HDFS 架构介绍
HDFS离线存储平台是Hadoop大数据计算的底层架构,在B站应用已经超过5年的时间。经过多年的发展,HDFS存储平台目前已经发展成为总存储数据量近EB级,元数据总量近百亿级,NameSpace 数量近20组,节点数量近万台,日均吞吐几十PB数据量的大型分布式文件存储系统。
首先我们来介绍一下B站的HDFS离线存储平台的总体架构。

图 1-1 HDFS 总体架构
HDFS离线存储平台之前主要有元数据层和数据层,近年来我们引入了HDFS Router 扩展了接入层,形成当前的三层架构,如图1-1所示。
-
接入层,主要以HDFS Router为主,HDFS Router提供了HDFS的统一元数据视图,以挂载点的方式,记录路径与集群的映射关系,将用户对路径的请求转发到不同的NameSpace中。
-
元数据层,主要记录文件元数据信息,管理文件读写操作,是整个HDFS存储系统的心脏。
-
数据层,以存储节点DataNode为主,用于存储真实的数据。
接下来将介绍我们在接入层、元数据层、数据层的探索与实践。
接入层
基于MergeFs的元数据快速扩展
由于HDFS集群存储数据量的迅猛增长,单个NameSpace已经无法满足元数据量的快速增长,我们在经历了HDFS 联邦机制后扩展成多NameSpace,满足了一段时间的需求。但是随着集群元数据量的指数级增长,特别是小文件数量的猛增,HDFS 联邦机制逐渐无法满足当时的需求。
为了能够快速新增NameSpace以及让新增的NameSpace迅速接入已有的集群,负载新增的元数据,现有的联邦机制和社区版本的RBF也无法满足当前的要求,我们决定在RBF的基础上,深度定制开发,来解决主节点扩展性问题。
当时元数据层的压力主要来源于3个方面:
-
存量元数据数据量大,新增文件数量增长迅猛。
-
新增NameSpace无法快速进行迁移,迁移效率不足。
-
大量目录存在实时写入,历史的迁移方式需要停止写入。
为了解决元数据层扩展能力不足的问题,经过调研社区3.0的HDFS Router和业界相关方案后,我们决定在社区3.3版本的HDFS Router 的基础上,进行定制开发MergeFs来解决集群元数据层扩展性能问题,整体架构如图2-1所示:
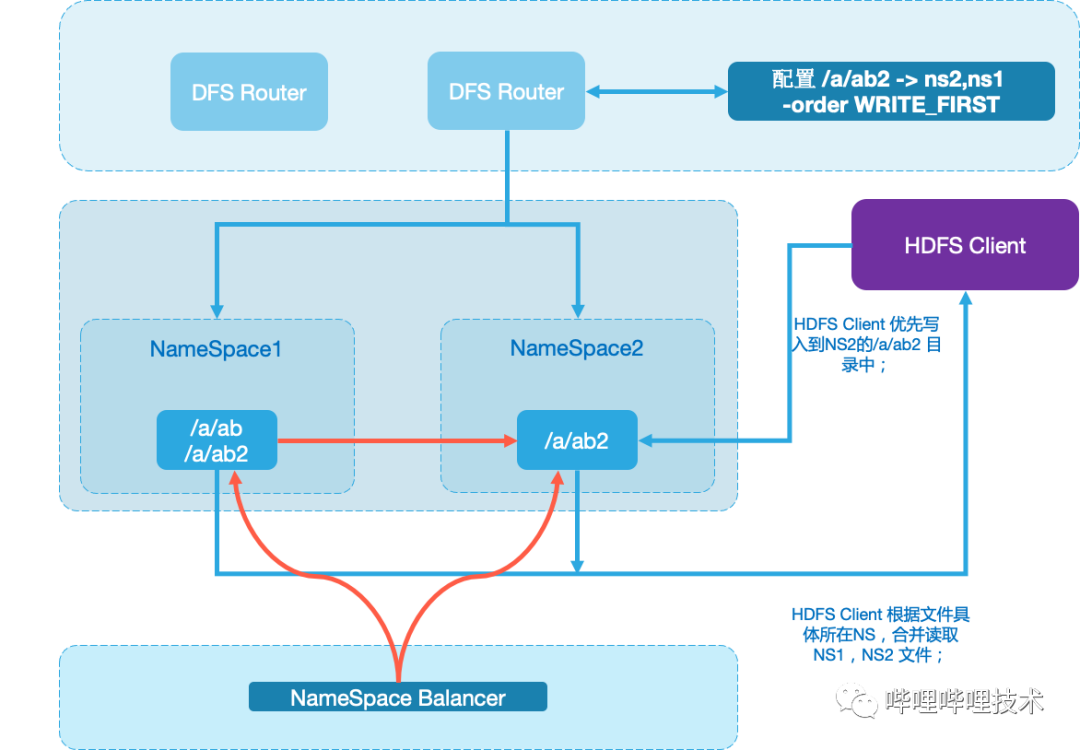
图 2-1 HDFS MergeFS 整体架构
-
在社区版本的HDFS Router 基础上,定制化开发MergeFS支持元数据迁移,MergeFS 支持按一个挂载点配置2个NameSpace,新写入数据会按规则路由到新增的NameSpace中,但历史数据仍然可见,通过这种方式,我们能迅速扩张新的NameSpace,缓解老NameSpace的写入压力。
-
建设了NameSpace Balancer工具,能在业务低峰时期自动化的异步迁移老NameSpace的历史数据到新扩容的NameSpace中,迁移完成后收归掉挂载点,最终实现路径完全迁移到新的NameSpace中。
-
基于HDFS元仓,不断分析出增长较快的目录,用于指导哪些数据需要迁移。
在支持了接入层的MergeFS后,元数据扩张不再成为瓶颈,我们扩容了14组NameSpace,支持了90亿左右的元数据总量,迁移了54亿左右的元数据。与此同时,整个集群的元数据层QPS得到了极大的提升,整体QPS从50K/s上涨到177.8K/s,整个数据迁移工作对上层数据计算任务透明,极大的减少了迁移的工作量,迁移工作量从1人/week,下降到0.1人/week。
接入层限流策略
随着集群规模的日益增长,集群任务的读写数据量也有数量级的上涨,对集群元数据层的请求如果不加以限制,往往会造成热点NameSpace,针对HDFS存储这种多租户场景,往往会影响高优先级任务的运行,因此我们对接入层Router和元数据层NameNode都做了限流策略,来保障资源向高优先级任务倾斜,如图2-2所示:
-
我们在计算引擎侧和HDFS Client段通过CallerContext透传了user和Jobid信息,首先在Router层基于用户,JobId,Optype,NameSpace permit负载判断,对于需要进行限流的请求,会对Client返回StanbyException,客户端通过指数回退策略在等待一定时间后再进行重试,最大重试次数为30次。
-
在NameNode上基于客户端透传的Job和User信息配置优先级,我们启用了FairCallQueue进行限流,同时采用基于Job信息的Job-Based Cost Provider取代了默认的User-Based Cost Provider,实现了实现作业粒度的RPC限流。
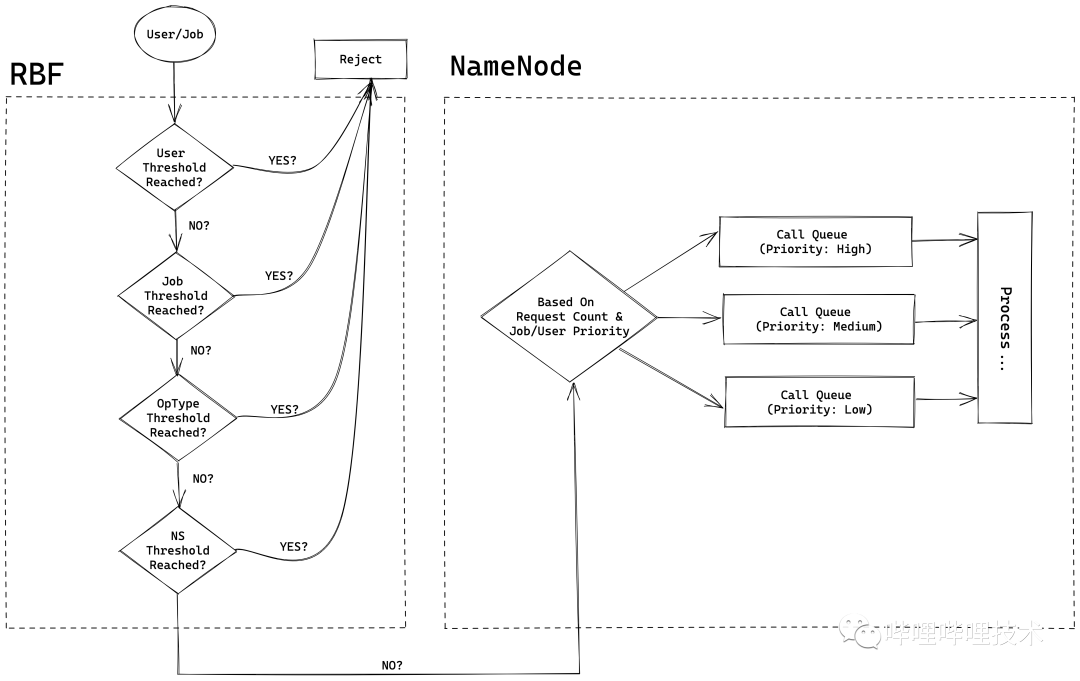
图 2-2 HDFS 流量限制
通过上述的限流策略,我们对Hive,Spark计算引擎的动态分区任务等这类短时间大量读写请求的任务有了很大的防御能力,从监控上看,Router上单个NameSpace的Permit耗尽的情况出现的概率大大下降。
接入层Quota 策略
存储数据的迅猛增长,以及数据治理推动耗时耗力,对租户数据进行Quota限制也是急需解决的问题。由于之前为了提升NameNode RPC性能,我们在NameNode上进行改造跳过了部分Quota计算的逻辑,极大的降低了NameNode在处理存在大量文件目录时的持锁时间。我们设计了基于接入层Router的quota机制如图2-3所示,将NameNode中Quota计算和校验的逻辑前置到Router中。Router中缓存了来源于HDFS元仓的路径Quota信息,目前是T+1更新,实效性不高,因此我们也正在开发基于NameNode Observer节点的准实时Quota功能,如图2-4所示。
-
改造NameNode Observer节点,支持无锁版本的getQuotaUsage接口,获取路径Quota信息对NameNode整体读写无影响;
-
Quota Service 聚合分散在多个NameSpace中的路径,实现分钟级Quota计算;
-
HDFS Router访问Quota Service获取路径使用的Quota信息,进行Quota校验;
-
Quota Service相关数据提供上层数据平台进行资产管理使用。
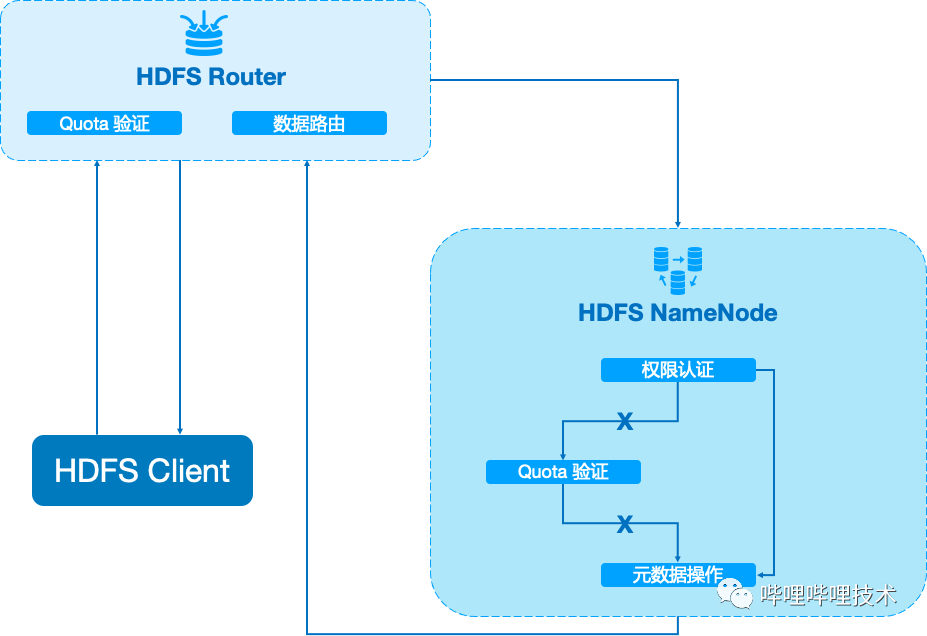
图 2-3 基于HDFS元仓的Quota机制
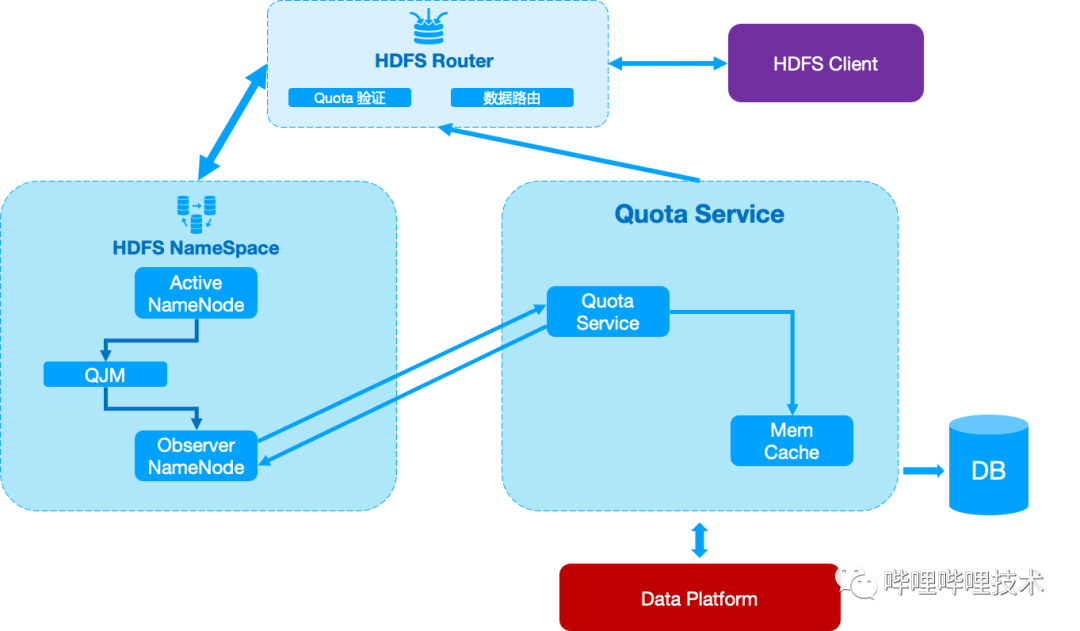
图 2-4 近实时的Quota计算服务
基于Router的Staging目录分流
由于业务的扩张,集群上并行的任务数量也迅猛增长,各种任务运行的临时文件目录如:Yarn Staing路径、Spark Staing路径、Hive scratchdir路径、Yarn Logs路径的QPS请求非常大,需要多组NameSpace进行分担才能承载,我们通过对这些路径配置HASH_ALL挂载点。
通过一致性HASH实现多组NameSpace之间的QPS负载均衡,将这些目录隔离在单独的NameSpace中,减少主集群NameNode的读写压力。
元数据层
基于RBF的Observer NameNode策略
HDFS 架构中元数据节点NameNode 的实现中存在针对目录树的全局锁,很容易就达到读写请求处理瓶颈。社区3.0版本中提出了一个Observer Read架构,通过读写分离的架构,尝试提升单个NameService的处理能力。为了提升NameNode请求处理能力,我们在社区版本的Observer机制的基础上也经过了定制化开发,基于最新的RBF框架,实现动态负载读请求路由,提升NameNode读写效率,如图3-1所示:
-
基于RBF的Observer 架构,对于HDFS Client和计算引擎完全透明,无需变更Client配置;
-
计算引擎可以通过callerContext 透传是否进行Observer读请求,适配不同的业务;
-
HDFS Router 判断是否需要进行Observer Read和msync请求,依据具体情况进行Observer Read。
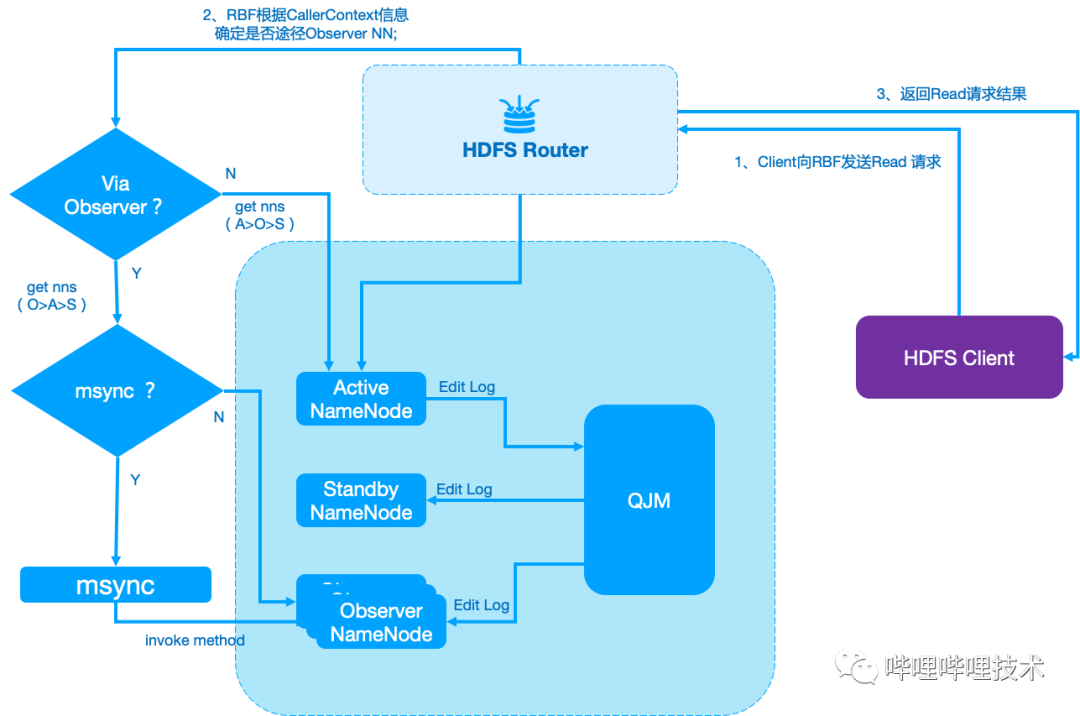
图 3-1 Observer NameNode 基础架构
在Observer NameNode功能落地过程中,我们做了许多的工作:
-
由于主集群是2.8.4 版本,而Observer功能在3.X版本才开启,因此我们合并了大量Hadoop 3.x版本中Observer相关的代码到当前版本;
-
为提升MSync RPC稳定性,我们在NameNode上开启新的9020端口,用于专门处理Msync请求;
-
新增RequeueRpcCalls监控项,监控NameNode Observer节点请求re-queue情况;
-
在RBF上支持根据用户Client透传的Callercontext信息判断是否使用Observer NameNode,便于不同业务划分。
通过Observer NameNode的扩容,单个NameSpace的处理能力迅速上涨,由于当前只有部分Adhoc查询接入Observer节点,单组NameSpace Observer节点增加平均4.5k/s左右QPS,Active NameNode 峰值QPS下降40k/s,此外Active NameNode QueueTime 峰值和平均值均有所下降,均值从23ms下降到11ms ,如图3-2,图3-3 所示:
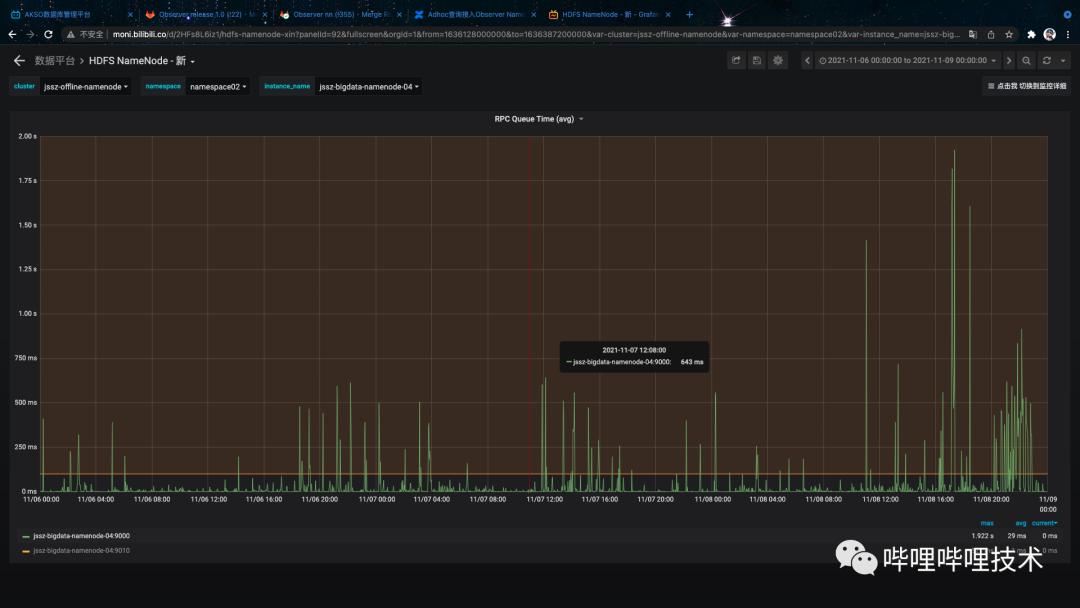
图 3-2 Observer NameNode 发布前Active NameNode QueueTime
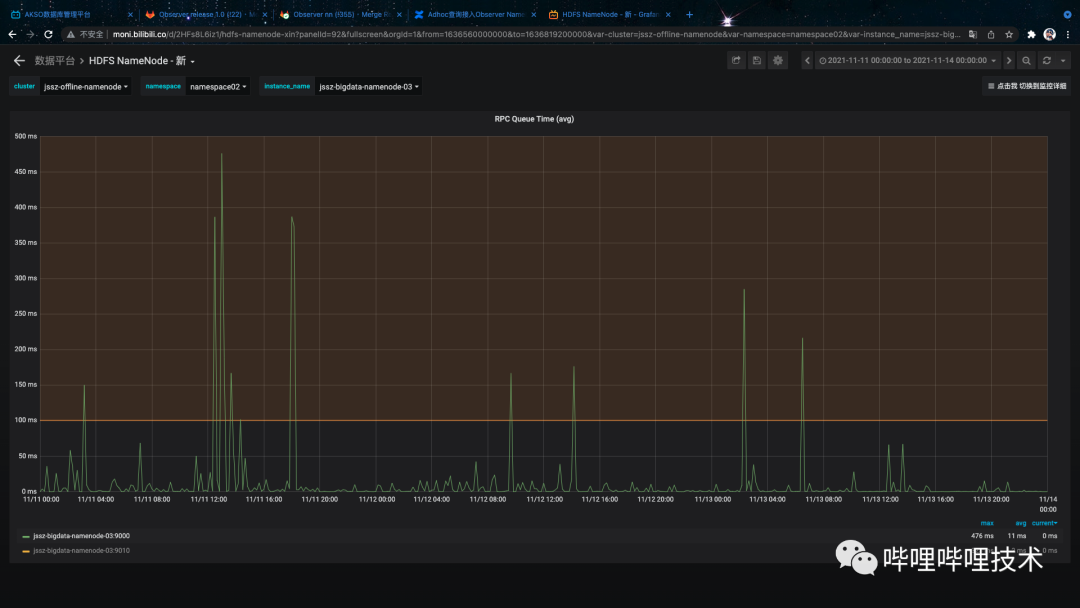
图 3-3 Observer NameNode 发布后Active NameNode QueueTime
NameNode动态负载均衡策略
当前集群由于DataNode节点和NodeManager节点混合部署,而NodeManager上运行的任务对节点负载造成的影响大小不一,HDFS文件的读写受到DataNode节点的负载影响较大,常常有慢读慢写的情况发生。为提高HDFS系统的稳定性,我们在NameNode端加以改造,实现动态的负载均衡策略,如图 3-4所示:
-
在DataNode端按照固定的时间窗口采集节点负载信息,包括IO,Load,带宽,磁盘使用率信息,通过滑动时间窗口,获取当前一段时间内负载均值信息。
-
依托 DataNode 心跳上报到NameNode节点相关负载信息,NameNode节点按照设定的权重进行汇总打分。
-
当Client请求NameNode新增Block时,NameNode每次选择DataNode时会随机选出2个DataNode节点,根据之前汇总的分数,选择负载较低的节点。
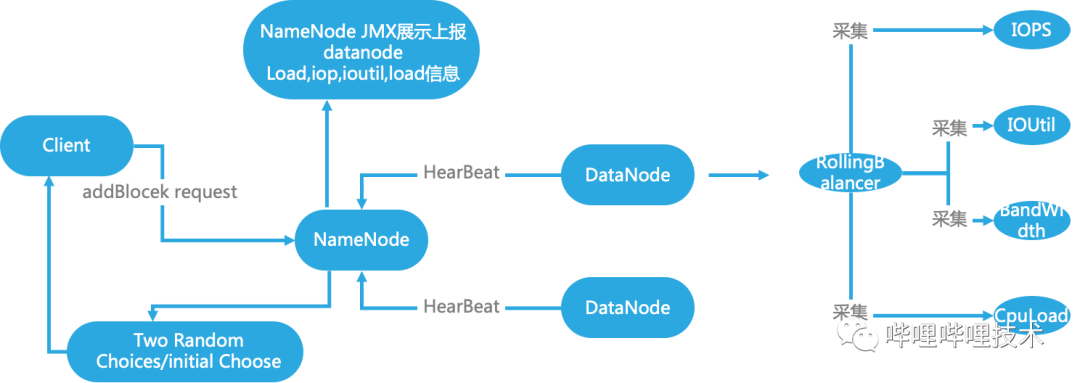
图 3-4 NameNode 负载均衡策略
NameNode 删除保护策略
在管理数据的过程中,由于多次出现数据误删的操作,HDFS原生的回收站功能不足,且事后恢复数据的工作非常困难,我们针对删除操作进行了限制,用于保护集群中存储的数据,主要有以下几点:
-
在NameNode端配置能删除的最小层级,如配置为2,则只能删除目录层级在2级以上的目录;
-
配置可动态刷新的保护目录列表,若被删除的目录包含在该列表中或是列表中某个目录的父祖目录,则禁止删除;
-
所有RPC调用的删除操作转化为移动到回收站操作,且需要经过上述最小层级验证和保护目录验证;
-
针对回收站的清理操作,只允许超级管理员用户和NameNode自动触发的回收站清理;
-
回收站清理操作在业务低峰时间进行,并对删除操作进行限流,保护删除对NameNode RPC耗时影响。
NameNode 大删除优化策略
由于集群文件大小不一,存在部分目录文件数量较多,同时开启了上述介绍的删除保护策略,每日回收站清理时会有大量的删除操作。删除操作持写锁时间长,特别是删除存在大量文件的目录时,可能持写锁达到分钟级,造成NameNode无法处理其他读写请求,因此我们参照社区实现了大删除异步化策略。从图3-5的火焰图中可以看出,删除操作持锁时间主要由removeBlocks占据,因此我们做了如下优化措施:
-
执行删除操作时,同步从父目录中删除,并收集该目录的block信息;
-
异步向DataNode发送删除数据的指令,即使NameNode在该过程中意外终止,数据会在下次DataNode块汇报时删除。
通过上述方式,有效的减少了大量文件目录删除时持锁时间,耗时从分钟级下降到了秒级。

图 3-5 NameNode delete操作火焰图
NameNode FsImage并行加载
由于HDFS单NameSpace的元数据总量上升,我们发现生产环境中NameNode节点启动时间过长(最长约80min),不仅影响运维效率, 还增加了运维重启过程中的单点风险, 一旦出现宕机等异常情况,服务将长时间不可用。因此,如何加快NameNode重启速度是我们亟待解决的问题。
经分析发现,NameNode启动信息主要包括以下四个阶段:
-
Loading fsimage:加载fsimage,并构建目录树,耗时较长。
-
Loading edits:回放EditLog,耗时一般在亚秒级,对于长达小时级的重启时间来说,该阶段可能忽略不计。
-
Saving checkpoint:Checkpoint在HDFS-7097 优化了锁粒度后,可以与Reporting blocks阶段并行,且耗时远小于Reporting blocks阶段,因此,该阶段不是NameNode重启的瓶颈, 亦可忽略。
-
Reporting blocks:隐含DataNode registering过程,并接受DataNode BlockReport汇报,耗时最长。
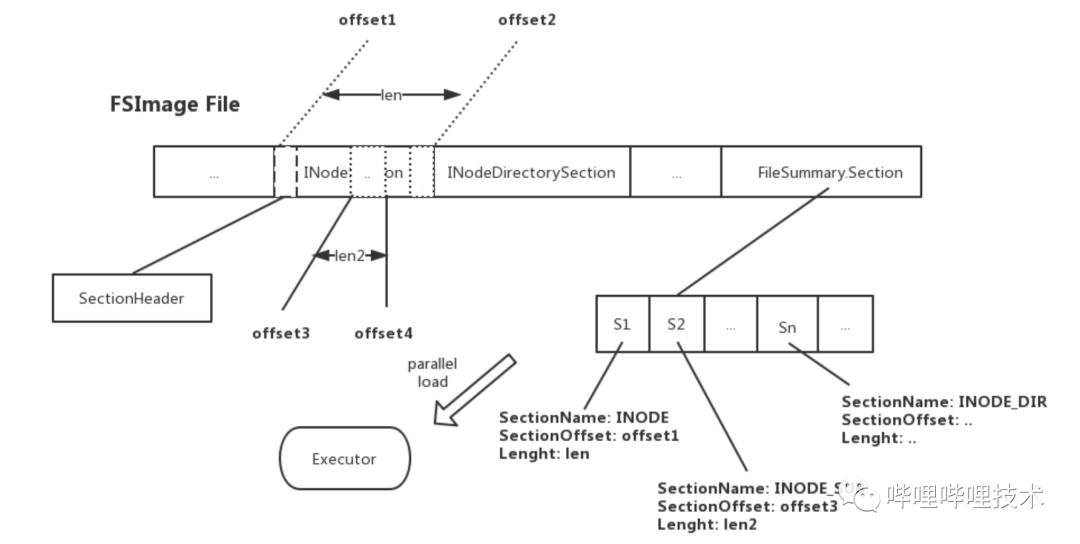
图 3-6 NameNode Fsimage 构成图
由于DataNode BlockReport存在一些方法可以进行加速汇报,我们当前只做了加载fsimage的优化加速。我们对fsimage中占比最大(90%以上)的部分为INodeSection / INodeDirectorySection进行并行(多线程)加载改造,如上图3-6所示:
-
将Section拆分为多个小Sub-Section,然后更新FileSummary Section,记录各SubSecton的信息详情;
-
加载时,依据索引启动并行的任务,去加载SubSection对应的区间数据,来达到并行加载的目的,缩短加载时长。
通过采用FSimage并行加载机制,NameNode启动时间有了明显的下降,从大约80min下降到了50min 左右,后续我们也会继续优化BlockReport时间,进一步降低启动耗时。
HDFS数据元仓
HDFS元仓是HDFS所有文件路径的大小信息,读写信息和对应表信息的汇总,基于每日凌晨产出的HDFS文件镜像和HDFS 审计日志以及Hive元数据信息,通过一系列ETL任务,生成HDFS 文件信息宽表,积累一定时间段数据后,我们可以获取目录文件增长,文件访问信息等数据,用于指导数据治理和数据冷存等业务的开展,具体架构如图3-7所示:
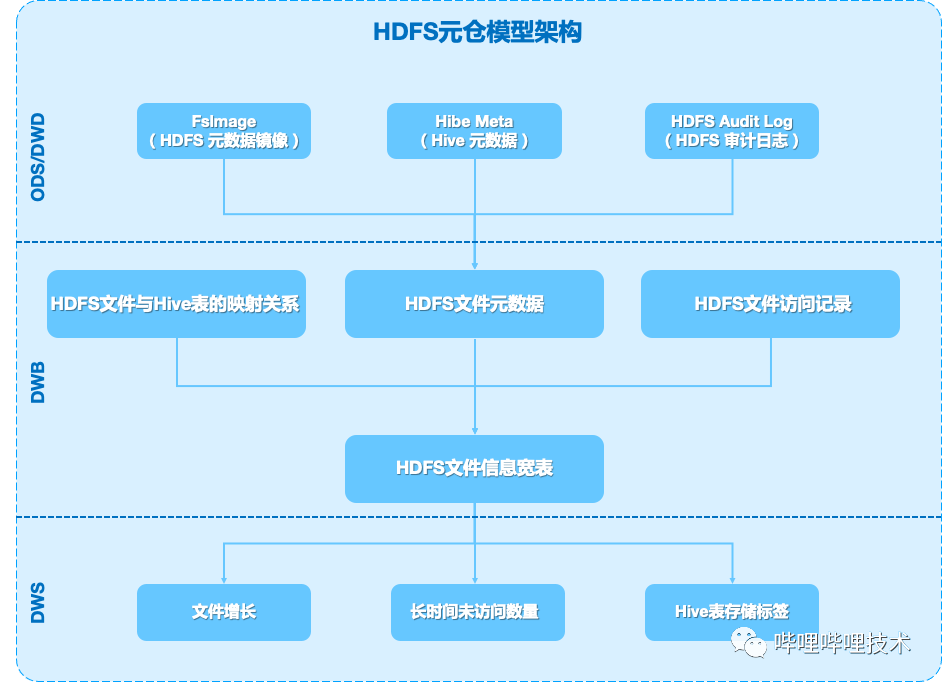
图 3-7 HDFS 元仓模型架构
用数据思维指导数据治理,在HDFS元仓搭建完成后,我们和公司内数仓数据治理团队,SRE团队一起,多次推动数据治理,建设HDFS水位预警机制,输出数据使用报表,推动用户数据自治。
Smart Storage Manager 管理工具
Smart Storage Manager是Intel开源的智能存储管理系统,可以智能的管理HDFS上的数据,包括自动化使用异构存储,HDFS Cache,小文件合并,块级别的EC和数据压缩等,主要架构如图3-6所示。我们引入了SSM服务结合HDFS元仓建设了B站自己的HDFS数据管理服务,当前主要用于冷存数据转换服务。
-
基于元仓信息,分析HDFS路径一定周期内的访问次数来判断是否需要冷存,生成相应的SSM规则。
-
SSM Server 根据上述元仓产生的规则自动化进行数据冷备。
-
后续我们将不断拓展SSM服务,支持对用户透明的数据EC策略的等优化措施。
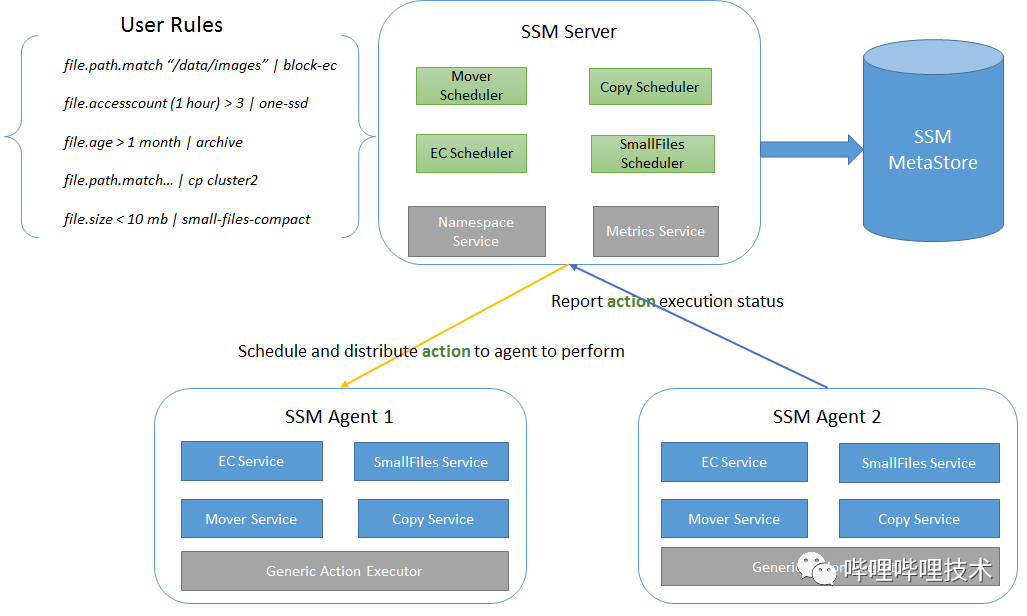
图 3-8 HDFS Smart Storage Manager 架构
数据层
HDFS 数据层的问题主要是Client写入的问题,在一个复杂的分布式系统中,热点的存在始终无法避免,我们所做的就是尽力保障整个HDFS读写的稳定性。
HDFS Client写入慢节点处理策略
HDFS是一个复杂的分布式存储系统,其中各个节点负载不一,写入非常容易遇到慢节点问题。为解决此类问题,我们陆续推出了Pipline Recovery策略和FastFailover策略提升写入的效率。
-
HDFS Client 统计写入单个packet耗时,同时判断写入一个Block数据量,如果写入Block的数据量低于50%的Block Size,且写入Packet的耗时超出设定的阈值,则剔除导致写入慢的DataNode节点
-
HDFS Client 进入 Pipline Recovery 状态,重新向NameNode申请新的DataNode ,重建pipline,恢复写入流,如图4-1所示。
-
如果写入Block的数据量高于50%的Block Size时,且写入Packet的耗时超出设定的阈值,则提前结束当前block,开启新的block进行写入,如图4-2所示。
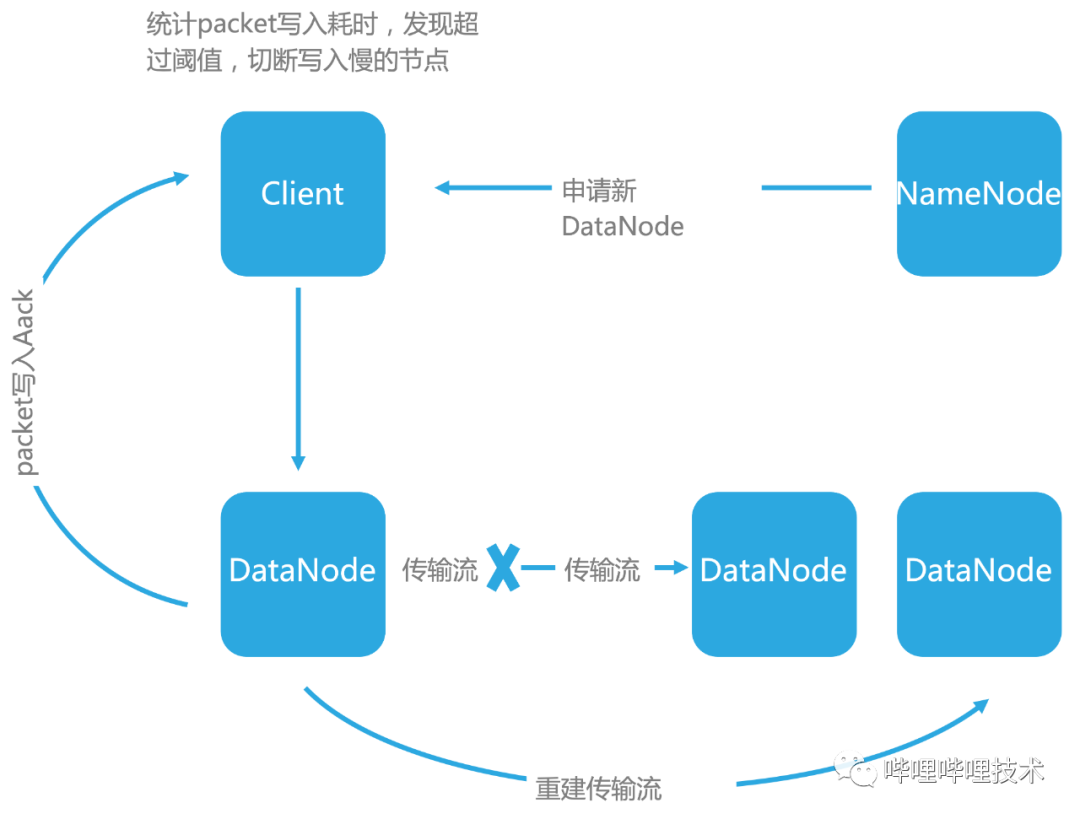
图 4-1 HDFS Client Pipeline Recovery 策略
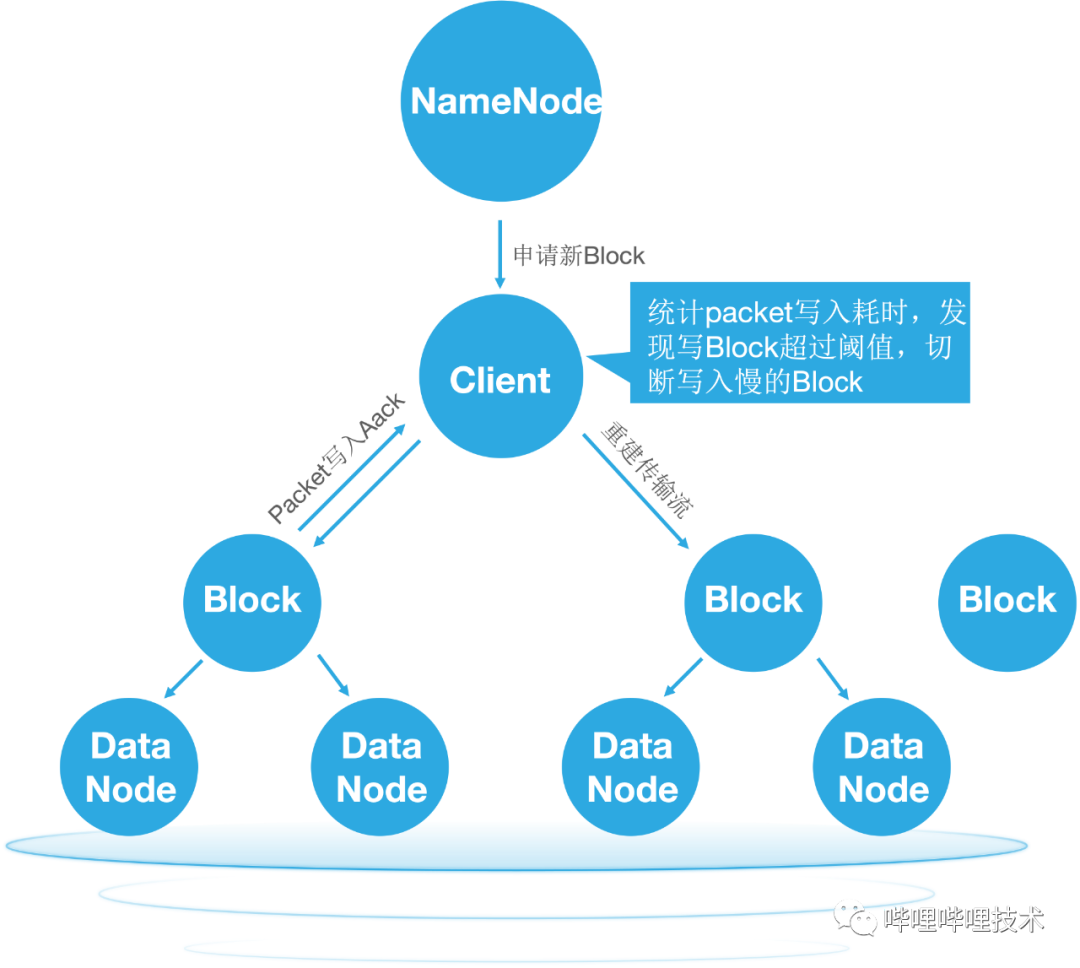
图 4-2 HDFS Client FastFailover 策略
通过上述的Pipeline Recovery策略和FastFailover策略,HDFS客户端的读写能力有了很大的提升。写入packet长尾时间从分钟级下降到秒级,平均耗时(遇到慢节点的情况)从秒级下降到毫秒级如图4-3、图4-4所示。目前Pipline Recovery策略触发次数大约在50次/s,触发FastFailover策略大约在100次/24H。
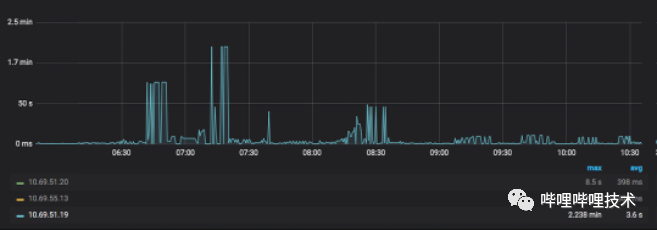
图 4-3 未进行优化措施
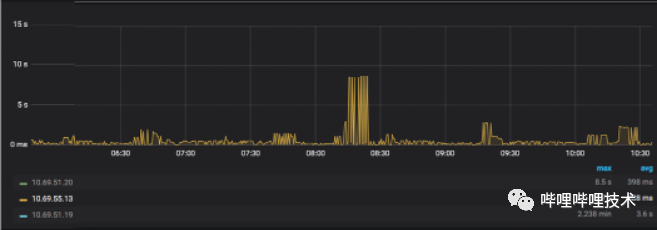
图 4-4 支持Pipeline Recovery策略和FastFailover策略后
HDFS Client FastSwitchRead功能
客户端访问HDFS存储系统读取文件时,会访问NameNode获取文件的全部或者部分block列表,每个block上带有按距离排好序的datanode地址,客户端拿到block的位置信息后,对于每个block,选择距离客户端最近的datanode,建立连接来读取当前block的数据。如果连接的DataNode正好属于慢节点,则极有可能导致读取文件速度变慢。因此我们采用以下两种方式优化HDFS Client读取数据。
-
基于时间窗口吞吐量的慢节点切换
每个block包含多个packet,hdfs client在读取数据的时候,是按照packet来读取的,因此,我们假设block-1有d1,d2两个副本,n个packet,同时,我们设定时间窗口为64ms(即当时间窗口超过64ms计算一次吞吐量),初始吞吐量的阈值为4474bytes/ms,如下图所示:
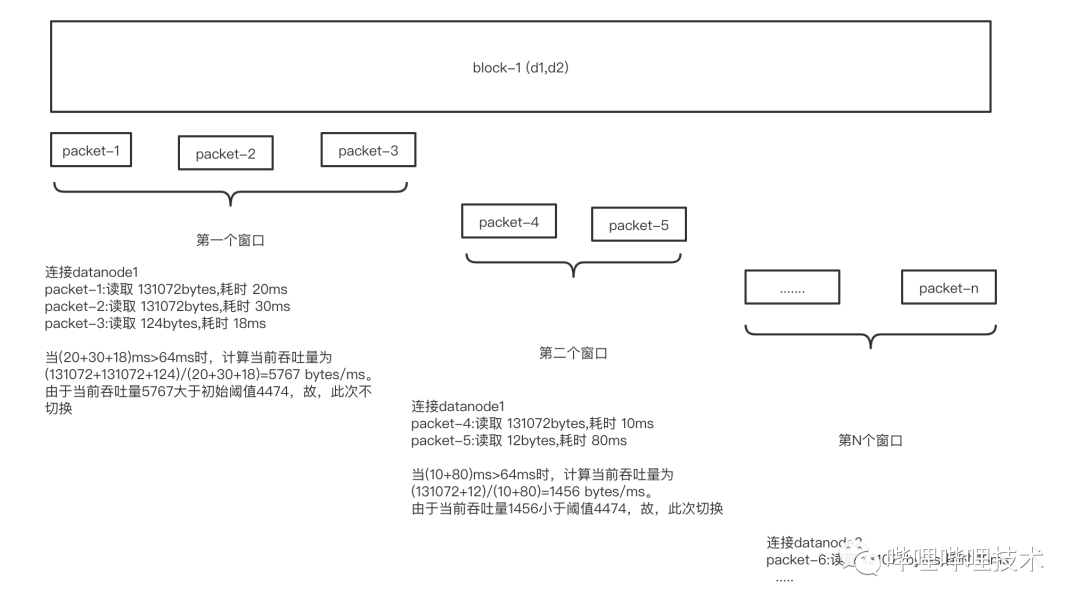
图 4-5 基于时间窗口吞吐量的慢节点切换
-
基于动态调整超时时间的慢节点切换
从上述基于时间窗口吞吐量避免慢节点可知,计算吞吐量有个前提是,当前packet必须读取完成,而通常会有在一个慢节点上读一个packet耗时较长(如读一个packet耗时超过1分钟)的现象,为了避免这样情况发生,保证遇到慢节点时切换足够敏感,我们通过动态调整客户端与DataNode的 read socket timeout超时参数,来实现慢节点的切换,我们从一个较小的超时时间(128ms)开始配置,每次切换后超时时间*2,最大时间不超过30s。
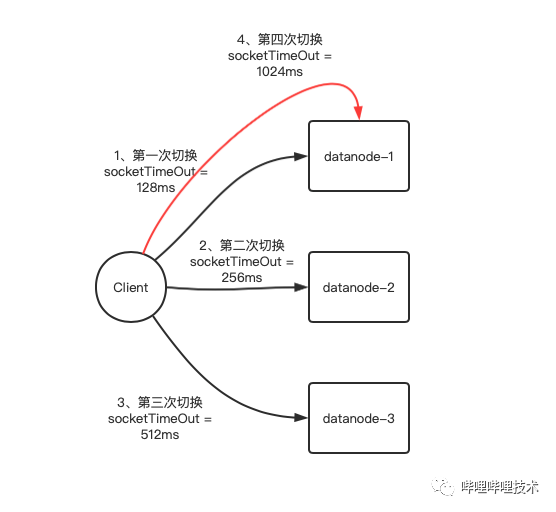
图 4-6 基于动态调整超时时间的慢节点切换
DataNode拆锁优化
-
DataNode offerService线程同时负责heartbeat/fbr/ibr多种工作,经过分析Top20慢DataNode日志发现,部分时段processCommand耗时可达分钟级, 该操作会阻塞其会阻塞ibr过程,导致block汇报延迟,影响close效率,为解决该问题,对processCommand操作进行异步化处理;
-
DataNode 锁优化:DataNode Server端数据处理使用的是排它锁,当存在IO打满、Load高等情况时,单操作持锁时间变长,将影响RPC吞吐;为解决该问题, 将排它锁转换为读写锁,让读操作并行起来,减少整体的持锁时间, 增加RPC吞吐;
如下图所示,经过拆锁优化后,WriteBlockAvgTime 有了很大的提升。
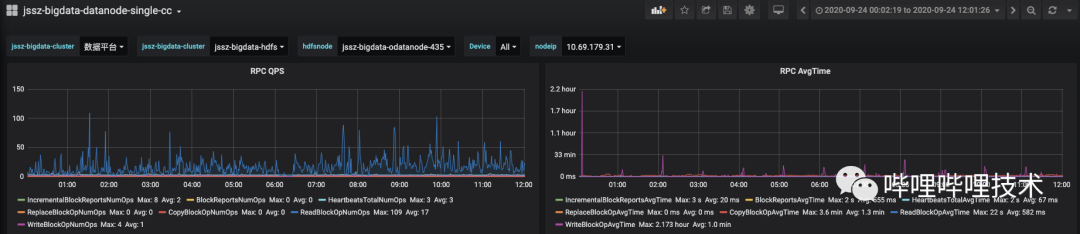
图 4-7 升级前DataNode RPC处理均值
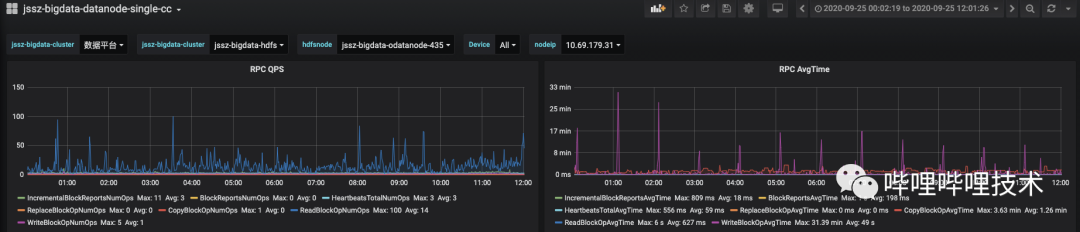
图 4-8 升级后DataNode RPC处理均值
多机房专项
随着集群规模的不断扩大,同时由于单个机房机位达到机房上限无法提供更多的机位用于部署HDFS存储节点,而单纯在异地机房部署DataNode节点会带来无法预计的带宽问题。因此为了集群的持续发展,以及跨机房网络的带宽瓶颈和网络抖动问题,我们设计并建设了HDFS多机房体系。
-
在异地机房部署相同的HDFS和YARN集群。
-
通过Router挂载点信息确定数据存储机房。
-
在任务调度服务上配置DataManager服务,用于判断任务调度机房信息。
-
任务统一提交到RMProxy根据任务/用户/队列等mapping关系自动路由到相应机房的Yarn集群。
-
公共依赖数据由Transfer服务拷贝镜像数据到异地机房,并做TTL管理。
-
任务跨机房数据读写统一接入限流服务,保障跨机房带宽。
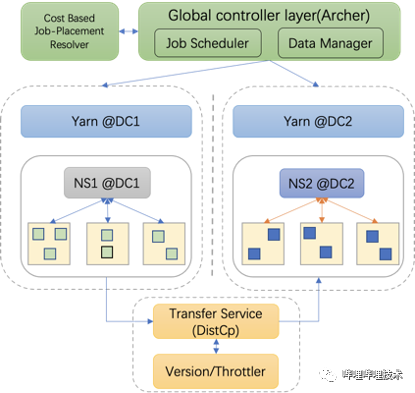
图 5-1 多机房体系架构
整个跨机房体系联动了许多部门,整体架构较复杂,涉及到调度,存储,计算引擎和工具侧改造,在这就不多做赘述了,后续我们会针对跨机房项目单独分享一篇文章介绍。
未来规划
对用户透明的EC策略
由于总体数据量的膨胀,对总体储存的消耗也与日俱增,为了响应公司整体降本增效的战略,我们准备对大量数据进行EC处理。EC即ErasureCoding,通过对存储数据进行编码,能有效降低总存储量,提升存储的稳健性。为了尽快开展EC工作,并且做到对各种用户的读写方式透明,我们预期做到以下几点:
-
开发EC Data Proxy Sever(Datanode端实现) 兼容老版本客户端读EC数据。
-
合并 EC相关Patch 到当前使用的HDFS 客户端。
-
单独部署3.x版本HDFS集群存储EC数据。
-
HDFS Router研发支持EC挂载点,EC数据读写对用户透明。
-
开发对用户透明的自动化EC转换工具,数据校验工具。
冷热温三级数据路由策略
由于数据热点的存在(如部分公共Hive维表等)经常导致DataNode节点整体IO打高,影响该DataNode上其他的数据读写受阻,我们计划引入Alluxio组件,支持热点数据缓存,在Router改造挂载点,使其支持挂载点冷热温三级数据类型,自动化路由到对应的目录。同时支持HDFS元仓自动化分析数据访问热度,数据按访问热度自动降级为冷存或EC数据。
NameNode拆锁
随着元数据层的扩展,我们当前已经扩展到十几组的规模。但元数据层的扩容不可能是无限制的,同时各组NameNode的qps请求不均衡,非常出现热点NameSpace的存在,因此对NameNode进行优化的工作也是必不可少的。考虑到NameNode锁机制,写操作会锁住整个目录树,我们计划对NameNode目录锁进行优化,提升NameNode读写能力。
Hadoop 3.x版本升级
为了支持HDFS的EC策略,我们计划新建3.x版本HDFS集群,用于存储EC数据,由于3.x版本集成了很多HDFS相关优化,在读写兼容的情况下,我们计划用3.x版本慢慢替换掉现有的2.x版本的HDFS集群。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【HDFS 在 B 站的探索和实践】(https://www.iteblog.com/archives/10164.html)