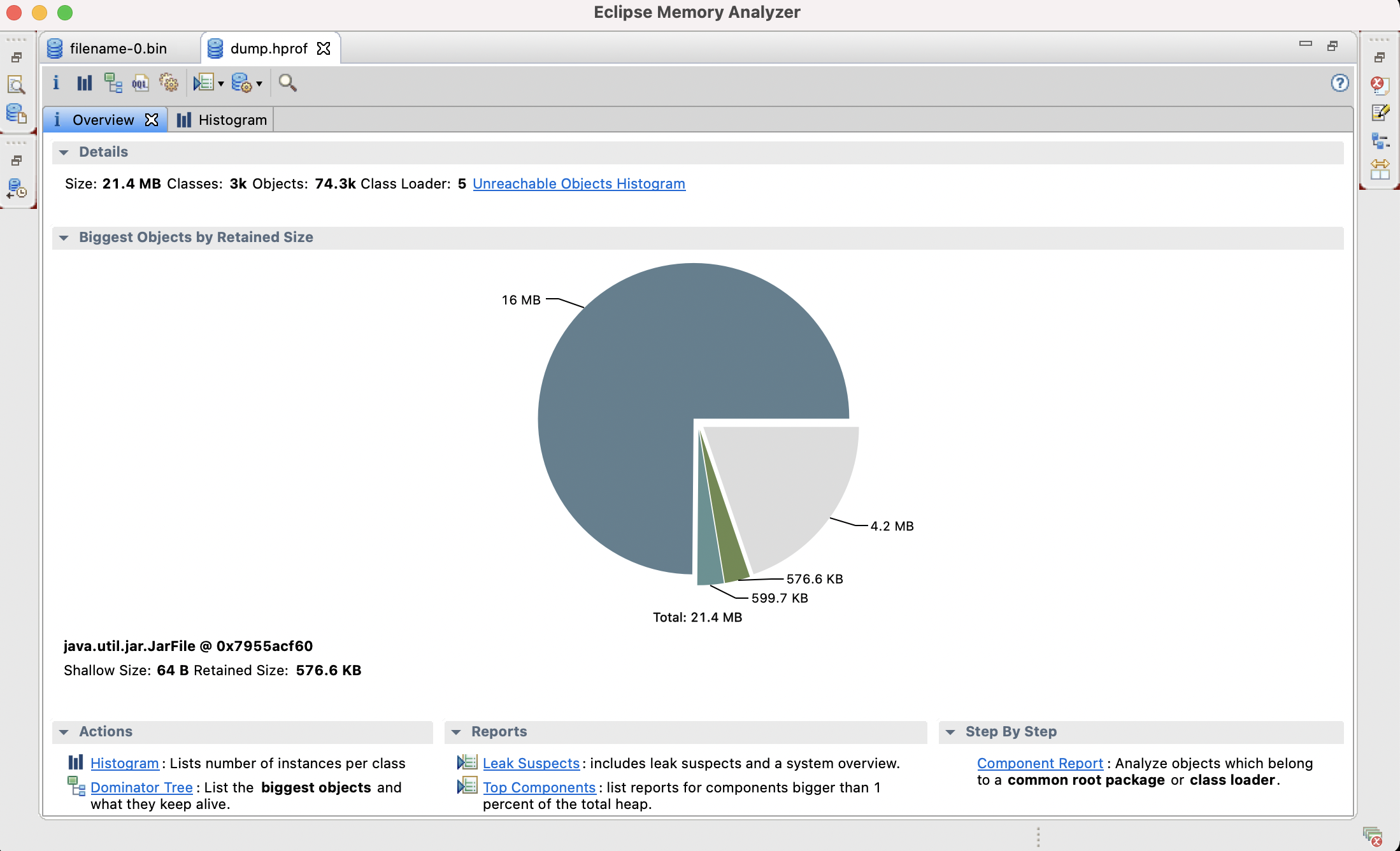
在Guava中新增了一个新的类型Range,从名字就可以了解到,这个是和区间有关的数据结构。从Google官方文档可以得到定义:Range定义了连续跨度的范围边界,这个连续跨度是一个可以比较的类型(Comparable type)。比如1到100之间的整型数据。不过我们无法遍历出这个区间里面的值。如果需要达到这个目的,我们可以将这个范围传给ContiguousSet.create(com.google.common.collect.Range, com.google.common.collect.DiscreteDomain).来达到遍历这个范围里面的值。
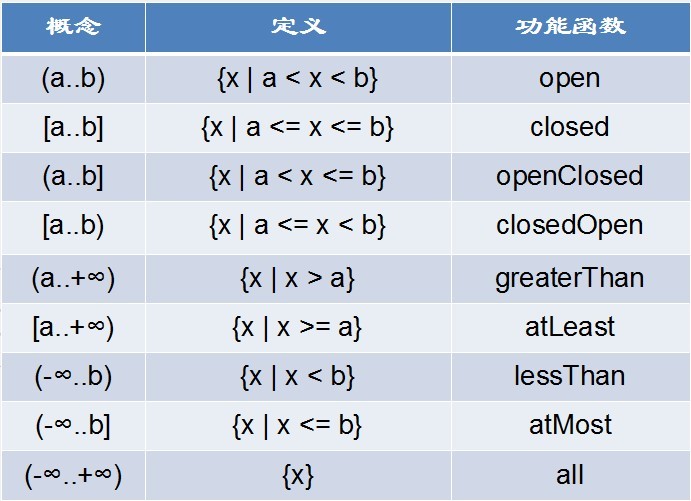
我们知道,在数学里面的范围是有边界和无边界之分的;同样,在Guava中也有这个说法。如果这个范围是有边界的,那么这个范围又可以分为包括开集(不包括端点)和闭集(包括端点);如果是无解的可以用+∞表示。如果枚举的话,一共有九种范围表示:
Guava Range
上表中的功能函数那一栏表示Range类提供的函数,分别来表示九种可能出现的范围区间。如果区间两边都存在范围,在这种情况下,区间右边的数不可能比区间左边的数小。在极端情况下,区间两边的数是相等的,但前提条件是最少有一个边界是闭集的,否则是不成立的。比如:
[a..a] : 里面只有一个数a; [a..a); (a..a] : 空的区间范围,但是是有效的; (a..a) : 这种情况是无效的,构造这样的Range将会抛出异常。
在使用Range时需要注意:
- 在构造区间时,尽量使用不可改变的类型。如果你需要使用可变的类型,在区间类型构造完成的情况下,请不要改变区间两边的数;
- 一个实现了Comparable接口的类传进Range将会发生未定义的情况;目前Range API还没有阻止这种用法,但是未来可能会改变。
更多有关Range的介绍,请关注Google官方文档(http://docs.guava-libraries.googlecode.com/git/javadoc/index.html)。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Guava学习之Range】(https://www.iteblog.com/archives/531.html)