

文章目录
R目前,越来越多的用户开始在 Presto 里面使用 Alluxio,它通过利用 SSD 或内存在 Presto workers 上缓存热数据集,避免从远程存储读取数据。 Presto 支持基于哈希的软亲和调度(hash-based soft affinity scheduling),强制在整个集群中只缓存一到两份相同的数据,通过允许本地缓存更多的热数据来提高缓存效率。 但是,当前使用的哈希算法在集群大小发生变化时效果不佳。本文介绍了一种用于软亲和调度的新哈希算法,一致性哈希(consistent hashing),来解决这个问题。
Soft Affinity Scheduling
Presto 使用一种称为软亲和调度的调度策略,将一个 split(最小的数据处理单元)调度到同一个 Presto worker(首选节点)。 split 和 Presto worker 的映射关系是通过计算 split 路径的哈希值然后 mod 集群的节点数,确保相同的 split 始终被哈希到同一个 worker 上。 第一次处理 split 时,数据将缓存在首选工作节点上。当后续查询处理相同的 split 时,这些请求将再次调度到相同的 worker 节点上。由于数据已经在本地缓存,因此不需要远程读取。
为了改善负载平衡和处理不稳定的 worker,选择了两个首选节点。 如果第一个节点繁忙或没有响应,则使用第二个节点。所以数据可能在两台节点上进行缓存。
哈希算法
软亲和调度依赖于哈希算法来计算 split 和 worker 节点之间的映射。之前使用的是以下算法:
WorkerID1 =Hash(splitID) % workerCount WorkerID2 =Hash(splitID) % workerCount + 1
这种哈希策略很简单,并且在集群稳定且 worker 节点没有变化的情况下运行良好。但是,如果某个 worker 暂时不可用或停机,worker 数量可能会发生变化,这时候 split 到 worker 的映射将被完全打乱,从而导致缓存命中率显着下降。 如果有问题的 worker 稍后重新上线,这种情况将再次发生。
为了缓解此问题,Presto 在使用哈希函数计算 worker 分配时使用所有 worker 数而不是活动 worker 数。但是,这只能缓解 worker 临时离线引起的重新计算。 由于工作量波动,在某些情况下添加/删除 worker 是有意义的。在这些情况下,是否仍然可以保持合理的缓存命中率而不引入大规模的重新哈希? 解决方案是一致的哈希。
一致性哈希
一致性哈希的概念是由 David Karger 在 1997 年引入的,作为在不断变化的 Web 服务器群中分配请求的一种方式。该技术广泛用于负载均衡、分布式哈希表等。
一致性哈希是如何工作的
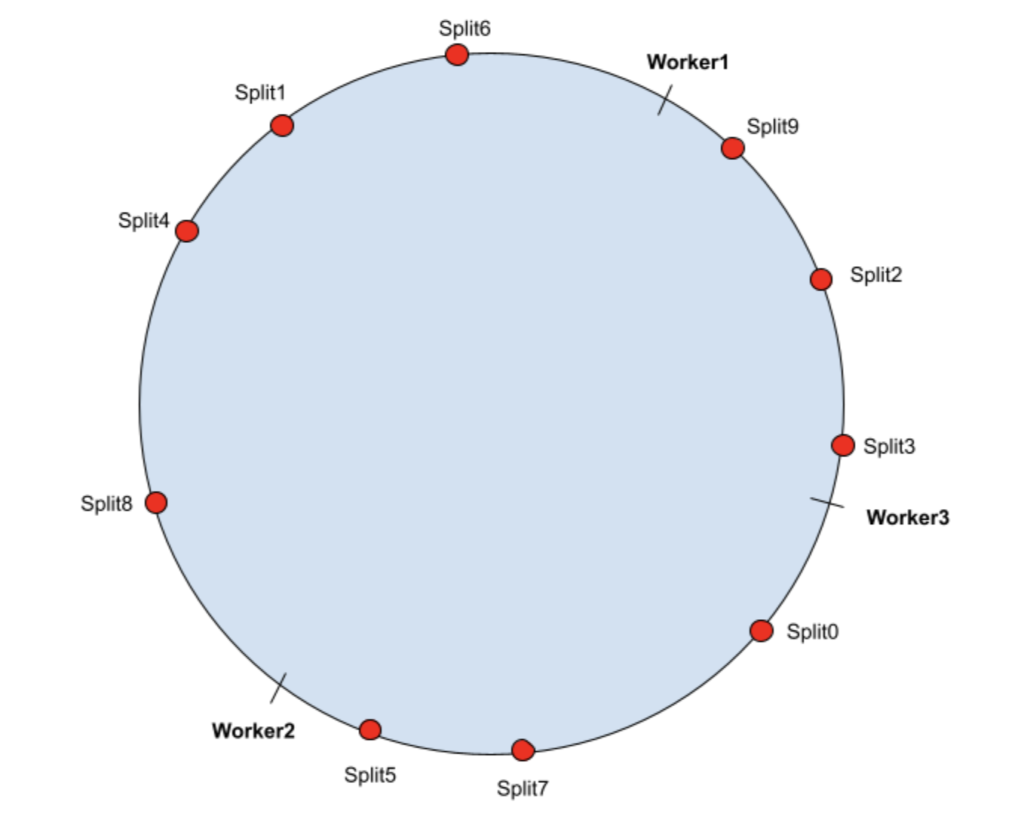
假设哈希输出范围 [0, MAX_VALUE] 被映射到一个圆上(我们将 MAX_VALUE 连接到 0)。 为了演示一致性哈希是如何工作的,假设一个 Presto 集群包含 3 个 Presto worker 节点,并且有 10 个 split 被重复查询。
首先,worker 节点被哈希到哈希环上(hashing ring)。按照顺时针方向,每个 split 都将分配给哈希环最近的 worker 上。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
在我们上图的场景下,split 和 worker 的映射关系如下表所示:
| Worker1 | Split1, Split4, Split6, Split8 |
| Worker2 | Split0, Split5, Split7 |
| Worker3 | Split2, Split3, Split9 |
删除一个节点
现在如果 worker2 因为某种原因下线了,按照一致性哈希算法,split 0、5、7 会被分配到下一个哈希值的 worker 上,也就是 worker1:
| Worker1 | Split0, Split1, Split4, Split5, Split6, Split7, Split8 |
| Worker3 | Split2, Split3, Split9 |
只有散列到离线 worker(在我们的示例中为 worker2)的 split 需要重新哈希。其他数据不受影响。 如果 worker2 稍后上线,Split 0、5 和 7 将再次被 hash 到 worker2,不影响其他 worker 的命中率。
增加一个节点
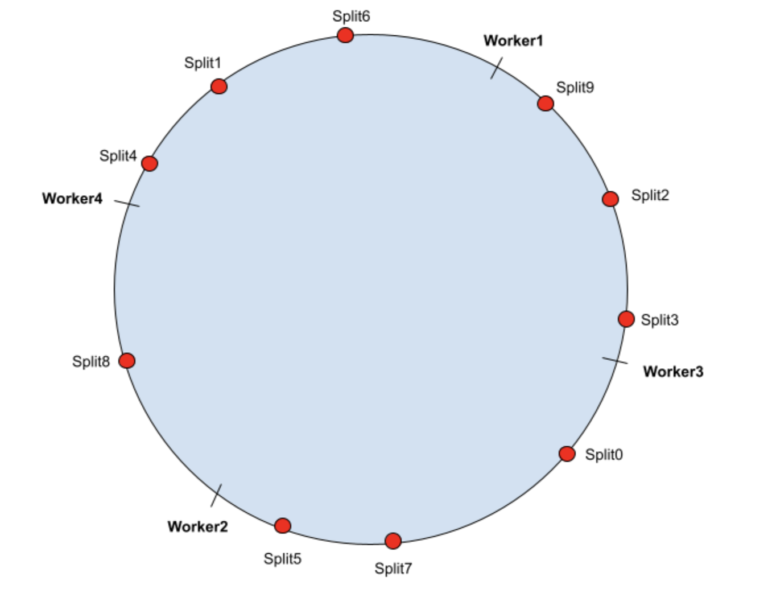
现在,如果工作负载增加并且需要将另一个 worker4 节点添加到集群中。Worker4 的哈希值在哈希环上如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
在这种情况下 split8 将落入 worker4 的范围内,所有其他 split 的分配不受影响,因此这些 split 的缓存命中率不会受到影响。 新的分配关系如下:
| Worker1 | Split1, Split4, Split6 |
| Worker2 | Split0, Split5, Split7 |
| Worker3 | Split2, Split3, Split9 |
| Worker4 | Split8 |
虚拟节点
从上面可以看出,一致性哈希可以保证在节点发生变化的情况下,平均只需要重新哈希 Nsplits / Nnodes个 splits。 然而,由于 worker 分布缺乏随机性,split 可能不会在所有 worker 节点之间均匀分布。我们可以引入“虚拟节点”的概念来缓解这个问题。 虚拟节点还可以帮助在断开连接时将节点的负载重新分配到多个节点,从而减少由于集群不稳定导致的负载波动。
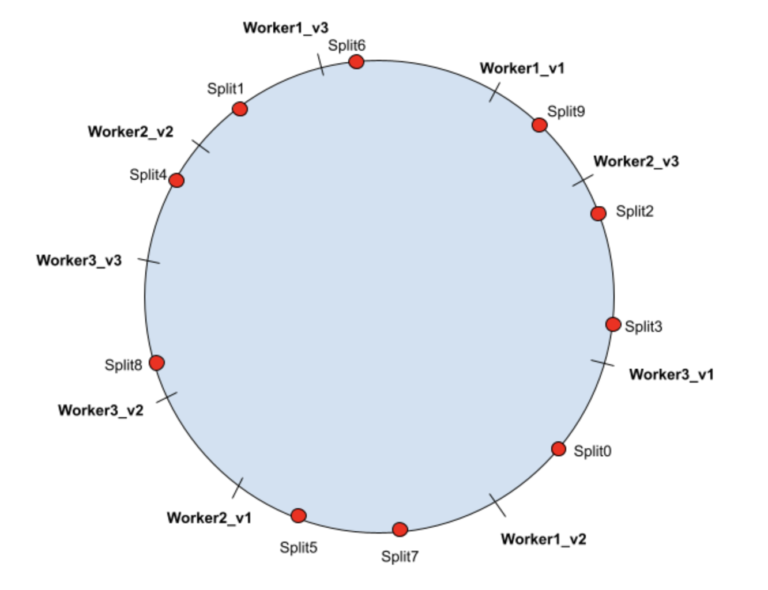
在哈希环上,每个物理 worker 节点都有多个虚拟节点映射到环上。split 将分配给哈希环上的下一个(顺时针方向)虚拟节点。 以下示例显示了每个物理 worker 节点具有 3 个虚拟节点的可能场景:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
| Worker1 | Worker1_v1 | Split6 |
| Worker1_v2 | Split0 | |
| Worker1_v3 | Split1 | |
| Worker2 | Worker2_v1 | Split5, Split7 |
| Worker2_v2 | Split4 | |
| Worker2_v3 | Split9 | |
| Worker3 | Worker3_v1 | Split2, Split3 |
| Worker3_v2 | ||
| Woker3_v3 | Split8 |
随着散列环上节点数量的增加,散列空间更可能被均匀划分。
在某个物理节点宕机的情况下,该物理节点对应的所有虚拟节点都会被删除。但现在不再将所有属于宕机节点的 spilts 重新散列到同一个节点,而是将它们分布在多个虚拟节点上,从而映射到多个物理节点,提供更好的负载平衡。
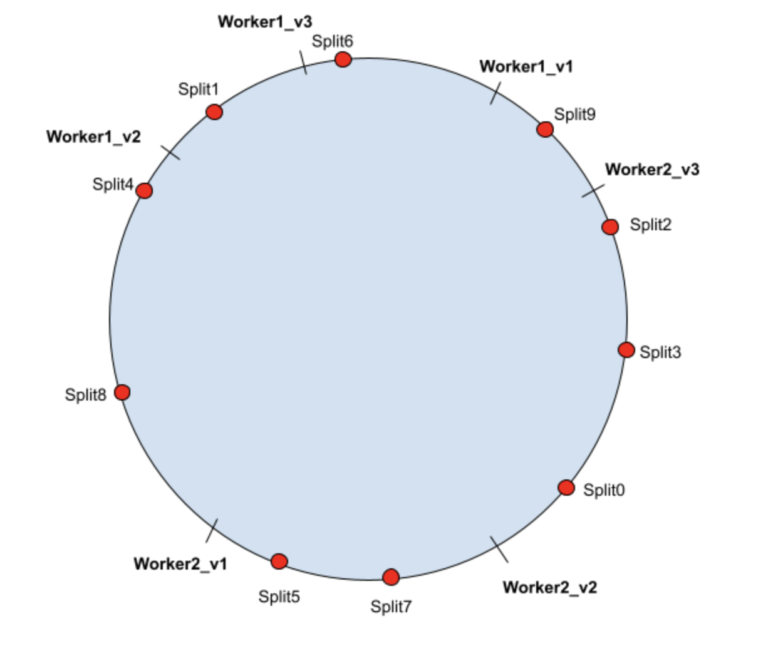
下面显示了当 worker3 被移除时,Split2 和 3 被重新散列到 worker2,而 Split8 被重新散列到 worker1。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
| Worker1 | Worker1_v1 | Split6 |
| Worker1_v2 | Split4, Split8 | |
| Worker1_v3 | Split1 | |
| Worker2 | Worker2_v1 | Split5, Split7 |
| Worker2_v2 | Split0, Split2, Split3 | |
| Worker2_v3 | Split9 |
如何在 Presto 中使用一致性哈希
一致性哈希这个功能是社区最近才添加的功能,目前处于实验阶段。为了使用这个功能,首先可以参照这个文档来启用缓存。然后确保我们选择了 SOFT_AFFINITY 调度,也就是在 catalog/hive.properties 配置文件里面加上如下配置:
hive.node-selection-strategy=SOFT_AFFINITY
启用一致性哈希需要到 config.properties 配置文件里面加上如下配置:
node-scheduler.node-selection-hash-strategy=CONSISTENT_HASHING
总结
如上所示,当引入或移除节点时,一致性哈希可以最大限度地减少工作负载分配的影响。当集群的工作节点发生变化时,基于一致性哈希调度工作负载可以最大限度地减少对现有节点缓存命中率的影响。这使得一致性哈希成为一种更好的策略,可以在 Presto 的集群大小根据工作负载需求进行扩展和缩减的情况下使用。
本文翻译自:Using Consistent Hashing in Presto to Improve Caching Data Locality in Dynamic Clusters
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【在 Presto 中使用一致性哈希来改善动态集群的缓存命中率】(https://www.iteblog.com/archives/10154.html)







