Protobuf (全称 Protocol Buffers)是 Google 开发的一种数据描述语言,能够将结构化数据序列化,可用于数据存储、通信协议等方面。在 HBase 里面用使用了 Protobuf 的类库,目前 Protobuf 最新版本是 3.6.1(参见这里),但是在目前最新的 HBase 3.0.0-SNAPSHOT 对 Protobuf 的依赖仍然是 2.5.0(参见 protobuf.version),但是这些版本的 Protobuf 是互补兼 w397090770 5年前 (2018-11-26) 5292℃ 0评论10喜欢
近几年来,人工智能逐渐火热起来,特别是和大数据一起结合使用。人工智能的主要场景又包括图像能力、语音能力、自然语言处理能力和用户画像能力等等。这些场景我们都需要处理海量的数据,处理完的数据一般都需要存储起来,这些数据的特点主要有如下几点:大:数据量越大,对我们后面建模越会有好处;稀疏:每行 w397090770 5年前 (2018-11-22) 3241℃ 1评论10喜欢
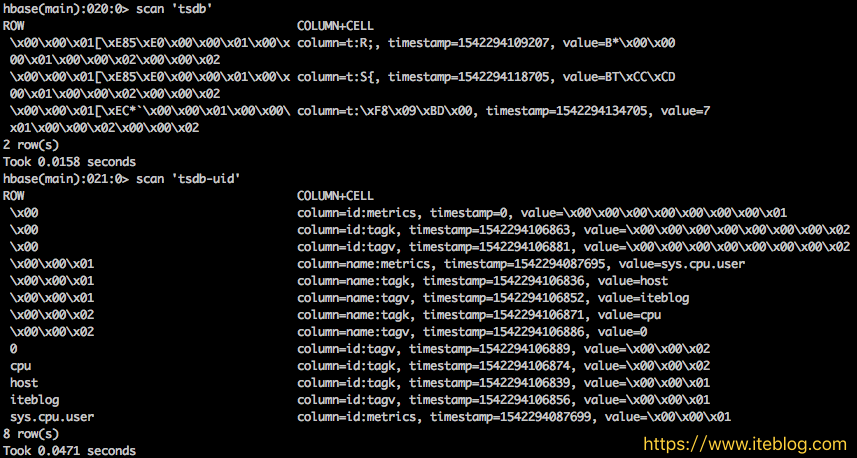
通过《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》 文章我们已经了解 OpenTSDB 底层的 HBase Rowkey 是如何设计的了。我们现在来测试一下 OpenTSDB 导入的时序数据到底长什么样子。在 OpenTSDB 里面默认存时序数据的表为 tsdb。前面说了,每个指标名称、标签名称以及标签值都有唯一的编码,这些编码数据是存放在 tsdb-uid 表里面。为了更加 w397090770 6年前 (2018-11-16) 2961℃ 3评论6喜欢
OpenTSDB 是基于 HBase 的可扩展、开源时间序列数据库(Time Series Database),可以用于存储监控数据、物联网传感器、金融K线等带有时间的数据。它的特点是能够提供最高毫秒级精度的时间序列数据存储,能够长久保存原始数据并且不失精度。它拥有很强的数据写入能力,支持大并发的数据写入,并且拥有可无限水平扩展的存储容量。目 w397090770 6年前 (2018-11-15) 5084℃ 1评论10喜欢
背景随着 Apache HBase 在各个领域的广泛应用,在 HBase 运维或应用的过程中我们可能会遇到这样的问题:同一个 HBase 集群使用的用户越来越多,不同用户之间的读写或者不同表的 compaction、region splits 操作可能对其他用户或表产生了影响。将所有业务的表都存放在一个集群的好处是可以很好的利用整个集群的资源,只需要一套运 w397090770 6年前 (2018-11-01) 6265℃ 4评论13喜欢
本文来自于2018年10月20日由中国 HBase 技术社区在武汉举办的中国 HBase Meetup 第六次线下交流会。分享者为过往记忆。本文 PPT 下载 请关注 iteblog_hadoop 微信公众号,并回复 HBase 获取。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop本次分享的内容主要分为以下五点:HBase基本知识;HBase读 w397090770 6年前 (2018-10-25) 6235℃ 0评论23喜欢
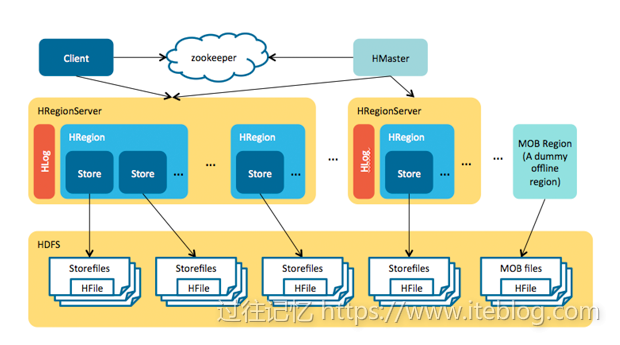
关于 HBase 的 MOB 具体使用可以参见 《HBase MOB(Medium Object)使用入门指南》介绍Apache HBase 中等对象存储(Medium Object Storage, 下面简称 MOB)的特性是由 HBASE-11339 引入的。该功能可以提高 HBase 对中等尺寸文件的低延迟读写访问(理想情况下,文件大小为 100K 到 10MB),这个功能使得 HBase 非常适合存储文档,图片和其他中等尺寸的对 w397090770 6年前 (2018-08-27) 2272℃ 0评论2喜欢
背景介绍本项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询。原实现基于 Oracle 提供存储查询服务,随着数据量的不断增加,在写入和读取过程中面临性能问题,且历史数据仅供业务查询参考,并不影响实际流程,从系统结构上来说,放在业务链条上游比较重。 w397090770 7年前 (2017-10-28) 2645℃ 0评论7喜欢
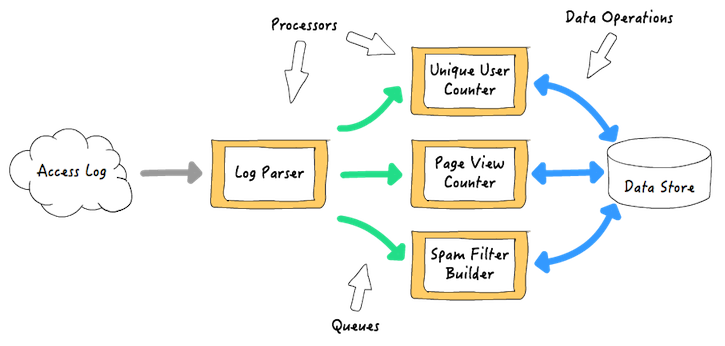
一个实时流处理框架通常需要两个基础架构:处理器和队列。处理器从队列中读取事件,执行用户的处理代码,如果要继续对结果进行处理,处理器还会把事件写到另外一个队列。队列由框架提供并管理。队列做为处理器之间的缓冲,传输数据和事件,这样处理器可以单独操作和扩展。例如,一个web 服务访问日志处理应用,可能是 w397090770 7年前 (2017-07-12) 563℃ 0评论0喜欢
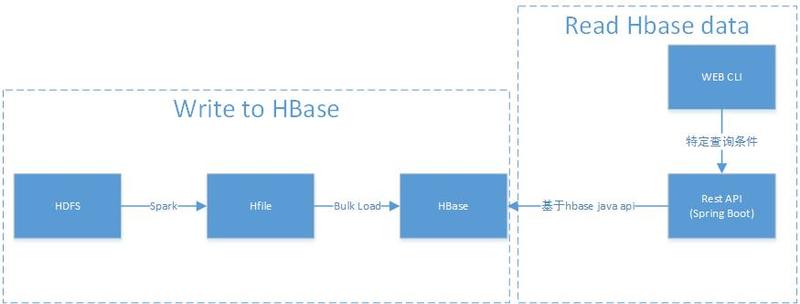
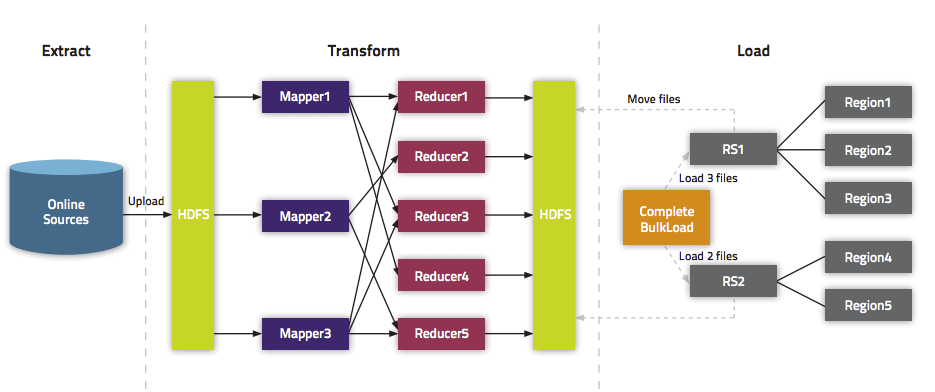
我们在《通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]》文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入数据到Hbase中的方法。这里将介绍两种方式:第一种使用Put普通的方法来倒数;第二种使用Bulk Load API。关于为啥需要使用Bulk Load本文就不介绍,更多的请参见《通过BulkLoad快 w397090770 7年前 (2017-02-28) 14980℃ 1评论40喜欢