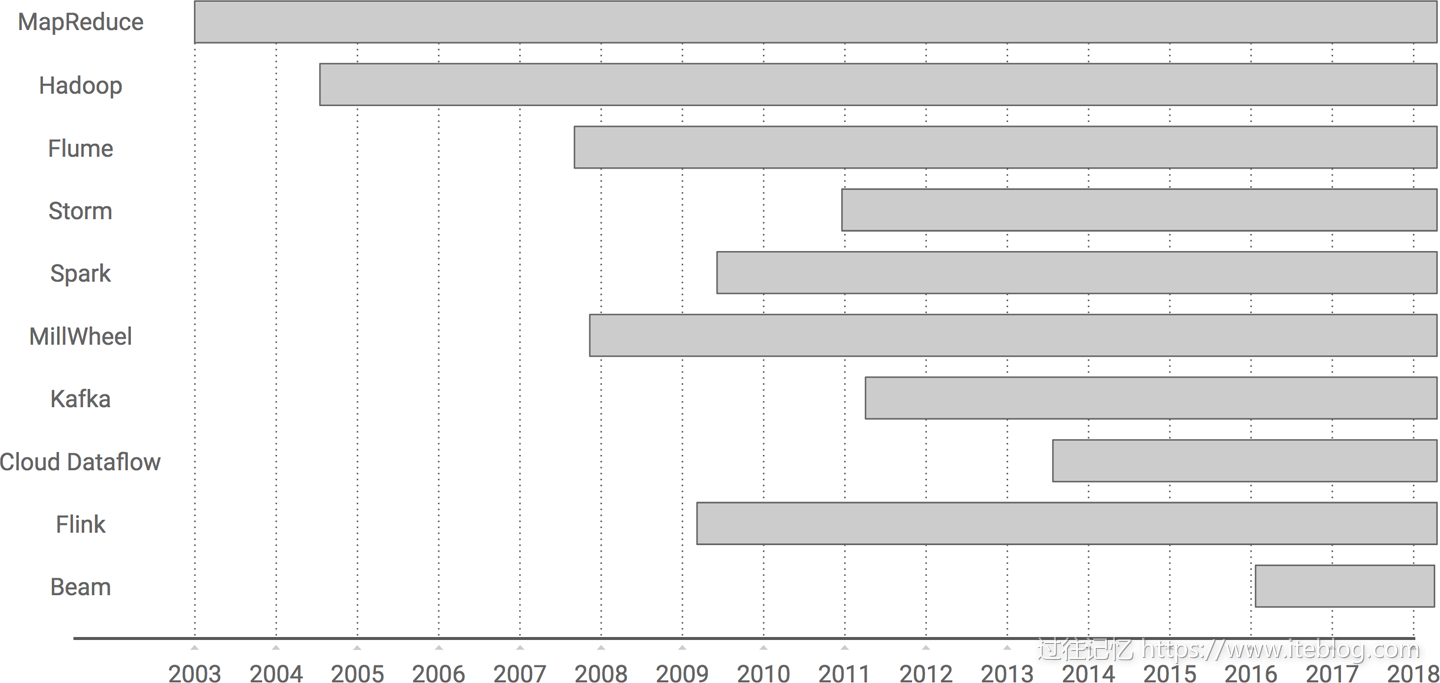
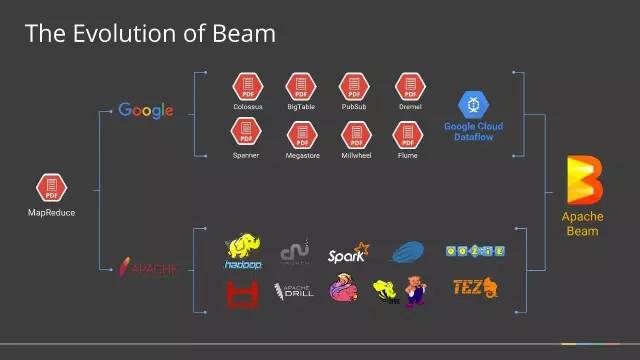
Apache软件基金会在2017年01月10正式宣布Apache Beam从孵化项目毕业,成为Apache的顶级项目。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的又一个非常大的贡献。Apache Beam的主要目标是统一批处理和流处理的编程范式,为无限,乱序,web-scale的数据集处理提供简单灵活,功能丰富以及表达能力十分强大的SDK。
Beam仅仅是一个SDK,是一个应用顶层的API,那么它下层支持的数据处理框架(官方叫做Apache Beam Pipeline Runners)主要包括Apache Apex,Apache Flink,Apache Spark以及它自己的Google Cloud Dataflow。
Apache Beam 的两大特点
1、将数据的批处理(batch)和流处理(stream)编程范式进行了统一;
2、能够在任何的执行引擎上运行。
它不仅为模型设计、更为执行一系列数据导向的工作流提供了统一的模型。这些工作流包括数据处理、吸收和整合。
为什么会诞生Apache Beam
大数据处理领域的一大问题是:开发者经常要用到很多不同的技术、框架、API、开发语言和 SDK。根据任务场景的不一样,开发者很可能会用 MapReduce 进行批处理,用 Apache Spark SQL 进行交互请求,用 Apache Flink 实时流处理。新的分布式处理框架可能带来的更高的性能,更强大的功能,更低的延迟等,但用户切换到新的分布式处理框架的代价也非常大:需要学习一个新的数据处理框架,并重写所有的业务逻辑。
解决这个问题的思路包括两个部分,首先,需要一个编程范式,能够统一,规范分布式数据处理的需求,例如,统一批处理和流处理的需求。其次,生成的分布式数据处理任务应该能够在各个分布式执行引擎上执行,用户可以自由切换分布式数据处理任务的执行引擎与执行环境。Apache Beam正是为了解决以上问题而提出的。
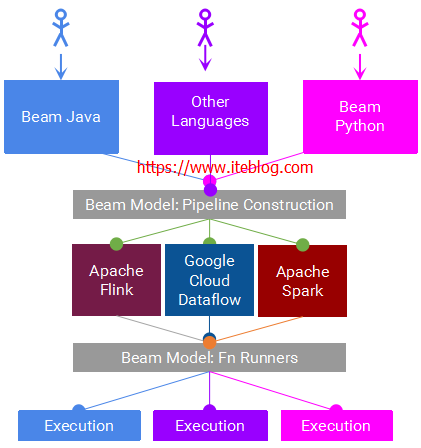
Apache Beam主要由Beam SDK和Beam Runner组成,Beam SDK定义了开发分布式数据处理任务业务逻辑的API接口,生成的的分布式数据处理任务Pipeline交给具体的Beam Runner执行引擎。Apache Beam目前支持的API接口是由Java语言实现的,Python版本的API正在开发之中。如下图所示:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
Apache Beam编程模型的核心是Watermarks, Windows 和 Triggers,它统一了批处理和流处理的编程范式,为无限,乱序,web-scale的数据集处理提供简单灵活,功能丰富以及表达能力十分强大的SDK。它实现了Tyler Akidau两篇经典的流式处理文章中描述的几乎所有特性,如果你没看过这两篇文章,建议仔细阅读下:
The world beyond batch: Streaming 101:https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
The world beyond batch: Streaming 102:https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102
Apache Beam是分布式计算引擎走向多样化后的必然结果,它的提出对于大家更好的设计新型的批处理和流式计算引擎有重要的借鉴意义。它的提出有一定的参考与实用价值,大家可关注该项目的进展,并尝试实用该项目。
因为笔者并没有实际使用Apache Beam的经验,所以深入的知识请参见Apache Beam的官方文档。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Beam成为Apache顶级项目】(https://www.iteblog.com/archives/1970.html)