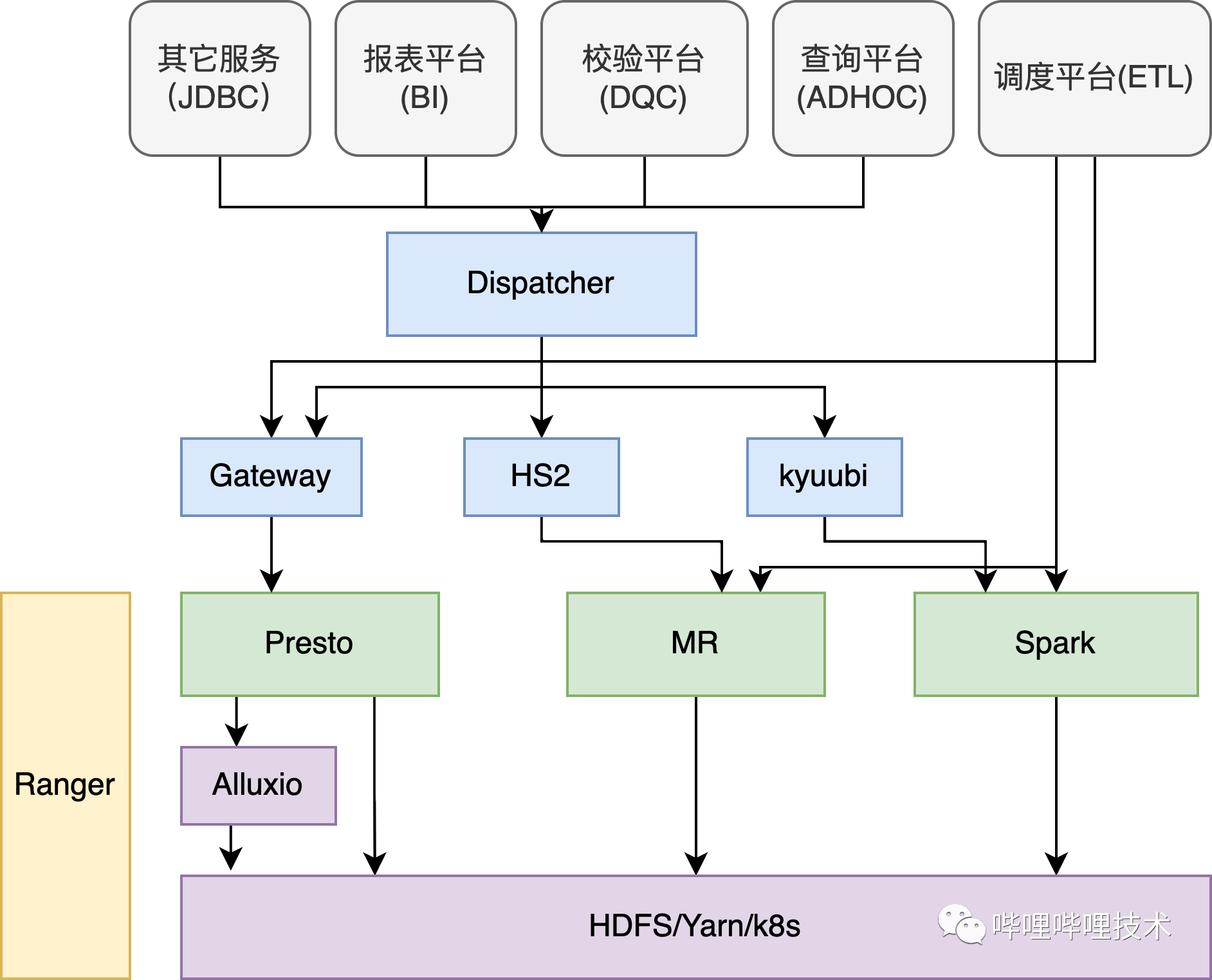
文章目录
背景
前段时间,为了降低用户使用ElasticSearch的存储成本,我们做了数据的冷热分离。为了保持集群磁盘利用率不变,我们减少了热节点数量。ElasticSearch集群开始出现写入瓶颈,节点产生大量的写入rejected,大量从kafka同步的数据出现写入延迟。我们深入分析写入瓶颈,找到了突破点,最终将Elasticsearch的写入性能提升一倍以上,解决了ElasticSearch瓶颈导致的写入延迟。这篇文章介绍了我们是如何发现写入瓶颈,并对瓶颈进行深入分析,最终进行了创新性优化,极大的提升了写入性能。
写入瓶颈分析
发现瓶颈
我们去分析这些延迟问题的时候,发现了一些不太好解释的现象。之前做性能测试时,ES节点cpu利用率能超过80%,而生产环境延迟索引所在的节点cpu资源只使用了不到50%,集群平均cpu利用率不到40%,这时候IO和网络带宽也没有压力。通过提升写入资源,写入速度基本没增加。于是我们开始一探究竟,我们选取了一个索引进行验证,该索引使用10个ES节点。从下图看到,写入速度不到20w/s,10个ES节点的cpu,峰值在40-50%之间。
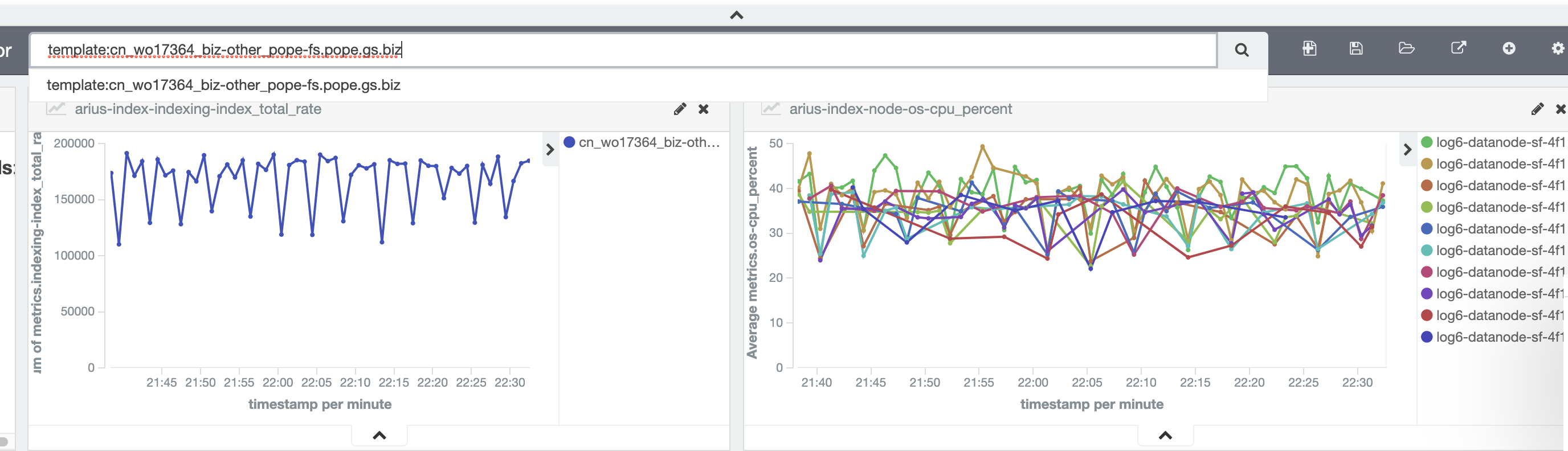
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
为了确认客户端资源是足够的,在客户端不做任何调整的情况下,将索引从10个节点,扩容到16个节点,从下图看到,写入速度来到了30w/s左右。
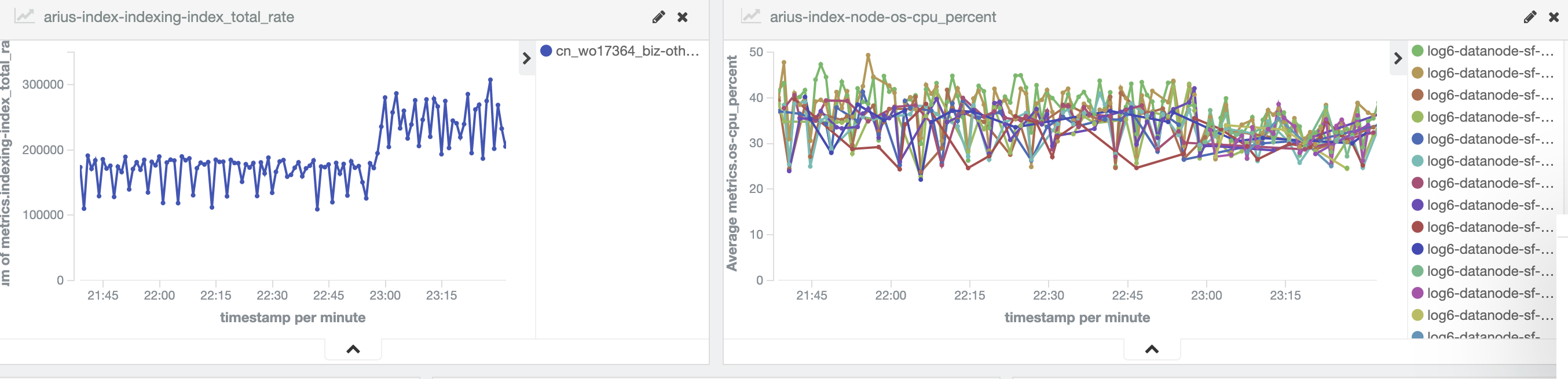
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
这证明了瓶颈出在服务端,ES节点扩容后,性能提升,说明10个节点写入已经达到瓶颈。但是上图可以看到,CPU最多只到了50%,而且此时IO也没达到瓶颈。
ES写入模型说明
这里要先对ES写入模型进行说明,下面分析原因会跟写入模型有关。
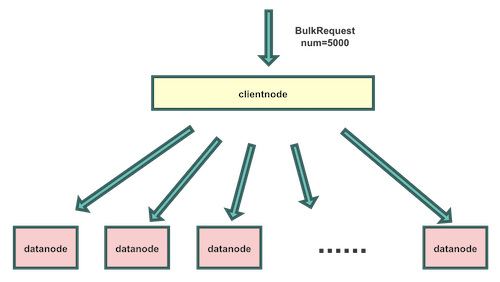
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
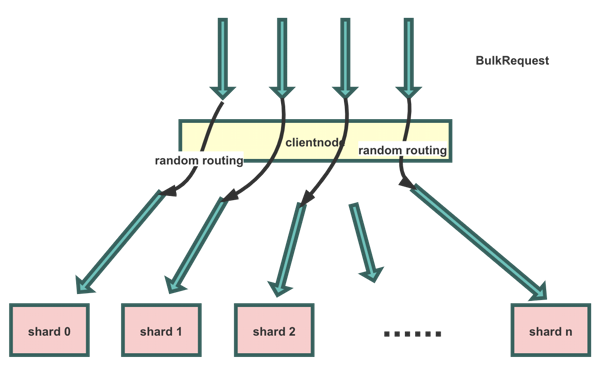
客户端一般是准备好一批数据写入ES,这样能极大减少写入请求的网络交互,使用的是ES的BULK接口,请求名为BulkRequest。这样一批数据写入ES的ClientNode。ClientNode对这一批数据按数据中的routing值进行分发,组装成一批BulkShardRequest请求,发送给每个shard所在的DataNode。发送BulkShardRequest请求是异步的,但是BulkRequest请求需要等待全部BulkShardRequest响应后,再返回客户端。
寻找原因
我们在ES ClientNode上有记录BulkRequest写入slowlog。
- `items`是一个BulkRequest的发送请求数
- `totalMills `是BulkRequest请求的耗时
- `max`记录的是耗时最长的BulkShardRequest请求
- `avg`记录的是所有BulkShardRequest请求的平均耗时。
我这里截取了部分示例。
[xxx][INFO ][o.e.m.r.RequestTracker ] [log6-clientnode-sf-5aaae-10] bulkDetail||requestId=null||size=10486923||items=7014||totalMills=2206||max=2203||avg=37 [xxx][INFO ][o.e.m.r.RequestTracker ] [log6-clientnode-sf-5aaae-10] bulkDetail||requestId=null||size=210506||items=137||totalMills=2655||max=2655||avg=218
从示例中可以看到,2条记录的avg相比max都小了很多。一个BulkRequest请求的耗时,取决于最后一个BulkShardRequest请求的返回。这就很容易联想到分布式系统的长尾效应。
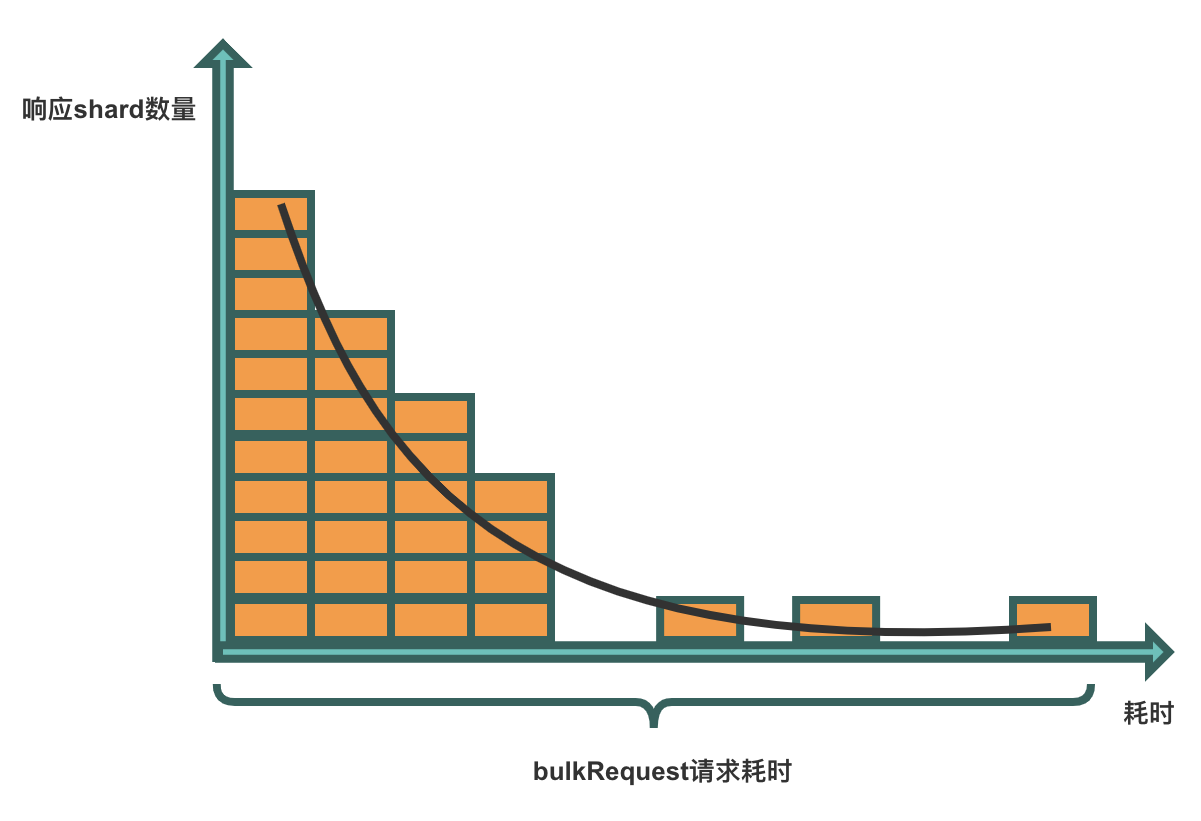
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
接下来再看一个现象,我们分析了某个节点的write线程的状态,发现节点有时候write线程全是runnable状态,有时候又有大量在waiting。此时写入是有瓶颈的,runnable状态可以理解,但却经常出现waiting状态。所以这也能印证了CPU利用率不高。同时也论证长尾效应的存在,因为长尾节点繁忙,ClientNode在等待繁忙节点返回BulkShardRequest请求,其他节点可能出现相对空闲的状态。下面是一个节点2个时刻的线程状态:
时刻一:
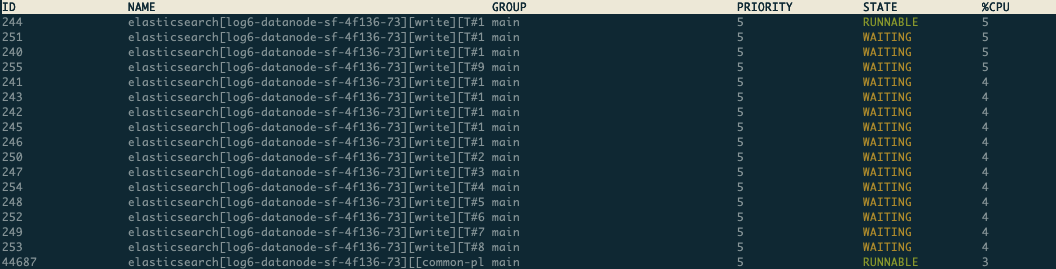
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
时刻二:
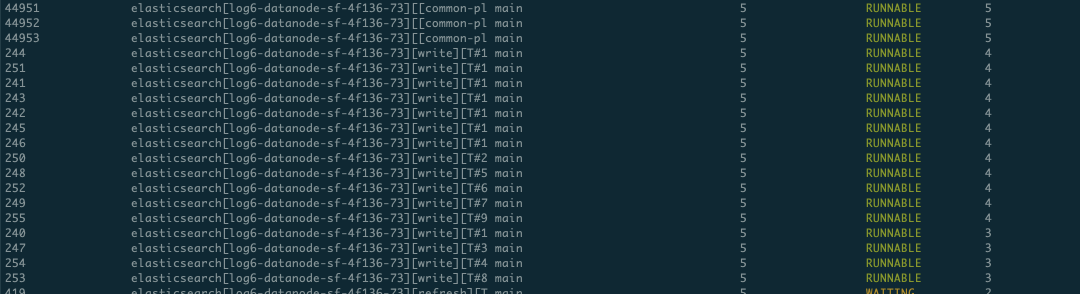
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
瓶颈分析
谷歌大神Jeffrey Dean《The Tail At Scale》介绍了长尾效应,以及导致长尾效应的原因。总结下来,就是正常请求都很快,但是偶尔单次请求会特别慢。这样在分布式操作时会导致长尾效应。我们从ES原理和实现中分析,造成ES单次请求特别慢的原因。发现了下面几个因素会造成长尾问题:
lucene refresh
我们打开lucene引擎内部的一些日志,可以看到:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
write线程是用来处理BulkShardRequest请求的,但是从截图的日志可以看到,write线程也会会进行refresh操作。这里面的实现比较复杂,简单说,就是ES定期会将写入buffer的数据refresh成segment,ES为了防止refresh不过来,会在BulkShardRequest请求的时候,判断当前shard是否有正在refresh的任务,有的话,就会帮忙一起分摊refresh压力,这个是在write线程中进行的。这样的问题就是造成单次BulkShardRequest请求写入很慢。还导致长时间占用了write线程。在write queue的原因会具体介绍这种危害。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
translog ReadWriteLock
ES的translog类似LSM-Tree的WAL log。ES实时写入的数据都在lucene内存buffer中,所以需要依赖写入translog保证数据的可靠性。ES translog具体实现中,在写translog的时候会上ReadLock。在translog过期、翻滚的时候会上WriteLock。这会出现,在WriteLock期间,实时写入会等待ReadLock,造成了BulkShardRequest请求写入变慢。我们配置的tranlog写入模式是async,正常开销是非常小的,但是从图中可以看到,写translog偶尔可能超过100ms。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
write queue
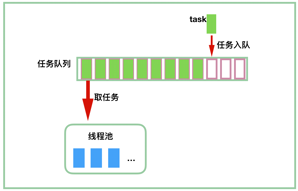
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
ES DataNode的写入是用标准的线程池模型是,提供一批active线程,我们一般配置为跟cpu个数相同。然后会有一个write queue,我们配置为1000。DataNode接收BulkShardRequest请求,先将请求放入write queue,然后active线程有空隙的,就会从queue中获取BulkShardRequest请求。这种模型下,当写入active线程繁忙的时候,queue中会堆积大量的请求。这些请求在等待执行,而从ClientNode角度看,就是BulkShardRequest请求的耗时变长了。下面日志记录了action的slowlog,其中waitTime就是请求等待执行的时间,可以看到等待时间超过了200ms。
[xxx][INFO ][o.e.m.r.RequestTracker ] [log6-datanode-sf-4f136-100] actionStats||action=indices:data/write/bulk[s][p]||requestId=546174589||taskId=6798617657||waitTime=231||totalTime=538 [xxx][INFO ][o.e.m.r.RequestTracker ] [log6-datanode-sf-4f136-100] actionStats||action=indices:data/write/bulk[s][p]||requestId=546174667||taskId=6949350415||waitTime=231||totalTime=548
JVM GC
ES正常一次写入请求基本在亚毫秒级别,但是jvm的gc可能在几十到上百毫秒,这也增加了BulkShardRequest请求的耗时。这些加重长尾现象的case,会导致一个情况就是,有的节点很繁忙,发往这个节点的请求都delay了,而其他节点却空闲下来,这样整体cpu就无法充分利用起来。
论证结论
长尾问题主要来自于BulkRequest的一批请求会分散写入多个shard,其中有的shard的请求会因为上述的一些原因导致响应变慢,造成了长尾。如果每次BulkRequest只写入一个shard,那么就不存在写入等待的情况,这个shard返回后,ClientNode就能将结果返回给客户端,那么就不存在长尾问题了。
我们做了一个验证,修改客户端SDK,在每批BulkRequest写入的时候,都传入相同的routing值,然后写入相同的索引,这样就保证了BulkRequest的一批数据,都写入一个shard中。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
优化后,第一个平稳曲线是,每个bulkRequest为10M的情况,写入速度在56w/s左右。之后将bulkRequest改为1M(10M差不多有4000条记录,之前写150个shard,所以bulkSize比较大)后,性能还有进一步提升,达到了65w/s。
从验证结果可以看到,每个bulkRequest只写一个shard的话,性能有很大的提升,同时cpu也能充分利用起来,这符合之前单节点压测的cpu利用率预期。
性能优化
从上面的写入瓶颈分析,我们发现了ES无法将资源用满的原因来自于分布式的长尾问题。于是我们着重思考如何消除分布式的长尾问题。然后也在探寻其他的优化点。整体性能优化,我们分成了三个方向:
- 横向优化,优化写入模型,消除分布式长尾效应。
- 纵向优化,提升单节点写入能力。
- 应用优化,探究业务节省资源的可能。
这次的性能优化,我们在这三个方向上都取得了一些突破。
优化写入模型
写入模型的优化思路是将一个BulkRequest请求,转发到尽量少的shard,甚至只转发到一个shard,来减少甚至消除分布式长尾效应。我们完成的写入模型优化,最终能做到一个BulkRequest请求只转发到一个shard,这样就消除了分布式长尾效应。
写入模型的优化分成两个场景。一个是数据不带routing的场景,这种场景用户不依赖数据分布,比较容易优化的,可以做到只转发到一个shard。另一个是数据带了routing的场景,用户对数据分布有依赖,针对这种场景,我们也实现了一种优化方案。
不带routing场景
由于用户对routing分布没有依赖,ClientNode在处理BulkRequest请求中,给BulkRequest的一批请求带上了相同的随机routing值,而我们生成环境的场景中,一批数据是写入一个索引中,所以这一批数据就会写入一个物理shard中。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
带routing场景
下面着重介绍下我们在带routing场景下的实现方案。这个方案,我们需要在ES Server层和ES SDK都进行优化,然后将两者综合使用,来达到一个BulkRequest上的一批数据写入一个物理shard的效果。优化思路ES SDK做一次数据分发,在ES Server层做一次随机写入来让一批数据写入同一个shard。
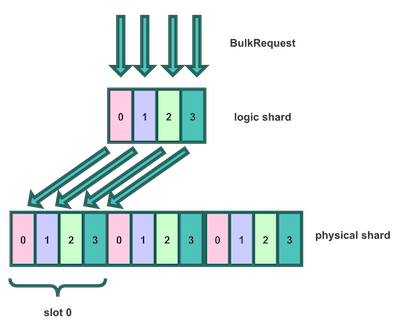
先介绍下Server层引入的概念,我们在ES shard之上,引入了逻辑shard的概念,命名为`number_of_routing_size` 。ES索引的真实shard我们称之为物理shard,命名是`number_of_shards`。
物理shard必须是逻辑shard的整数倍,这样一个逻辑shard可以映射到多个物理shard。一组逻辑shard,我们命名为slot,slot总数为`number_of_shards / number_of_routing_size`。
数据在写入ClientNode的时候,ClientNode会给BulkRequest的一批请求生成一个相同的随机值,目的是为了让写入的一批数据,都能写入相同的slot中。数据流转如图所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
最终计算一条数据所在shard的公式如下:
slot = hash(random(value)) % (number_of_shards/number_of_routing_size) shard_num = hash(_routing) % number_of_routing_size + number_of_routing_size * slot
然后我们在ES SDK层进一步优化,在BulkProcessor写入的时候增加逻辑shard参数,在add数据的时候,可以按逻辑shard进行hash,生成多个BulkRequest。这样发送到Server的一个BulkRequest请求,只有一个逻辑shard的数据。最终,写入模型变为如下图所示:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
经过SDK和Server的两层作用,一个BulkRequest中的一批请求,写入了相同的物理shard。
这个方案对写入是非常友好的,但是对查询会有些影响。由于routing值是对应的是逻辑shard,一个逻辑shard要对应多个物理shard,所以用户带routing的查询时,会去一个逻辑shard对应的多个物理shard中查询。
我们针对优化的是日志写入的场景,日志写入场景的特征是写多读少,而且读写比例差别很大,所以在实际生产环境中,查询的影响不是很大。
单节点写入能力提升
单节点写入性能提升主要有以下优化:
backport社区优化,包括下面2方面:
- merge 社区flush优化特性:[#27000] Don't refresh on `_flush` `_force_merge` and `_upgrade`
- merge 社区translog优化特性,包括下面2个:
- [#45765] Do sync before closeIntoReader when rolling generation to improve index performance
- [#47790] sync before trimUnreferencedReaders to improve index preformance
这些特性我们在生产环境验证下来,性能大概可以带来18%的性能提升。
我们还做了2个可选性能优化点:
- 优化translog,支持动态开启索引不写translog,不写translog的话,我们可以不再触发translog的锁问题,也可以缓解了IO压力。但是这可能带来数据丢失,所以目前我们做成动态开关,可以在需要追数据的时候临时开启。后续我们也在考虑跟flink团队结合,通过flink checkpoint保证数据可靠性,就可以不依赖写入translog。从生产环境我们验证的情况看,在写入压力较大的索引上开启不写translog,能有10-30%不等的性能提升。
- 优化lucene写入流程,支持在索引上配置在write线程不同步flush segment,解决前面提到长尾原因中的lucene refresh问题。在生产环境上,我们验证下来,能有7-10%左右的性能提升。
业务优化
在本次进行写入性能优化探究过程中,我们还和业务一起发现了一个优化点,业务的日志数据中存在2个很大的冗余字段(args、response),这两个字段在日志原文中存在,还另外用了2个字段存储,这两个字段并没有加索引,日志数据写入ES时可以不从日志中解析出这2个字段,在查询的时候直接从日志原文中解析出来。
不清洗大的冗余字段,我们验证下来,能有20%左右的性能提升,该优化同时还带来了10%左右存储空间节约。
生产环境性能提升结果
写入模型优化
我们重点看下写入模型优化的效果,下面的优化,都是在客户端、服务端资源没做任何调整的情况下的生产数据。
下图所示索引开启写入模型优化后,写入tps直接从50w/s,提升到120w/s。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
生产环境索引写入性能的提升比例跟索引混部情况、索引所在资源大小(长尾问题影响程度)等因素影响。从实际优化效果看,很多索引都能将写入速度翻倍,如下图所示:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
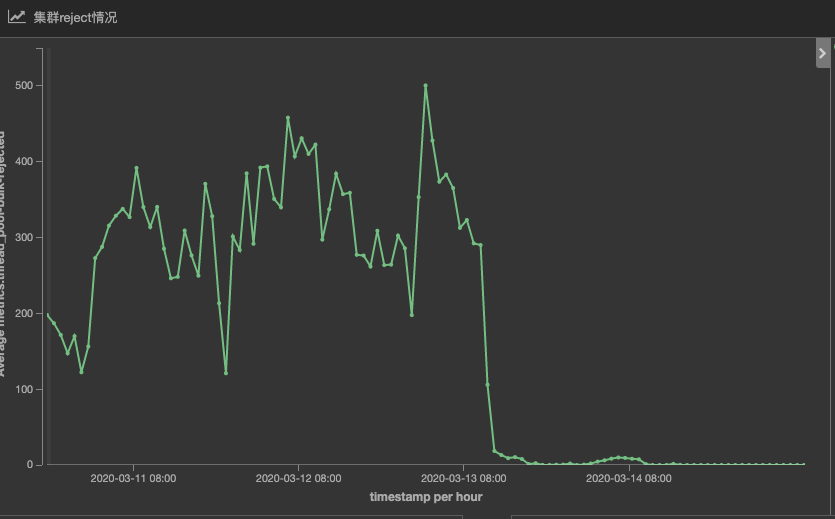
写入拒绝量(write rejected)下降
然后再来看一个关键指标,写入拒绝量(write rejected)。ES datanode queue满了之后就会出现rejected。
rejected异常带来个危害,一个是个别节点出现rejected,说明写入队列满了,大量请求在队列中等待,而region内的其他节点却可能很空闲,这就造成了cpu整体利用率上不去。
rejected异常另一个危害是造成失败重试,这加重了写入负担,增加了写入延迟的可能。
优化后,由于一个bulk请求不再分到每个shard上,而是写入一个shard。一来减少了写入请求,二来不再需要等待全部shard返回。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
延迟情况缓解
最后再来看下写入延迟问题。经过优化后,写入能力得到大幅提升后,极大的缓解了当前的延迟情况。下面截取了集群优化前后的延迟情况对比。
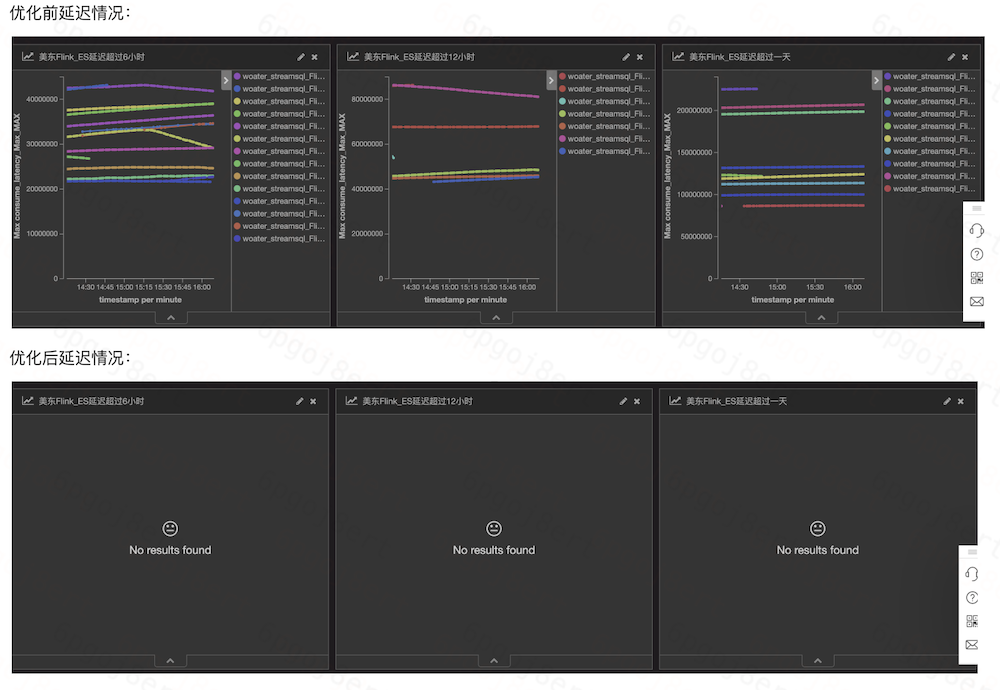
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
总结
这次写入性能优化,滴滴ES团队取得了突破性进展。写入性能提升后,我们用更少的SSD机器支撑了数据写入,支撑了数据冷热分离和大规格存储物理机的落地,在这过程中,我们下线了超过400台物理机,节省了每年千万左右的服务器成本。在整个优化过程中,我们深入分析ES写入各个环节的耗时情况,去探寻每个耗时环节的优化点,对ES写入细节有了更加深刻的认识。我们还在持续探寻更多的优化方式。而且我们的优化不仅在写入性能上。在查询的性能和稳定性,集群的元数据变更性能等等方面也都在不断探索。我们也在持续探究如何给用户提交高可靠、高性能、低成本、更易用的ES,未来会有更多干货分享给大家。
作者丨魏子珺
来源丨滴滴技术
本文原文:https://mp.weixin.qq.com/s/7UUyNPU-8y4Liib8VZ8M6g?
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【滴滴ElasticSearch千万级TPS写入性能翻倍技术剖析】(https://www.iteblog.com/archives/9850.html)