

本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Updates from the New PrestoDB C++ Execution Engine》,分享者为来自 Ahana 的 Deepak Majeti 以及来自 Intel 的 Dave Cohen, Intel。
本次分享的 PPT 请关注 过往记忆大数据 公众号,并回复 10108 获取。
这篇分享将给大家概述代号为 Prestissimo 项目的相关最新进展。Prestissimo 是新的 PrestoDB C++ 执行引擎,其使用 Velox 库使其能够以良好的性能运行 TPC-H 基准测试。这项工作是 Prestissimo 和 Velox 的几个 PrestoDB 基金会成员公司之间的合作,包括 Ahana、字节跳动、Facebook 和英特尔等。在本次演讲中,我们将从高层概述 Velox 数据平台库(Velox Data Platform library)、Prestissimo c++ Worker、基于 java 的 PrestoDB Coordinator 如何与 Prestissimo 交互,以及如何使该框架在 TPC-H 基准测试中执行查询。本次演讲将特别关注 PrestoDB/Prestissimo 处理这些查询,其中数据集位于 ORC 或 Parquet 格式的 S3 兼容对象存储中。

本次分享主要包括以下几个部分:
- Prestissimo 和 Velox 回顾;
- Velox支持的函数;
- Parquet 和 S3 支持
- TPC-H 查询
- 开源协作
- 未来路线
Prestissimo 和 Velox 回顾

Velox 是用于向量化执行的开源最先进的项目:
•在交互式、批处理、流处理、人工智能等方面具有一致的语义;•最大化利用硬件资源;•使用 C++ 编写以便实现最高效率
为高性能进行相关的优化:
•使用字典编码(Dictionary encoding)来实现零拷贝执行•自定义字符串、数组和 Map 编码,允许完全向量化的条件表达式计算,而不需要额外的数据复制•自适应地使用基于数组的聚合和 normalized keys•用于低延迟的层次化语义感知缓存(Hierarchical semantic-aware cache )•Aria 风格的过滤下推到 TableScan
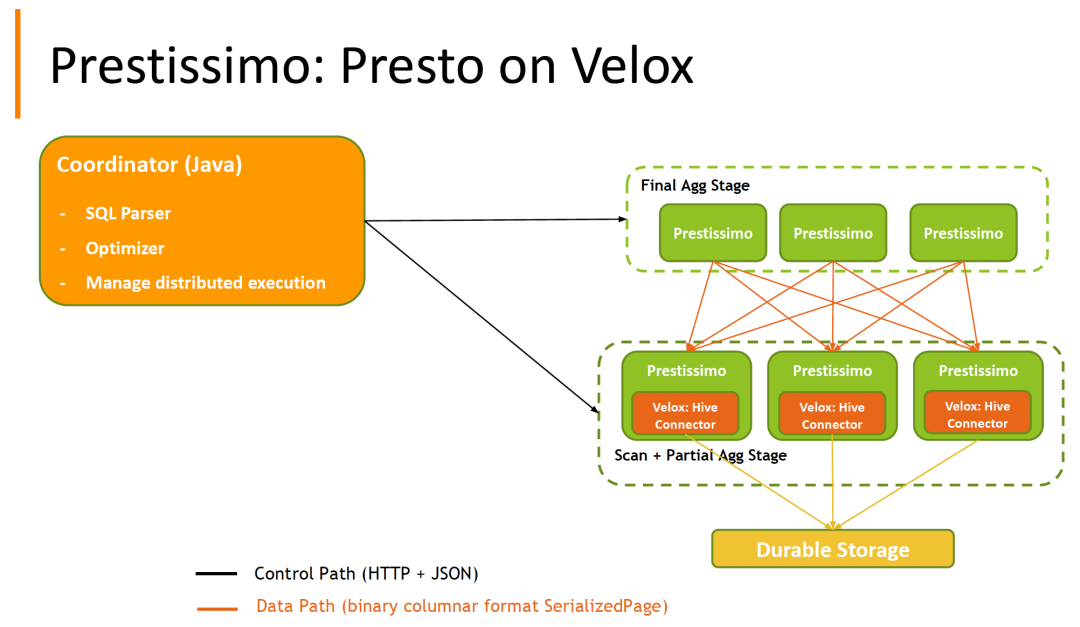
从上图可以看出,Prestissimo 其实是 Presto on Velox 的代号。Prestissimo 使用 Presto 的 Coordinator 进行 SQL 解析、优化以及管理分布式的执行。SQL 的执行是发送到 Velox 中执行的,其是使用 C++ 实现的。
Velox 支持的函数

上图是 Presto 支持的函数种类。
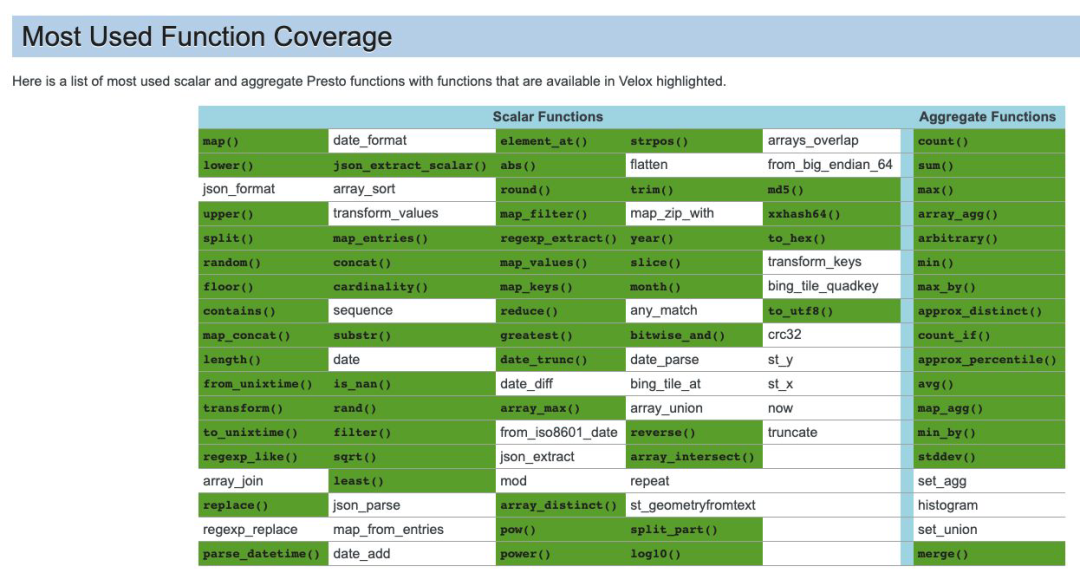
而 Velox 支持的标量(Scalar)和聚合函数如上所示(绿色代表支持),可以看见大部分常见的 Presto 函数 Velox 都支持。

上面是 Velox 中实现标量函数的方法。可见,一个简单的函数是包装在 VELOX_UDF_BEGIN 和 VELOX_UDF_END 宏之间。
关于这部分大家可以参见 Velox 的官方文档:https://facebookincubator.github.io/velox/develop/scalar-functions.html
Parquet 和 S3 支持

Velox 中对 Parquet 的支持是由 Intel 工程师贡献的;当前的实现是包装了 DuckDB 的 Parquet Reader(https://github.com/duckdb/duckdb)
•在 Velox 中,DuckDB 被用作嵌入式的类库,在测试中用作验证的内存中参考数据库。•支持部分过滤下推
DuckDB 的内存格式和 Velox 很类似,对大多数类型都是零拷贝。
当然,目前 Velox 的 Parquet Reader 是可插拔的。

Velox 中对 S3 的支持是由 Ahana 工程师贡献的;扩展了 Velox 的 FileSystem API。也是可插拔的;依赖 AWS C++ SDK;使用 Minio 覆盖CI。

下面我们来看下 Prestissimo 中是如何加载 S3 中的 Parquet 文件的:
•Prestissimo 实现了 Presto Worker REST API;•Control Plane 接受来自 coordinator 的查询片段(query fragment) Post 请求•查询片段(query fragment)接着被编译成 plan;•plan 被映射到 Velox library;•在执行中 Velox library 涉及的组件如下:•Tasks, Drivers•TableScan 使用 Connector 抽象;•HiveConnector 接口使用 S3 文件句柄和 Parquet reader 实例设置 reader
TPCH 查询

当 Velox 初次开源时,只支持一个 TPCH 查询;来自 Meta、Ahana 和字节跳动的工程师添加了许多功能,使得 Velox 支持22条 TPCH 查询中的19条:
•支持 Date 类型;•支持 left outer join;•部分支持相关子查询;•剩下的3个查询需要对相关子查询提供更多的支持
开源协作

•来自开源社区的贡献极大地改进了 Prestissimo 和 Velox
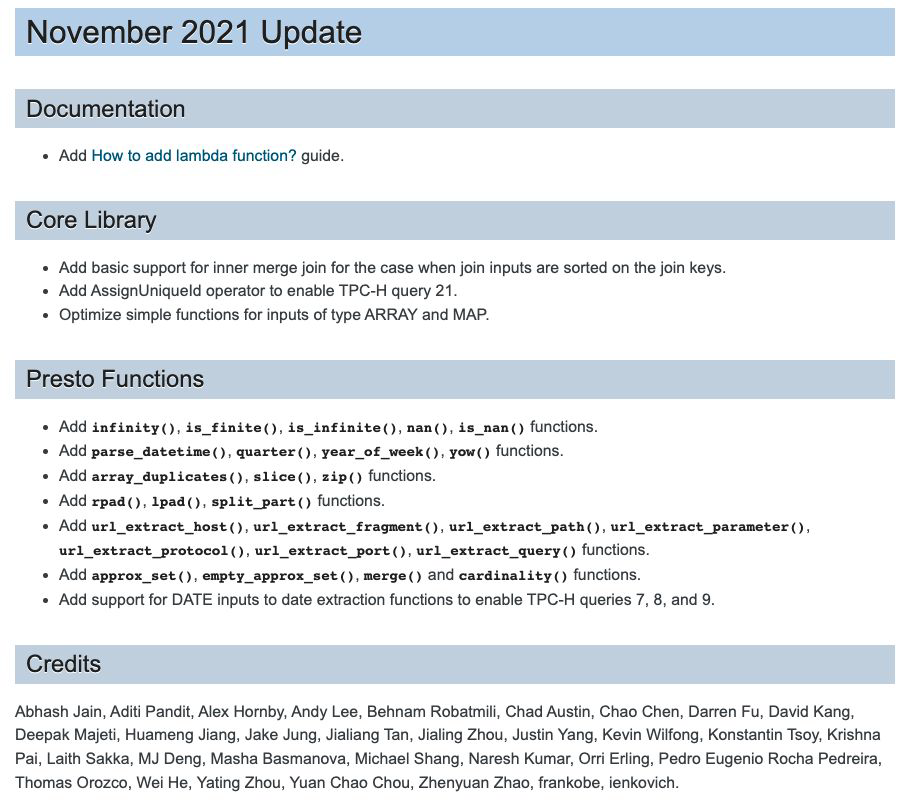
•当前 Velox 社区是非常活跃的,提交的 PR 会被迅速的 reviewed 并解决的;•文档是最新的,对初学者非常有帮助;•社区每月出版一份 news-letter(如下图)•Velox Slack 通道支持异步通信和协作
未来路线

- 在 Presto 集群中启用 Prestissimo;
- 继续为功能和性能添加更多的特性;
- 通过运行各种工作负载来强化 Velox 库
- 添加针对云存储和对象存储的 I/O 优化
- 支持所有的 TPC-DS 。
相关资源:
- https://github.com/facebookincubator/velox
- https://facebookincubator.github.io/velox/
- https://velox-oss.slack.com/
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Prestissimo:使 Presto 性能提升三倍】(https://www.iteblog.com/archives/10120.html)







