本书将向您展示如何利用Python的强大功能并将其用于Spark生态系统中。您将首先了解Spark 2.0的架构以及如何为Spark设置Python环境。通过本书,你将会使用Python操作RDD、DataFrames、MLlib以及GraphFrames等;在本书结束时,您将对Spark Python API有了全局的了解,并且学习到如何使用它来构建数据密集型应用程序。通过本书你将学习到以下的知识 zz~~ 7年前 (2017-03-09) 10727℃ 0评论12喜欢
第十二次Shanghai Apache Spark Meetup聚会,由Splunk中国大力支持。活动将于2017年03月18日12:30~16:45在上海淞沪路303号901 (大学路智星路路口汇丰银行楼9楼)Splunk 中国进行。 举办地点交通方便,靠近地铁10号线江湾体育场站,座位有限(大约120),先到先得,速速行动啊。大会主题《利用Spark开发高并发,高可靠的分布式大数据采集调 w397090770 7年前 (2017-03-09) 1417℃ 0评论2喜欢
此次活动参与方式:关注iteblog_hadoop公众号,并在这里评论区留言(认真写评论,增加上榜的机会)。活动截止至3月14日19:00,留言点赞数排名前5名的粉丝,各免费赠送一本《Druid实时大数据分析原理与实践》如果想及时了解Spark、Hadoop、Flink或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书简介Druid 作为一 w397090770 7年前 (2017-03-08) 1582℃ 0评论5喜欢
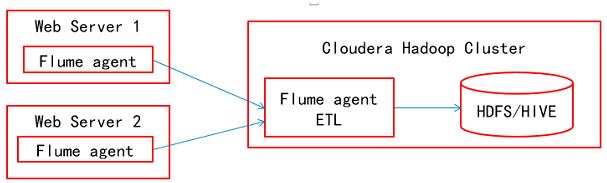
本文来自徐宇辉(微信号:xuyuhui263)的投稿,目前在中国移动从事数字营销的业务支撑工作,感谢他的文章。Apache Flume简介Apache Flume是一个Apache的开源项目,是一个分布的、可靠的软件系统,主要目的是从大量的分散的数据源中收集、汇聚以及迁移大规模的日志数据,最后存储到一个集中式的数据系统中。Apache Flume是由 zz~~ 7年前 (2017-03-08) 7178℃ 0评论17喜欢
本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitioner,使用Map侧Join代替Reduce侧Join,给倾斜Key加上随机前缀等。为何要处理数据倾斜(Data Skew)什么是数据倾斜对Spark/Hadoop这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。何谓数据倾 w397090770 7年前 (2017-03-07) 13227℃ 2评论27喜欢
在Flink中我们可以很容易的使用内置的API来读取HDFS上的压缩文件,内置支持的压缩格式包括.deflate,.gz, .gzip,.bz2以及.xz等。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是如果我们想使用Flink内置sink API将数据以压缩的格式写入到HDFS上,好像并没有找到有API直接支持(如果不是这样的, w397090770 7年前 (2017-03-02) 10143℃ 0评论5喜欢
假设现在的分支名称为 oldName,想要修改为 newName如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本地分支重命名这种情况是你的代码还没有推送到远程,分支只是在本地存在,那直接执行下面的命令即可:[code lang="bash"]git branch -m oldName newName[/code]远程分支重命名 如果你的分支已经推 w397090770 7年前 (2017-03-02) 675℃ 0评论1喜欢
一直运行的Spark Streaming程序如何关闭呢?是直接使用kill命令强制关闭吗?这种手段是可以达到关闭的目的,但是带来的后果就是可能会导致数据的丢失,因为这时候如果程序正在处理接收到的数据,但是由于接收到kill命令,那它只能停止整个程序,而那些正在处理或者还没有处理的数据可能就会被丢失。那我们咋办?这里有两 w397090770 7年前 (2017-03-01) 8827℃ 1评论11喜欢
大多数刚刚使用Apache Flink的人很可能在编译写好的程序时遇到如下的错误:[code lang="bash"]Error:(15, 26) could not find implicit value for evidence parameter of type org.apache.flink.api.common.typeinfo.TypeInformation[Int] socketStockStream.map(_.toInt).print() ^[/code]如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteb w397090770 7年前 (2017-03-01) 4061℃ 9喜欢

![[电子书]Learning PySpark PDF下载](https://www.iteblog.com/pic/books/Learning_PySpark_iteblog.jpg)