

背景
熟悉大数据的人应该都知道,HDFS 是一个分布式文件系统,它是基于谷歌的 GFS 思路实现的开源系统,它的设计目的就是提供一个高度容错性和高吞吐量的海量数据存储解决方案。在经典的 HDFS 架构中有2个 NameNode 和多个 DataNode 的,如下:
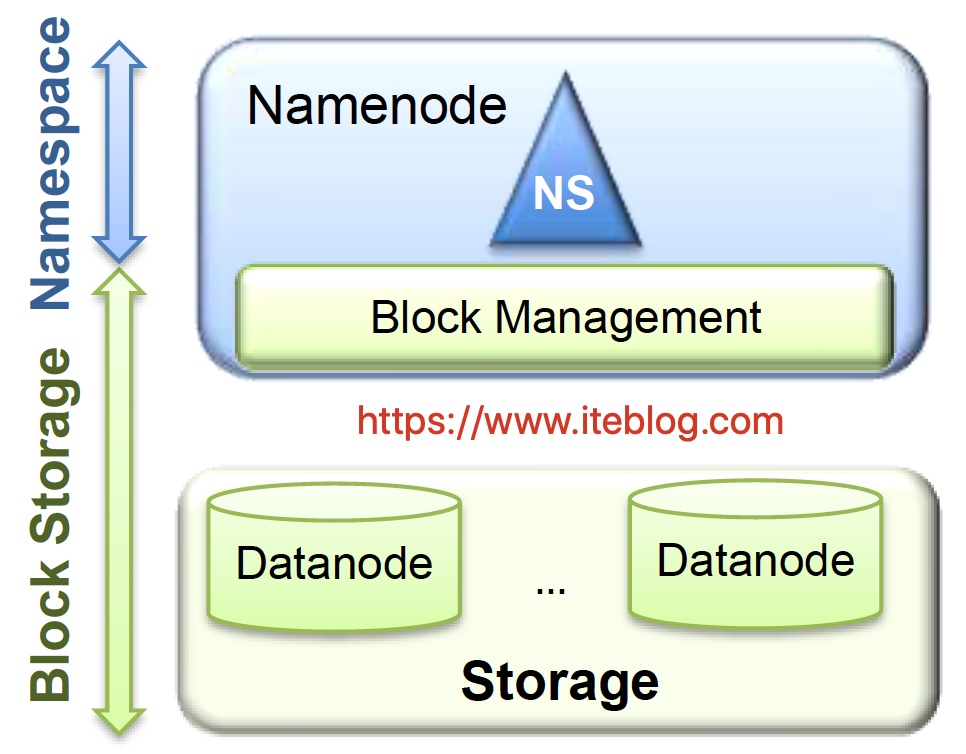
从上面可以看出 HDFS 的架构其实大致可以分为两层:
- Namespace:由目录,文件和数据块组成,支持常见的文件系统操作,例如创建,删除,修改和列出文件和目录。
- Block Storage Service:这个部分又由两部分组成
- 数据块管理(Block Management),这个模块由 NameNode 提供
- 通过处理 DataNode 的注册和定期心跳来提供集群中 DataNode 的基本关系;
- 维护数据到数据块的映射关系,以及数据块在 DataNode 的映射关系;
- 支持数据块相关操作,如创建,删除,修改和获取块位置;
- 管理副本的放置,副本的创建,以及删除多余的副本。
- 存储( Storage) - 是由 DataNode 提供,主要在本地文件系统存储数据块,并提供读写访问。
- 数据块管理(Block Management),这个模块由 NameNode 提供
虽然这个架构可以很好的处理海量的大数据存储,但是当文件比较多,特别是集群运行了很长时间产生大量小文件的情况下,这种架构的 NameNode 就会产生很严重的问题。这是因为集群中数据的元数据(比如文件由哪些块组成、这些块分别存储在哪些节点上)全部都是由 NameNode 节点维护,为了达到高效的访问, NameNode 在启动的时候会将这些元数据全部加载到内存中。而 HDFS 中的每一个文件、目录以及数据块,在 NameNode 内存都会有记录,每个数据块的信息大约占用150字节的内存空间。当 NameNode 维护的目录和文件总量达到1亿,数据块总量达到4亿后,常驻内存使用量将达到90GB!这将严重影响 HDFS 集群的扩展性。
任何一方面,单个 NameNode 提供读写访问请求,也会影响整个 HDFS 集群的吞吐量。同时,这种架构中所有租户共享一个命名空间(namespace),无法对不同的应用程序进行隔离。
HDFS Federation
为了解决 HDFS 的水平扩展性问题,社区从 Apache Hadoop 0.23.0 版本开始引入了 HDFS federation(参见 HDFS-1052)。HDFS Federation 是指 HDFS 集群可同时存在多个 NameNode/Namespace,每个 Namespace 之间是互相独立的;单独的一个 Namespace 里面包含多个 NameNode,其中一个是主,剩余的是备,这个和上面我们介绍的单 Namespace 里面的架构是一样的。这些 Namespace 共同管理整个集群的数据,每个 Namespace 只管理一部分数据,之间互不影响。
集群中的 DataNode 向所有的 NameNode 注册,并定期向这些 NameNode 发送心跳和块信息,同时 DataNode 也会执行 NameNode 发送过来的命令。集群中的 NameNodes 共享所有 DataNode 的存储资源。HDFS Federation 的架构如下图所示:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
通过 HDFS Federation 架构可解决单 NameNode 存在扩展性、业务隔离以及性能等问题。关于如何配置 HDFS Federation 可以参见这里。
ViewFs
这个版本的 HDFS Federation 虽然能够解决单 Namespace 带来的一些问题,但是又引来了新的问题。比如现在集群中存在多个 Namespace,每个 Namespace 管理一部分数据,那客户端如何知道要查询的数据在哪个 Namespace 上呢?为了解决这个问题,社区引入了视图文件系统(View File System,简称 ViewFs),具体可以参见 HADOOP-7257。ViewFs 类似于某些 Unix / Linux 系统中的客户端挂载表。ViewFs 可用于创建个性化命名空间视图,也可用于创建每个群集的公共视图。那 ViewFs 是如何解决文件映射到对应的 Namespace 上呢?
ViewFs 通过在 core-site.xml 文件里面引入了路径映射配置,如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>viewfs://clusterX</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./data</name>
<value>hdfs://nn1-clusterx.iteblog.com:8020/data</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./iteblog</name>
<value>hdfs://nn2-clusterx.iteblog.com:8020/iteblog</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./user</name>
<value>hdfs://nn3-clusterx.iteblog.com:8020/user</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://nn4-clusterx.iteblog.com:8020/tmp</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.linkFallback</name>
<value>hdfs://nn5-clusterx.iteblog.com:8020/home/iteblog</value>
</property>
</configuration>
正如上面的配置文件所示,在启用了 HDFS Federation 的集群,fs.defaultFS 的值已经变成了 viewfs://clusterX,这个和未启用 HDFS Federation 的集群是不一样的。然后紧接着配置了五个属性,用于指定文件和集群的映射关系。
比如用户访问了 /data 路径,那么通过这个配置文件,我们就知道直接到 hdfs://nn1-clusterx.iteblog.com:8020 集群的 /data 路径下拿数据;当用户访问 /iteblog,那么通过这个配置文件,我们就知道直接到 hdfs://nn2-clusterx.iteblog.com:8020 集群的 /iteblog 路径下拿数据。其他路径的数据获取和这个类似。如果访问的路径在配置文件里面没找到,那么将会访问 fs.viewfs.mounttable.ClusterX.linkFallback 属性配置的集群和路径进行访问。关于详细的 ViewFs 配置可以参见 官方文档
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Hadoop 的 HDFS Federation 前世今生(上)】(https://www.iteblog.com/archives/2572.html)







