背景
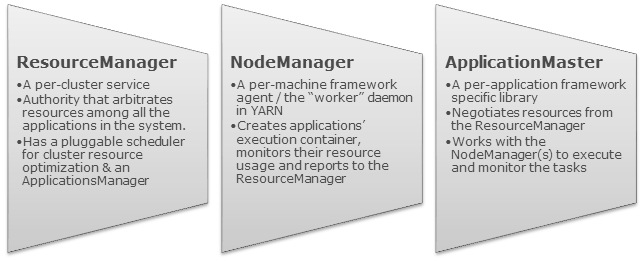
B站的YARN以社区的2.8.4分支构建,采用CapacityScheduler作为调度器, 期间进行过多次核心功能改造,目前支撑了B站的离线业务、实时业务以及部分AI训练任务。2020年以来,随着B站业务规模的迅速增长,集群总规模达到8k左右,其中单集群规模已经达到4k+ ,日均Application(下文简称App)数量在20w到30w左右。当前最大单集群整体cpu使用率,峰值通常会达到80%:
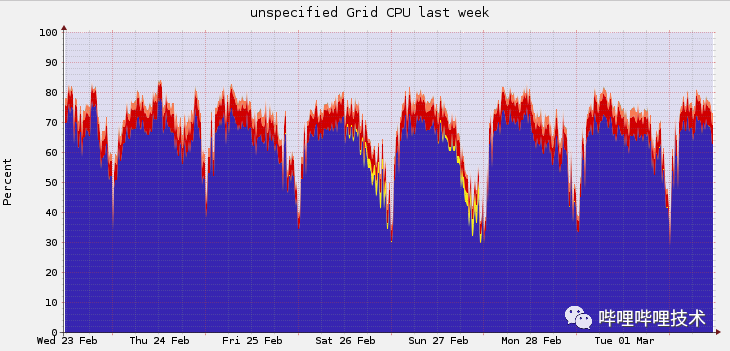
2021年,在原有的AZ1机房无法扩容的背景下,启用了AZ2机房。在每个机房中同时存在离线集群、实时集群、与在线业务混部集群,这些集群分别支持一定的业务场景。为了支撑跨机房场景,所有Client接入Federation,通过RMProxy路由到不同机房的不同集群。具体架构如下图所示:
性能评价指标
App层面
定义单个App的分配时间是其下所有Container分配时间的总和,而单个Container的分配时间可以理解为从发出申请该Container,到App实际拿到该Container之间的时间差。举个例子,假如某一App的资源获取过程如下图所示:
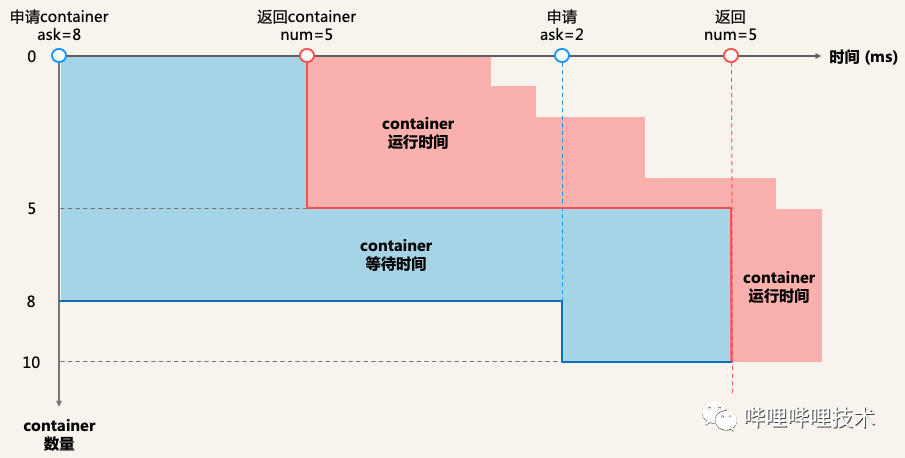
假设一开始(t0)申请 8 个Container,一段时间后(t1)返回 5 个Container,那么一共有5个Container在等待了 t1 - t0 时间后,拿到了自己的资源。如此我们便获得了5个Container的分配时间。随后(t2)又申请了2 个Container,又一段时间后(t3)返回了5 个Container。至此,该App再也不需要其它Container了。那么,按照上文所说:一共有5个Container的等待时间为 t1 - t0,有3个Container的等待时间为 t3 - t0。这就是上回没分配到的那3个Container。有2个Container的等待时间为 t3 - t2。那么该App的Container等待时间就如上图蓝色面积所示,即 5 * (t1 - t0) + 3 * (t3 - t0) + 2 * (t3 - t2)。
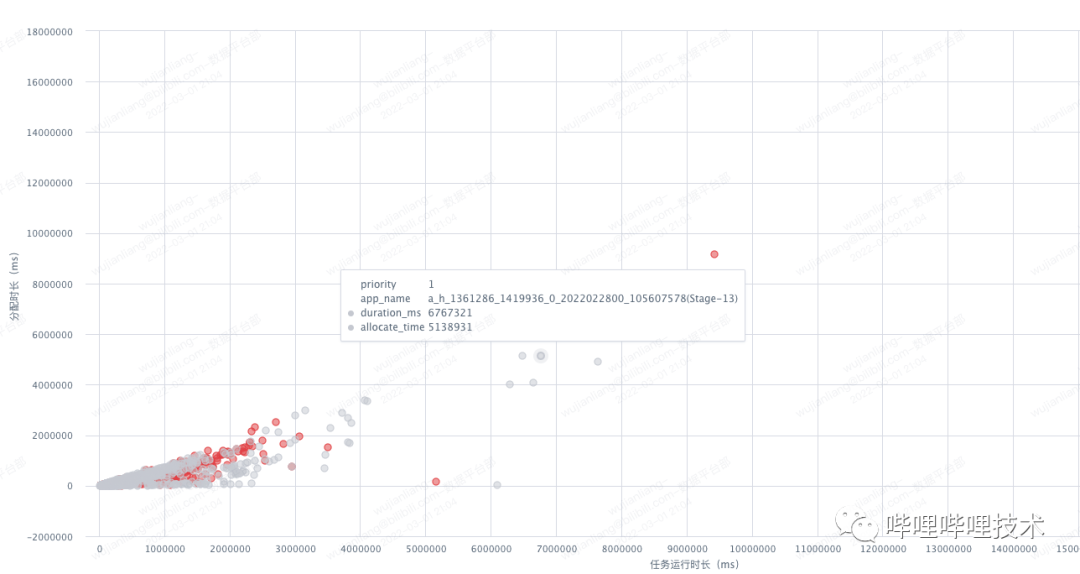
整个集群情况如上图所示,红色代表高优先级的App, 灰色则是低优先级,我们的优化目标是App分配时长占运行时长的比例越小越好。
集群层面
从业务层面如何判断调度系统是否成为系统的瓶颈,是平台层需要思考的问题。在YARN的资源设计中,通常每个业务会对应一个队列,我们从队列资源等待情况(pending),集群资源使用率(clusterUsedR),队列资源使用率(queueUsedR)这三个变量入手,定义了有效调度指标(validSchedule)的含义:当资源存在等待的情况下,若此时集群资源使用率低于一定阈值(比如90%),队列资源使用率也低于一定阈值(如95%),认为此时调度性能已无法满足该队列的资源需求。
if (pending > threshold) {
if (root.getUsedCapacity > clusterUtilization){
return 1
}else{
if (queue.getUsedCapacity > queueThreshold) {
return 1
}else {
return 0
}
}else {
return 1
}
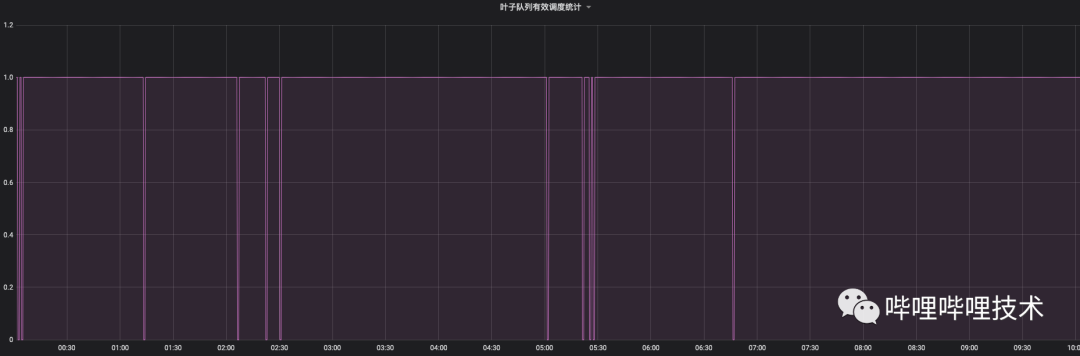
返回1即认为是当前调度满足需求,相反返回0则认为当前调度无法满足需要。如下图所示,选取某个作业量较多的队列,发现在夜间高峰时段,有效调度指标会高频次掉0,也就说高峰时段调度上还存在一些瓶颈。
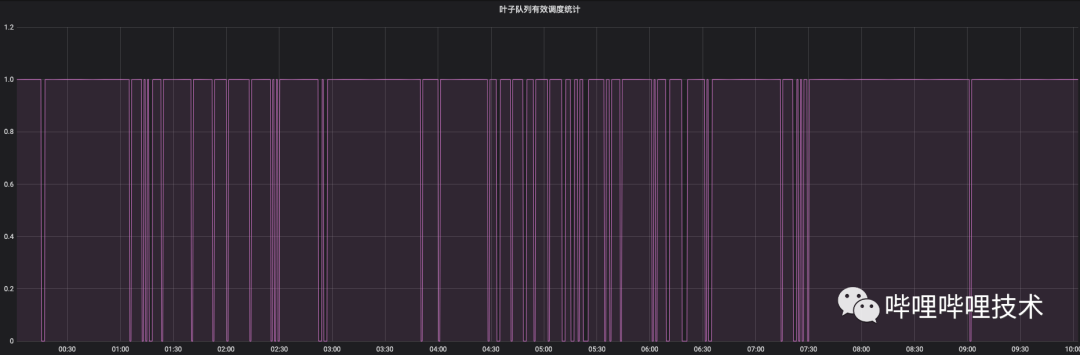
利用有效调度指标作为判断依据,当每个队列提交任务请求过多时,可以通过反压服务让Client提交等待,防止无效请求在集群中无意义的堆积。
核心调度流程
反压服务毕竟压制了用户的请求,而我们的目标是尽力满足用户的资源需求。为了达到这一目标,我们需要对YARN调度的核心流程重新进行梳理:
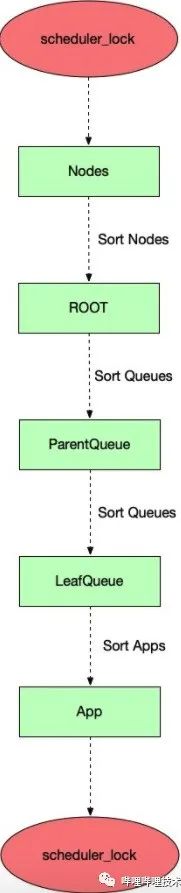
scheduler.lock
sortNodes;
for( node : Nodes ) {
sortQueues;
for (queue : Queues) {
sortApps;
assignContainer;
}
}
scheduler.unlock
上述的调度核心流程至少存在两个问题。一是Scheduler 锁从选取节点,选取队列以及App直到分配结束,这个过程的前半部分是可以剥离出来的,而调度写锁只需要锁住核心资源的变动即可;二是整个调度流程涉及多个对象的排序,这方面业界也有很多优化点。故针对这两点作出相应改进。
优化排序
从上述调度流程可知,关注的核心排序逻辑主要存在于队列和App两个层级。
在队列层面,目前我们根据不同的业务需求设置了相应的队列优先级,同时部分无法按照业务划分的作业通过在队列内部设置App优先级的方式来区别对待。对于每次分配流程而言,调度器并不是每次分配都需要感知队列资源的使用情况并触发排序的。调度器的主要精力还是聚焦于分配,故而我们在每次队列排序后,进行一段时冷却。
在App层面,目前使用的策略类似SP算法(严格优先级调度,Strict Priority),按照优先级从高到低选取,等到高优轮询结束才轮到低优,这样会存在部分低优App始终无法得到分配。经过调研发现WRR(加权轮询,Weighted Round Robin) 能够很好的解决这一问题,据此我们设计出了WRR Ordering Policy作为App层面的排序策略。
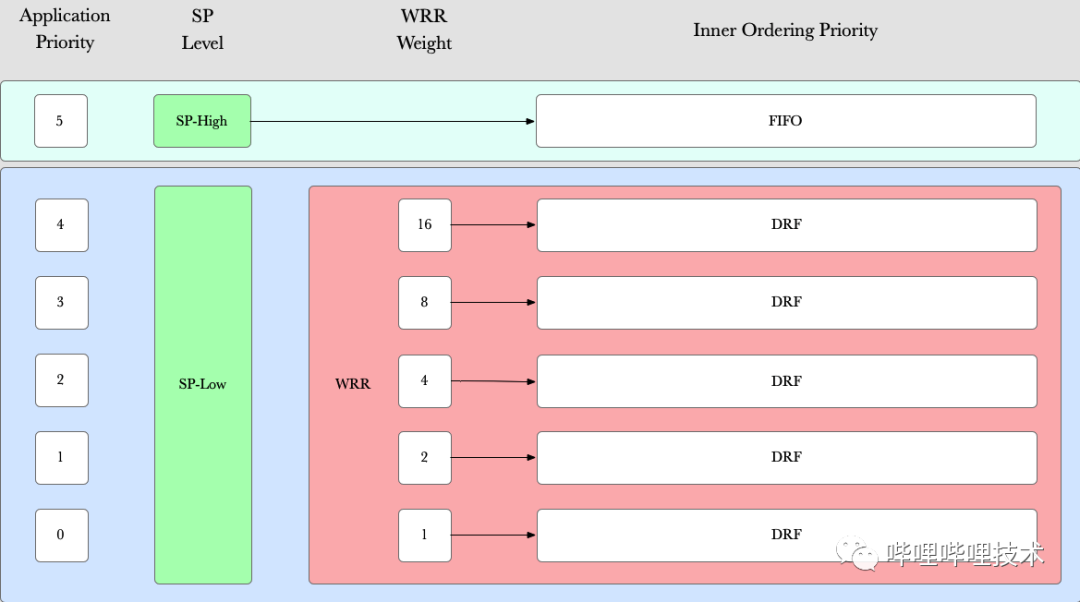
如上图所示,WRR在每个层级享受的调度机会和该层级的权重成比例。该策略首先判断是否为优先级5,若为5则执行严格的优先调度SP,先将优先级5的App全部执行完毕,之后再执行4到0优先级的App。这样设计能够确保在特殊情况下强保的App能够最快速完成。
具体来说,优先级5的App一定都是当前最重要的App,不应在其内部对App调度次序再进行比较,遵循先来后到的原则对于用户来说较有说服力,故在优先级5的内部采用FIFO作为Comparator。在一般情况下,App优先级为0(最低优)至4(次高优),此时加权轮询WRR作为App分配策略。WRR能够通过简单的计算,达到最细粒度区分不同优先级App获取资源速度的目的。而每个相同优先级内部采用DRF作为Comparator,这是由于相较于FairComparator,DRFComparator能够将VCore也纳入了比较范围,综合考虑多种资源。对DRFComparator,还引入了App分配等待因子,如果一个App等待分配时间过长,则需要把提高该App分配优先级,避免App长时间饿死。
为了观察WRR Ordering Policy的效果,我们利用压测工具SLS压测2400个节点、5000个Job,App分0~3四个优先级。压测结果如下图所示,任务完成时间按照优先级分布,且每个时段也同时存在低优任务完成,符合预期。
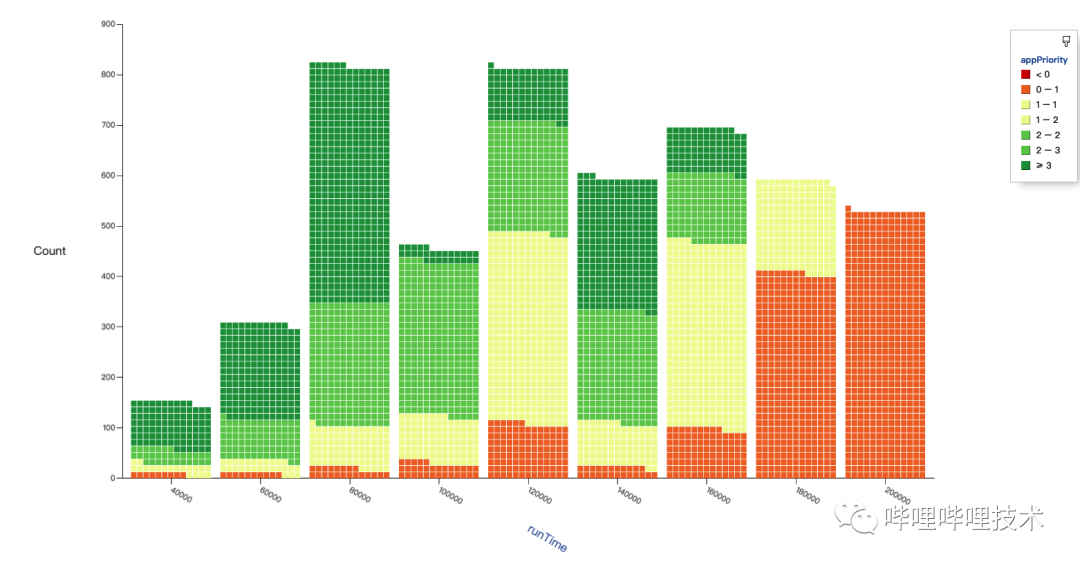
优化调度流程
单集群内节点的增长对YARN的调度性能提出了更高的要求。当RM管控的节点数量超过4000后,原先默认的心跳驱动调度(Heartbeat-Driven Scheduler)已经无法将集群的利用率持续打满。为了保证RM的调度能力与NM的增长速度匹配,我们评估了Hadoop开源社区对RM性能提升的解决方案,最终决定采用Global Scheduling的思路对当前RM调度逻辑进行改造。
名词解释
Global Scheduling:全局调度
Proposal :一次分配的提议,比如某个App要求在队列A分配<1G,2Core>资源
AsyncScheduleThread: 负责提出Proposal的线程,可并发
resourceCommitterService: 负责接受或拒绝Proposal 的线程,单线程
架构
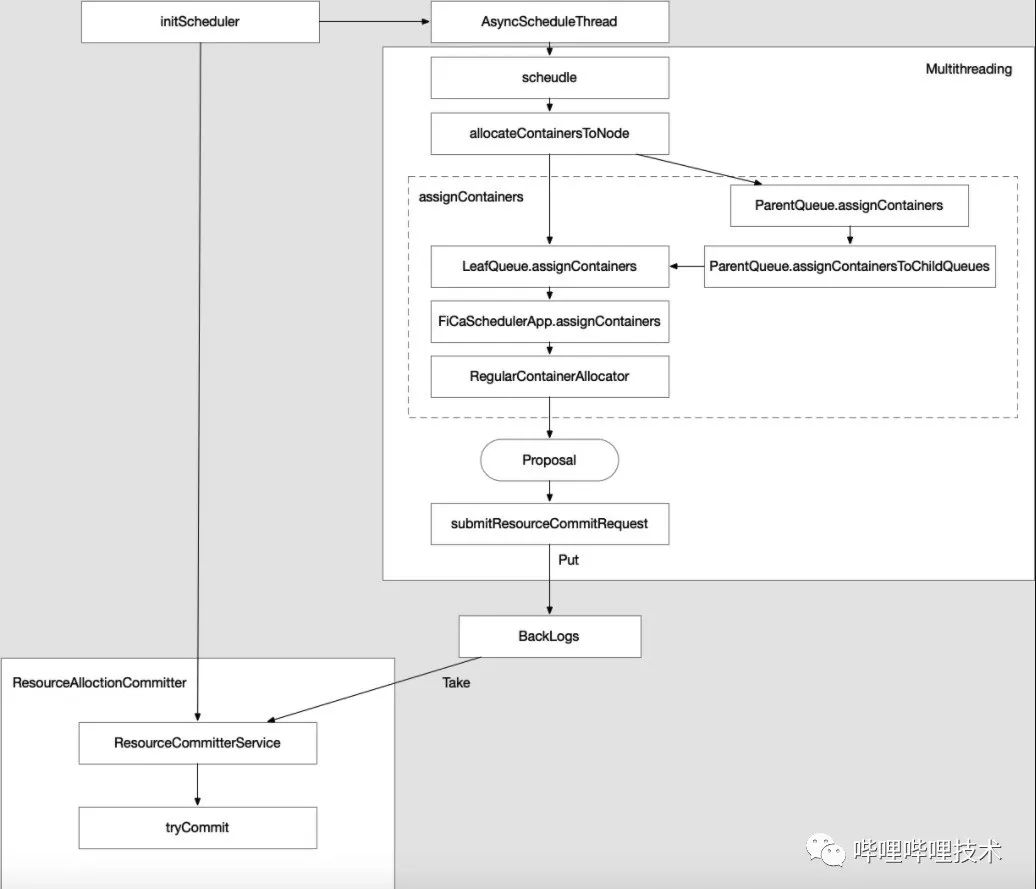
Global Schedusling的主要目标可以分为两个,第一是赋予YARN多线程调度的能力,从而提升单集群的调度性能;第二是将App的可选范围从单一Node的转变为批量Nodes(PlacementSet),从而能够支持较优节点调度、满足更复杂的资源请求。基于此,我们将Global Scheduling分为两个版本进行迭代升级,其中v1版本聚焦于YARN多线程改造,v2版本聚焦于批量节点及其选取策略改造。
YARN调度的逻辑能够分为“提出Proposal”、“消费Proposal”两个部分,目前的单线程调度逻辑将两部分在一个线程中完成,而Global Scheduling v1的主要目标是对上述两部分进行解耦,之后将“提出Proposal”的逻辑改为多线程并发,再单独生成一个线程运行“消费Proposal”的逻辑,具体框架如下图所示:
遇到问题
5.3.1 批量ERROR LOG问题
在Global Scheduling 灰度上线离线集群时,发现ERROR Log的数量在启动后陡增,检查日志后发现大量报错信息为:
Trying to schedule for a finished app, please double check.
该Log在位于CapacityScheduler.allocateContainerOnSingleNode()内reservedApplication == null的检查中触发。经过分析发现,App在执行完doneApplicationAttempt后应该继续执行doneApplication,而偶发情况下App在doneApplicationAttempt后仍会存在该App提交的Proposal,若此时另一个消费线程消费剩下的Proposal则会持续触发该ERROR Log。修复做法为在tryCommit.accept()中添加一个检查条件,若doneApplicationAttempt中remove的applicationAttemptMap查不到该App Attempt ID,则说明doneApplication已完成,直接拒绝该Proposal。
5.3.2 资源计算口径不一致导致大量Proposals失败
B站YARN对队列的资源分配分为日间版本与夜间版本,其中夜间版本会放大ETL队列的资源量,并大幅度限制Adhoc等队列的资源量。Global Scheduling v1在首次切换为夜间版本时出现了Proposal Failed Num陡增的现象。产生大量Failed是不符合预期的,预期Proposal提出的口径应该与Proposal消费的口径一致,若口径不一致,则会导致超出预期数量的失败Proposal出现。根据Failed Proposal Reason Num的监控,我们发现大量Failed位于accept()的此处:
if (!Resources.fitsIn(resourceCalculator, cluster,
Resources.add(queueUsage.getUsed(partition), netAllocated),
maxResourceLimit))
从这里倒推提出Proposal时的调用为checkHeadroom(),此处判断队列使用资源是否会超过限制,需要调用greaterThanOrEqual()方法,这样当ResourceCalculator设置为DRF时,与上述fitsIn()不一致,两者的判断逻辑不一致从而导致了大量Failed产生。同样的问题也出现在ParentQueue.canAssign()中。将提出Proposal的资源计算逻辑与消费Proposal端对齐后,切换夜间版本后分配速率恢复正常。
主要优化
我们在社区设计的基础上做了如下优化,使得Global Scheduling拥有更好的表现:
1. 精简了日志数量;
2. 多次压测确定了Backlogs长度以及多线程的线程数量;
3. 优化了Reserve Limit的逻辑,以降低Re-reservation Proposal 被接受的数量;
4. 优化了Event Queue的处理方式,以防止RM切换时产生Event堆积;
5. 优化了GC参数;
6. 新增了一批Global Scheduling相关指标的监控,能够及时准确的分析调度运行的情况。
5.4.1 精简日志数量
Global Scheduling改造首当其冲的问题就是日志数量随着多线程数量的成倍增加,大量调度过程中产生的日志严重影响了Global Scheduling在压测环境与生产环境中的性能表现,我们在考虑日志重要程度与调用频率后,将部分日志从INFO级别修改为DEBUG级别,经过对日志的精简后,Global Scheduling在压测中的表现已好于之前的心跳调度版本。
5.4.2 Backlogs长度及线程数量
在进行压测时发现,单独对Backlogs数量改变会导致压测总用时的变化。基于此,我们将Backlogs的长度改为了可动态配置的模式,通过Backlogs长度与多线程数量进行调优。经过多轮压测以及生产环境灰度验证后,最终将Backlogs长度设定为1000,多线程数量设置为4。
5.4.3 Reserve Limit优化
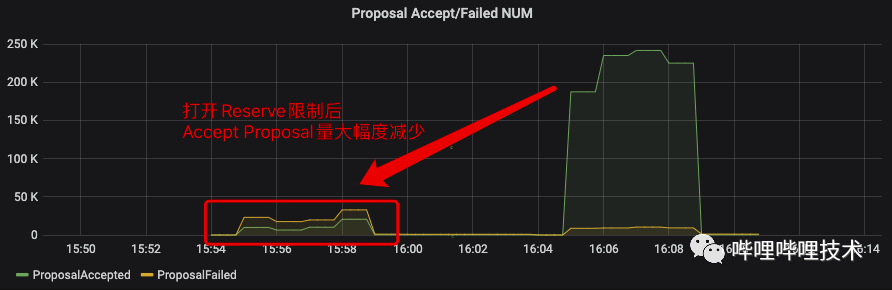
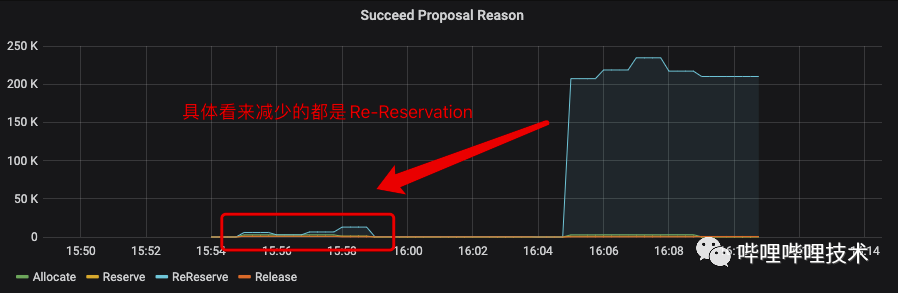
能够被成功消费的Proposal分为Allocate、Reserve、Re-reserve、Release四类,在生产集群观察到Re-reserve的Proposal数量远大于其他三种。
Re-reserve设计的初衷是为了缓解饥饿问题,但原先在RegularContainerAllocator.shouldAllocOrReserveNewContainer()中的公式似乎无法很好的与当前Global Scheduling的逻辑契合,以至于Re-reserve的数量会很轻易的达到MAX_INT。目前社区倾向于通过简化Re-reserve的计算方法及更智能的抢占来优化目前的Re-reserve机制(详见YARN-8149,YARN-9598)。
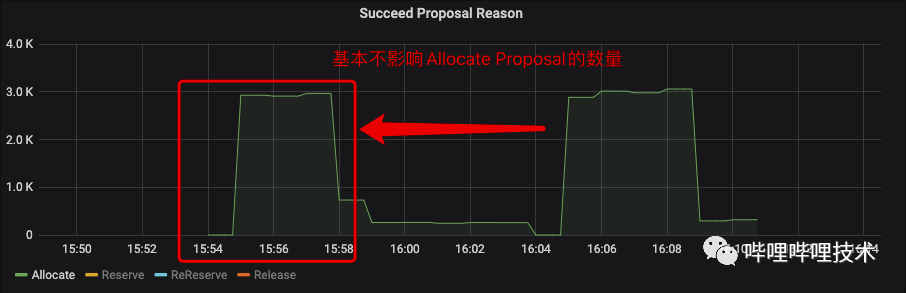
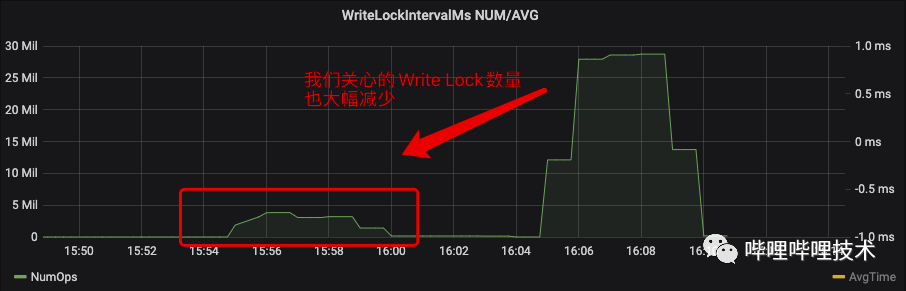
为了缓解消费线程的压力,我们在Global Scheduling的逻辑中加入了Reserve Limit功能,Reserve Limit能够控制单个App的Reserve上限。通过下图的压测结果能够看到Reserve Limit能够在不影响Allocate Proposal的基础上,一定程度上减少Re-reserve的处理次数。
5.4.4 Event Queue优化
在进行RM主备切换时,发现NodeUpdate汇报呈现逐渐缓慢的趋势,且最多仅能处理2000+左右Nodes的汇报。与此同时大量Event在Event Queue中堆积,最终导致RM在printEventQueueDetails()上浪费了大量时间去处理Event Queue的打印逻辑。因此我们将Event Queue打印逻辑拆分为一个新的线程,在不影响RM的基础上输出Event Queue信息,改动后的RM主备切换节点完全汇报时间大幅降低,能在可控的时间内完成4000+ Nodes的汇报处理工作。
5.4.5 GC优化
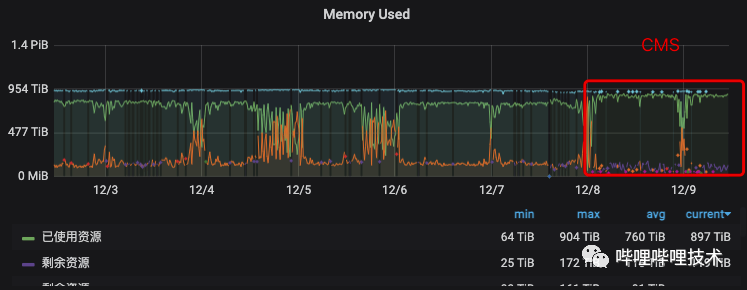
与Global Scheduling v1同步进行的还有GC的优化。经过对比,相比G1GC,我们为RM选择了在Java 8中表现的更稳定的ParNew + CMS,在此基础上对年轻代、老年代比重重新划分,并对ParGCCardsPerStrideChunk等参数进行了调优,使其对大内存回收更加高效。调优结果如上图所示,能够看到,GC的优化对YARN单集群整体利用率的提升起到了一定的正面作用。
5.4.6 监控
Global Scheduling的引入带来了新的监控指标,我们选取了以Proposal状态为中心的各类指标以排查Global Scheduling的相关问题。这些指标主要可以概括为:
1. Proposal Succeed / Failed Num
2. Succeed Proposal Reason Num
3. Failed Proposal Reason Num
4. BackLogs Num
5. Reserve Limit Match Num
其中Failed Proposal Reason Num中又可以细分为常规原因Failed与队列原因Failed两类,在队列原因的拒绝中,又能够将由于队列达到Max Limit而Failed的监控细分至LeafQueue级别。
结论
经过压测工具SLS多次压测模拟,压测参数为1W节点,运行100个Jobs,每个job 1W Container。运行完成100个job,心跳调度平均需要3min15s, 而Global Scheduling平均只需要2min, 提升约38%。
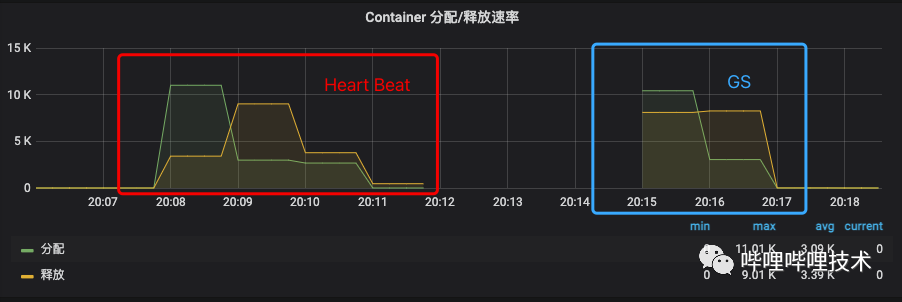
从有效调度指标进行分析,选取同样的队列,在上线Global Scheduling V1之后该指标掉0的比例有了很大改善,有效调度时长有了较大提升。
展望
本文主要介绍了大数据调度YARN在B站的落地实践,总体来说主要涉及了两个方面:
1. 引入两个调度性能的评价指标;
2. 对核心调度流程进行重构和优化。
后续我们将继续跨机房,离线实时业务混部,离线作业上云(Yarn On Kubernetes、Kubernetes Native)等在B站的实践。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache YARN 在 B 站的优化实践】(https://www.iteblog.com/archives/10165.html)