数据结构。而Flink 1.11 在 FLIP-95 对TableSource和TableSink API进行了重构,新增了Flink SQL内部数据结构RowData, 在一些场景的序列化有一定的提升。为此,我们需要对上述四种定制或者自定义的table connector进行升级重构,对于无用户名密码的jdbc connector的链接方式采用的是连接池构建链接的方式,但是采用链接池的方式构建链接时,如果对于Flink任务长时间没有数据流入则链接会被释放掉,如果再次过来数据用原来的链接去写入数据时会抛出链接被关闭的异常,导致任务出现频繁的重启:
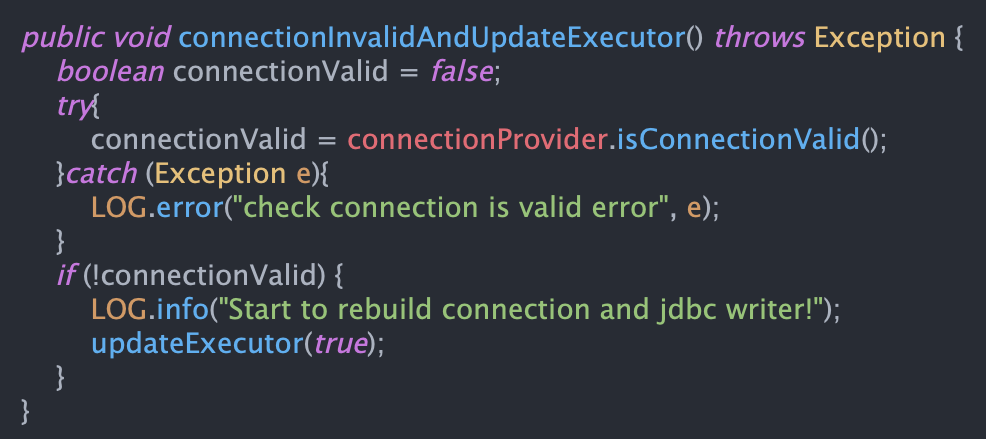
为解决上述问题,需要在flush前检查链接是否有效,如果连接失效需要重新构建链接:
2、 UDF 兼容
在Flink 1.10版本有赞实时计算平台根据业务需求提供了很多通用的UDF, 如Dubbo调用,JSON转换,动态过滤条件。同时用户也自定义了一部分UDF。所以在升级的过程中需要保证UDF的兼容性。好在Flink本身对UDF做了良好的兼容性,我们只需要将maven中flink-table-common改成对应的Flink版本即可。其中要注意的一点是,在Flink 1.13版本中如果UDF的参数是Object需要加上注解@DataTypeHint(inputGroup = InputGroup.ANY) 帮助Flink做类型推荐。
3、 SQL 语法转换实践
在 Flink 1.13 SQL 用法中相比于 Flink 1.10 的 SQL 用法主要有以下几部分存在差异:建表语句的配置项简化 、时间函数的优化导致类型不匹配、存在 upsert 操作的的建表语句中需要指定 primary key。为保证任务可以平滑的从 Flink 1.10 升级到 Flink 1.13,我们对目前集群已有的数百个 Flink 1.10 语法的 SQL 任务进行转换,自动生成 Flink 1.13 版本的语法。
`
(1)建表语句的配置项转换
在Flink 1.13 中社区提出了新的 connector 属性 key,SQL 开发更为简洁,如下图分别展示了 Kafka 作为数据源时在 Flink 1.10 语法中的 connector 属性配置以及转换后在 Flink 1.13 语法中的属性配置。
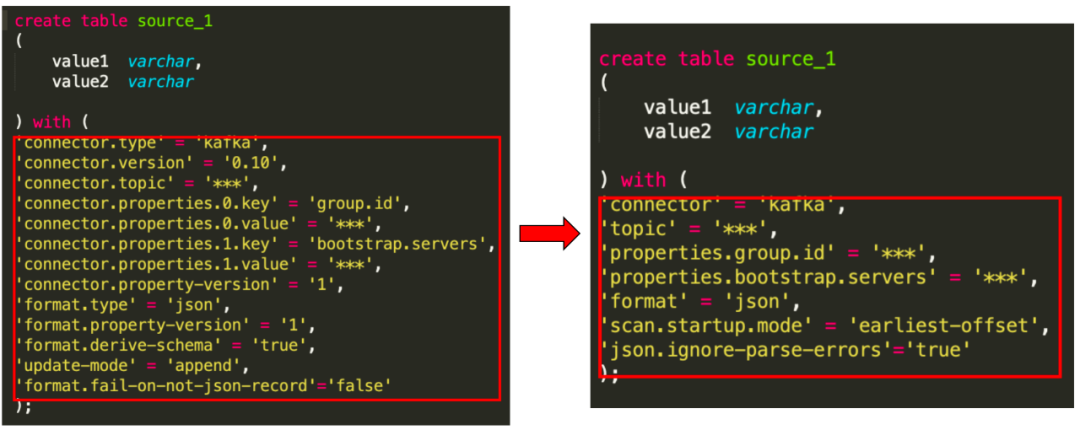
从上图的对比可以看出 Flink 1.13语法中的connector属性配置相比于Flink 1.10语法更为简洁易懂。虽然Flink本身对老版本的SQL connector的配置依然兼容,但是为了让用户使用新版的语法,我们对 用户在Flink 1.10的任务SQL进行配置了转换。
值得注意的是:在一些connector的属性配置中,一些属性的key进行了改变,以Kafka connector为例,其中在Flink 1.10中format.fail-on-not-json-record = false要对应Flink 1.13中的json.ignore-parse-errors = true表示的是按照JSON格式解析数据失败则跳过。同样connector.startup-mode = earliest-offset和scan.startup.mode = earliest-offset都表示从consumer的最早的点位开始消费,但是配置的key已经改变了,这是大家在做新老版本语法转换需要注意的事情。
(2)时间函数类型逻辑转换及时间数据类型转换
在Flink 1.13中对一些时间函数进行了优化正如上一章的第一节所介绍的,那么在现有的Flink 1.10 SQL业务中,有些用户用到了相关的时间函数比如最常见的currenttimestamp函数,那么我们要对任务进行平滑升级时需要对使用currenttimestamp等时间函数进行相应的逻辑转换,主要是时区变更的转化和类型不匹配的转换。
时间函数时区逻辑转换以currenttimestamp函数为例,在Flink 1.10版本中currenttimestamp未考虑时区是UTC+0时间,而升级Flink 1.13之后current_timestamp 考虑时区,且是本地时区时间。因此在之前的任务中,有些任务为了解决时区问题在任务中加了8小时或者减了16小时(前一天时间)。那么针对已经进行了时区转换的任务,我们需要将对应的8小时 时差减去,因此关于这一点我们对 SQL 任务进行匹配分析,对已经做了时区转换的任务逻辑减去 8 小时的时差。
时间函数类型转换还是以 currenttimestamp 函数为例,在 Flink 1.10 版本中 currenttimestamp 返回值类型为 timestamp 而在 Flink 1.13 中currenttimestamp返回值类型为 timestampltz 的格式。那么在 Flink 1.10 中的 current_timestamp 一些函数使用在 Flink 1.13中会报错,比如 TIMESTAMPDIFF 和 TIMESTAMPADD。简单举个例子
TIMESTAMPDIFF(MINUTE, (current_timestamp - INTERVAL '10' MINUTE), TO_TIMESTAMP(FROM_UNIXTIME(orderTime / 1000, 'yyyy-MM-dd HH:mm:ss')))
上述语句在Flink 1.13中会因为TIMESTAMPDIFF函数中一个是timestampltz格式一个是timestamp而出现异常,为此需要转换成同一种类型,比如将后面的时间转为timestampltz类型,才能应用TIMESTAMPDIFF、TIMESTAMPADD等函数。
TIMESTAMPDIFF(MINUTE, (current_timestamp - INTERVAL '10' MINUTE), TO_TIMESTAMP_LTZ(mainOrderInfo.orderTime , 3))
如果需要将CURRENTTIMESTAMP的TIMESTAMPLTZ类型转为TIMESTAMP类型,可以使用下面的方式进行转换:
TO_TIMESTAMP(CAST(CURRENT_TIMESTAMP AS STRING))
因此在升级到Flink 1.13中关于时间函数的使用转换是尤为需要注意的,否则会因为逻辑不对造成数据不准确,或者任务异常无法启动。
(3)Primary key 自动生成
在Flink 1.10以后对于存在upsert操作时比如写mysql,tidb时出现了聚合等操作需要在建表语句中指定primary key, 这也是为了解决在Flink 1.10中对于一个复杂的SQL语句无法通过优化器 从Quary语句中自动推断出primary key而产生异常的问题。因此,为了平滑升级,我们需要对upsert流的建表语句中指定primary key,否则会提示异常:
"please declare primary key for sink table when query contains update/delete record."
我们采用优化器推断Quary语句推断的方式实现了一套primary key自动生成的逻辑,然后判断任务是为upsert流 来为需要添加primary key的建表语句自动生成对应的primary key。当然对于一些过于复杂的SQL任务如果生成失败会进行提示,联系用户自己去手动添加primary key, 我们的primary key生成逻辑满足 95%的任务的primary key的自动生成。
4 、任务平滑迁移实践与踩坑
在Flink 1.10 SQL任务升级到Flink 1.13版本的过程中,我们除了做了语法转换之外,还有批量按照Flink 1.13语法检查,数据准确性验证,批量重启等工作。整个工作过程如下流程图所示:
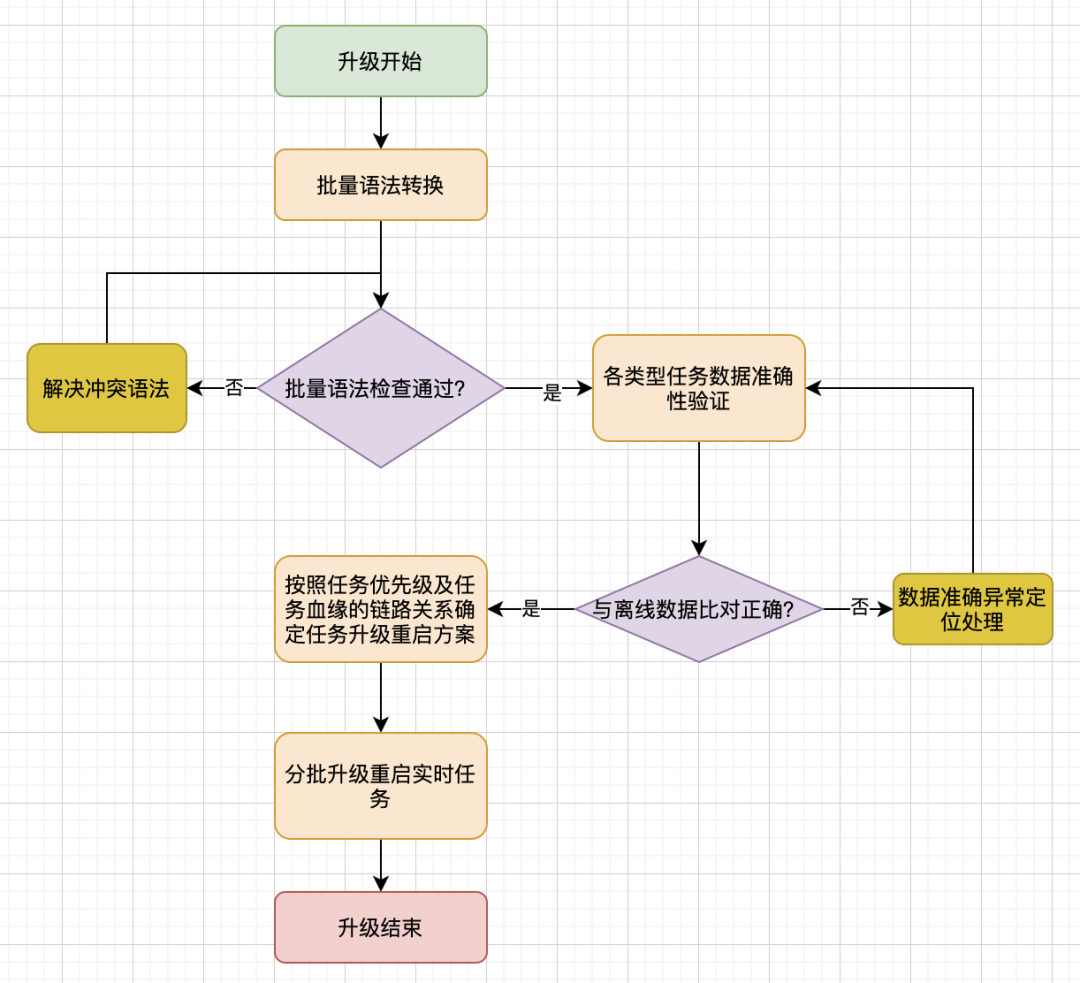
其中有几点需要关注的是:
在迁移之前我们对各种任务构建了测试任务,并在第二天将测试任务的数据与老版本的实时任务和离线任务进行数据准确性验证。
同时关于SQL转换后关于current_timestamp这种时间函数的逻辑转换以及primary key的自动生成,需要在SQL转换后让用户进行double check,反正升级后数据不准产生问题。
任务迁移尽量选择流量较小的时间段,防止重启异常时对业务产生很大的数据延迟影响。同时按照任务优先级的高低,以及根据实时任务血缘确定任务的重启顺序,比如在有赞的实时计算任务中,我们会优先重启低优先级和数据链路中下游的任务,在保证任务升级重启稳定运行一段时间后再去重启高优先级的任务,反正一些未发现的异常对升级后的任务产生大的影响。
5 、其他踩坑和注意
关于本次有赞实时计算平台引擎升级到Flink 1.13过程中也遇到过一些问题和踩过一些坑,一些问题已经在对应的实践中提及过了,那么还有遇到其他的一些升级过程中遇到一些问题在这里可以分享一下:
(1)任务升级后从之前版本的 checkpoint 文件恢复失败
当我们升级Flink 1.13后的任务想通过之前的任务的checkpoint文件进行状态恢复时,会偶尔出现下面的异常:
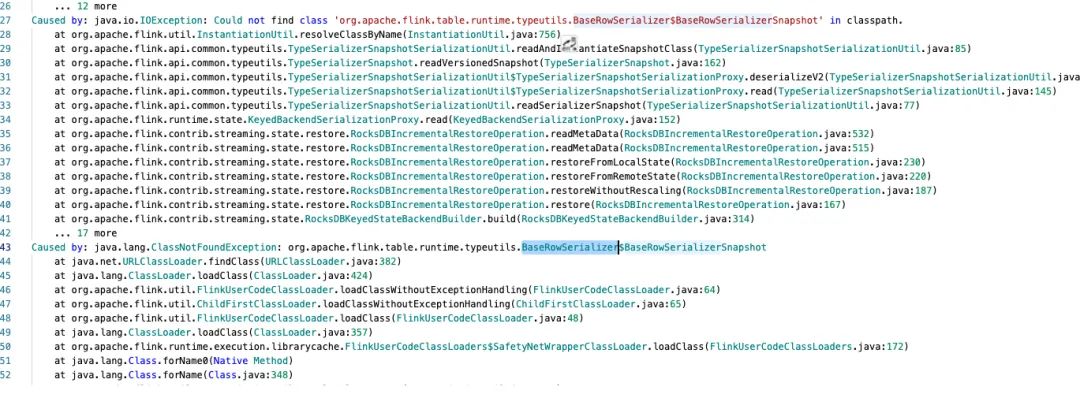
通过社区邮件和源码阅读发现根本原因是在Flink 1.11之后BaseRowSerializer改名成 RowDataSerializer了,即使用state-processor-API也没办法处理当前不存在的类。目前关于这一个问题社区也没有专门去处理的Jira。
这种问题并不是所有的任务重启时从之前的状态文件恢复都会出现的,所以面对这种问题的比较好的办法就是升级重启的时间尽量选择在流量小的时间段,对于一些按天维度做聚合的任务最好在凌晨的时候重启,这样出现问题也不会对第二天的数据有很大的影响,同时对于恢复异常的任务做好数据重放的处理。
(2)Mysql 维表关联出现类型转换异常报错
在升级Flink 1.13过程中,我们发现有几个mysql维表关联的任务升级重启后抛出如下异常:
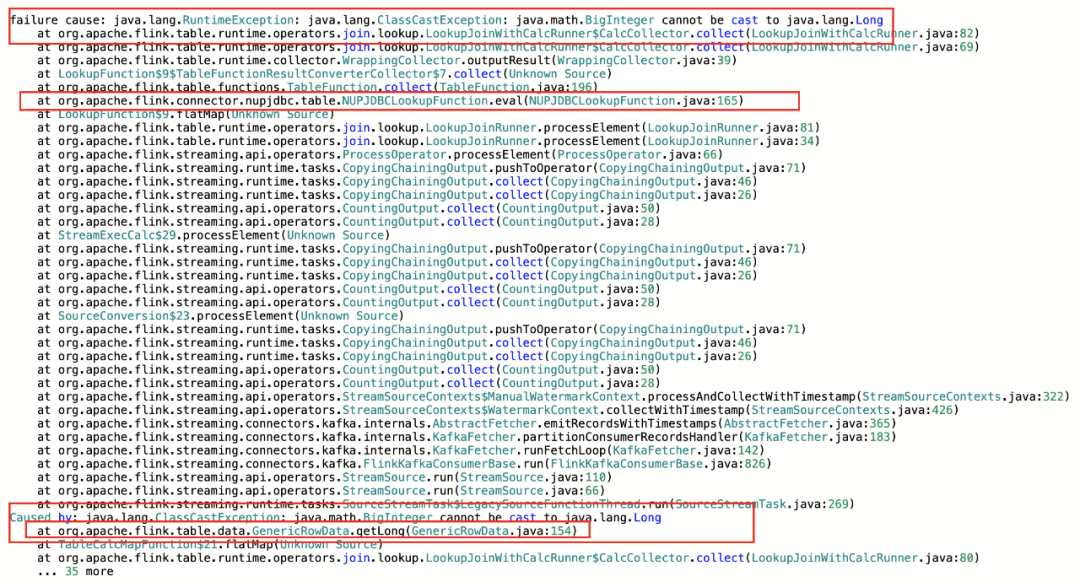
在1.13中由于对Table connector数据类型统一为RowData,在维表关联时如果业务方的mysql的字段类型定义为BIGINT,当mysql中是BIGINT UNSIGNED时,如果用Flink BIGINT去转成mysql的BIGINT UNSIGNED时会出现上述的报错。因为最终维表关联的数据要转换成RowData格式,所以不能将mysql 的 BIGINT UNSIGNED与Flink的BIGINT进行相互转换。
为了解决上述问题,在Flink 1.11中提出的一个Jira : FLINK-18580 ,官方建议在Flink构建维表时将BIGINT定义为DECIMAL(20,0)。

(3)执行多条 insert 语句任务异常
在Flink 1.10中我们底层真正执行SQL的是executeSql()方法,对于Flink 1.10版本去调用该方法不会出现任何异常,且每条insert语句均有输出。但是升级到Flink 1.13之后,如果依然采用executeSql()方法去执行一个任务内的多条insert语句时会出现问题,我们发现只有第一条insert语句是有结果的,同时集群上出现多个相同的job被提交。如下面例子所示:
insert into max_realtimet select guangBusinessId,st_hour,'orderCountHourAll',orderCountHourAll from order_hour_cnt_all_view; insert into max_realtime select guangBusinessId,st_hour,'orderPaidAmountHourAll',orderPaidAmountHourAll from order_hour_cnt_all_view; insert into max_realtime select guangBusinessId,st_hour,'orderPaidUserCountHourAll',orderPaidUserCountHourAll from order_hour_cnt_all_view;
在Flink 1.10的任务中print的结果是正常的:
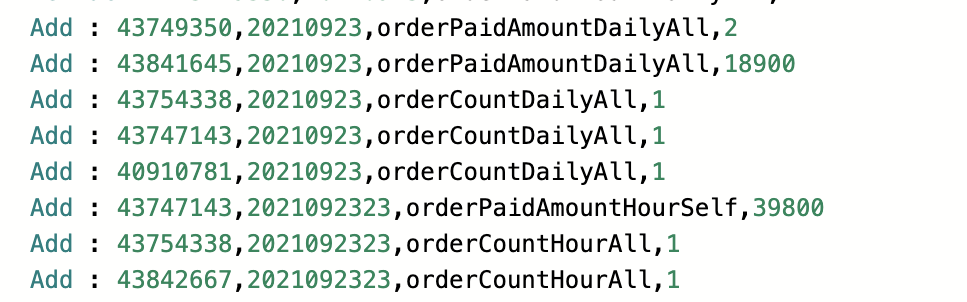
但是在Flink 1.13中可以明显只有第一条insert语句的输出:
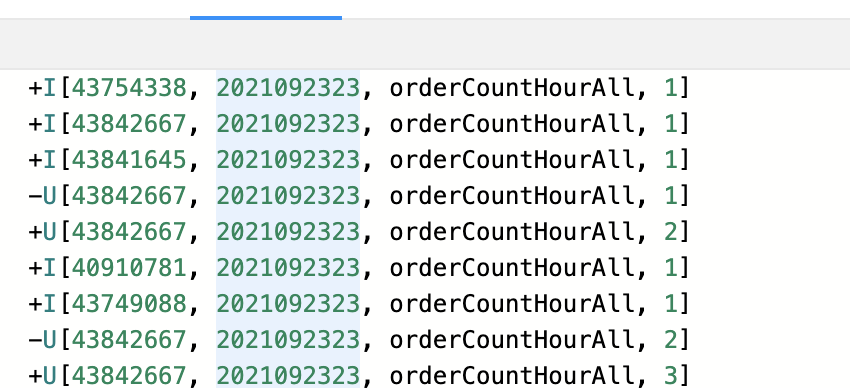
通过官方文档的解释我们发现执在Flink 1.13版本中executeSql()方法每执行一条insert 语句的会立即提交一个Flink作业,并返回一个与提交的作业相关联的TableResult实例。这也验证了为什么发现确实当启动一个多insert语句的任务时在集群会起来了多个job。
为此需要采用StatementSet将insert语句添加到StatementSet中,最后执行StatementSet.execute(),如下代码所示:
StatementSet statementSet = streamTableEnv.createStatementSet();
sqls.forEach(sql -> {
if(isInsertSql(sql)){
statementSet.addInsertSql(sql);
}else{
streamTableEnv.executeSql(sql);
}
});
statementSet.execute();
上述是我们从Flink 1.10升级到Flink 1.13中间遇到的一些问题,因为在Flink 1.10以后社区的代码架构改动还是很大的,中间踩了一些坑,也遇到一些问题,其实好多问题在社区邮件和社区的jira里面都给出了好的解决方案,我们更多的介绍了实践过程中踩过的一些坑来分享。
总结
目前有赞实时计算平台已经将Flink引擎从Flink 1.10升级到了Flink 1.13,并将所有的Flink SQL任务平滑迁移升级到Flink 1.13版本中,并成功运行了近三个月。随着有赞更多的业务场景不断接入实时任务,目前Flink SQL任务接近整体实时任务体量的60%,实时任务SQL化是我们的目标,因此升级到Flink 1.13后对于Flink SQL开发的简化以及特性增加与性能优化对我们来说是十分有价值的。
同时随着实时集群任务体量的增大,对资源的管控以及弹性扩缩容的需求也越来越大。而社区在Flink on K8S的投入也在不断增加,后续肯定是在Native K8S或者Application Level K8S有更多的优化,为此升级Flink 1.13之后我们将所有Flink SQL任务全部迁移到K8S集群,采用Flink on Native的Application模式运行任务,实现整个集群容器化,为后续的实时任务弹性扩缩容做好准备,目前我们已经完成Flink on Native的Application 模式任务的测试阶段。后面将紧跟Flink社区的发展,为有赞的更多业务场景提供更多实践的可能。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【有赞实时计算 Flink 1.13 升级实践】(https://www.iteblog.com/archives/10123.html)