本文是《Apache Hudi 入门教程》专题的第 7 篇,共 12 篇:
- Apache Hudi 0.8.0 版本发布,Flink 集成有重大提升以及支持并行写
- Apache Hudi 0.6.0 版本发布,新功能介绍
- Uber 大数据平台的演进(2014~2019)
- Delta Lake 和 Apache Hudi 两种数据湖产品全方面对比
- Apache Hudi: Uber 开源的大数据增量处理框架
- Uber 向 Apache 软件基金会提交开源大数据存储库 Hudi
- 恭喜,Apache Hudi 即将成为顶级项目
- 官宣,Apache Hudi 正式成为 Apache 顶级项目
- 还在玩数据仓库?现在已经是 LakeHouse 时代!
- Apache Hudi 常见问题汇总
- Apache Hudi 现在也支持 Flink 引擎了
- 盘点2019年晋升为Apache TLP的大数据相关项目
美国当地时间2020年05月11日,Apache Hudi 项目的共同创始人、PMC Vinoth Chandar 给社区发了一封标题为 [DISCUSS] Graduate Apache Hudi (Incubating) as a TLP 的邮件,来投票讨论 Apache Hudi 毕业成为 Apache TLP 项目。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
2020年05月19日共40人投票赞成 。不久社区给 Apache 董事会申请成为 TLP,今天(2020年05月23日)凌晨结果终于出来了,Vinoth Chandar 大佬给社区发了邮件说Apache 董事会同意 Apache Hudi 成为顶级项目提议。接下来,Apache Hudi 社区会准备进入 TLP 的一些事情。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Apache Hudi(Hoodie) 是 Uber 为了解决大数据生态系统中需要插入更新及增量消费原语的摄取管道和 ETL 管道的低效问题,该项目在2016年开始开发,并于2017年开源,2019年1月进入 Apache 孵化器。
Hudi (Hadoop Upsert Delete and Incremental) 是一种分析和扫描优化的数据存储抽象,可在几分钟之内将变更应用于 HDFS 中的数据集中,并支持多个增量处理系统处理数据。通过自定义的 InputFormat 与当前 Hadoop 生态系统(包括 Apache Hive、Apache Parquet、Presto 和 Apache Spark)集成,使得该框架对最终用户来说是无缝的。
Hudi 的设计目标就是为了快速增量更新 HDFS 上的数据集,它提供了两种更新数据的方式:Copy On Write 和 Merge On Read。Copy On Write 模式就是我们更新数据的时候需要通过索引获取更新的数据所涉及的文件,然后把这些数据读出来和更新的数据进行合并,这种模式更新数据比较简单,但是当更新涉及到的数据比较大时,效率非常低;而 Merge On Read 就是将更新写到单独的新文件里面,然后我们可以选择同步或异步将更新的数据和原来的数据进行合并(可以称为 combination),因为更新的时候只写新的文件,所以这种模式更新的速度会比较快。
有了 Hudi 之后,我们可以实时采集 MySQL、HBase、Cassandra 里面的增量数据然后写到 Hudi 中,然后 Presto、Spark、Hive 可以很快地读取到这些增量更新的数据,如下:
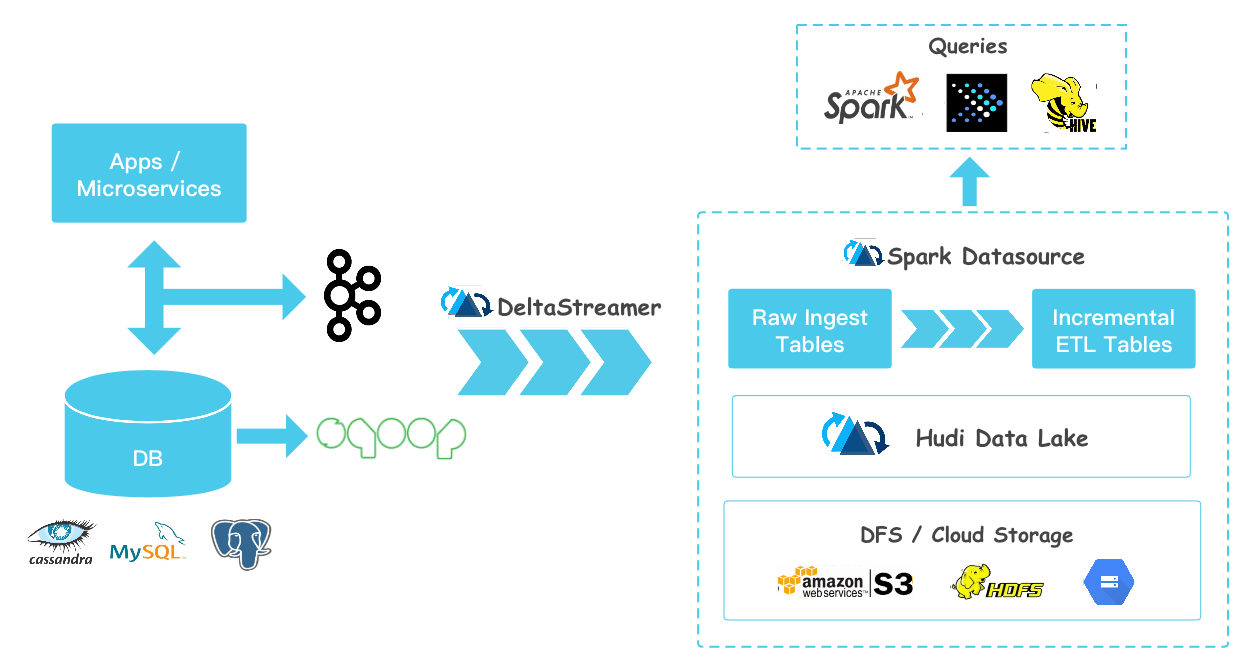
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
更多关于 Apache Hudi 的介绍可以参见过往记忆大数据的 《Apache Hudi: Uber 开源的大数据增量处理框架》 以及 《Uber 大数据平台的演进(2014~2019)》的介绍,以及 Apache Hudi 的官方文档:http://hudi.apache.org/
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【恭喜,Apache Hudi 即将成为顶级项目】(https://www.iteblog.com/archives/9811.html)