Apache Hudi 是一种数据湖平台技术,它提供了构建和管理数据湖所需的几个功能。hudi 提供的一个关键特性是自我管理文件大小,这样用户就不需要担心手动维护表。拥有大量的小文件将使计算更难获得良好的查询性能,因为查询引擎不得不多次打开/读取/关闭文件以执行查询。但是对于流数据湖用例来说,可能每次都只会写入很少的数据,如果不进行特殊处理,这可能会导致大量小文件。
写期间和写后
常见解决小文件的方法是写的时候就产生了大量小文件,事后再把这些文件合并到一起可以解决小文件带来的系统可扩展性问题;但是可能会影响查询的 SLA,因为我们把很多小文件暴露给它们。实际上,我们可以利用 Hudi 的 clustering 操作很轻松的实现小文件合并,关于 Hudi 的 clustering 可以参见这里。
本文,我们讨论了在初始写入时,Hudi 中的文件大小优化,这样我们就不需要为了维护文件的大小而再次重写所有数据。如果你想同时拥有自管理文件大小和避免将小文件暴露查询,自动文件大小功能(automatic file sizing feature)正是你需要的。
当执行 inserts/upsert 操作时,Hudi 有能力维护配置的目标文件大小。注意:bulk_insert 操作不提供这个功能,它只是被设计为替代 spark.write.parquet 的更简单方法。
配置
为了便于说明,本文只考虑 COPY_ON_WRITE 表的小文件自动合并功能。在阅读下文之前,我们先来看看几个相关的参数:
- hoodie.parquet.max.file.size:数据文件的最大大小。 Hudi 会尝试将文件大小保持在此配置值;
- hoodie.parquet.small.file.limit:文件大小小于这个配置值的均视为小文件;
- hoodie.copyonwrite.insert.split.size:单分区插入的数据条数,这个值应该和单个文件的记录条数相同。可以根据 hoodie.parquet.max.file.size 和单条记录的大小进行调整。
例如,如果你的第一个配置值是120MB,第二个配置值是100MB,那么任何小于100MB的文件都被认为是小文件。如果你想关闭自动文件大小功能,可以将 hoodie.parquet.small.file.limit 设置为0。
示例
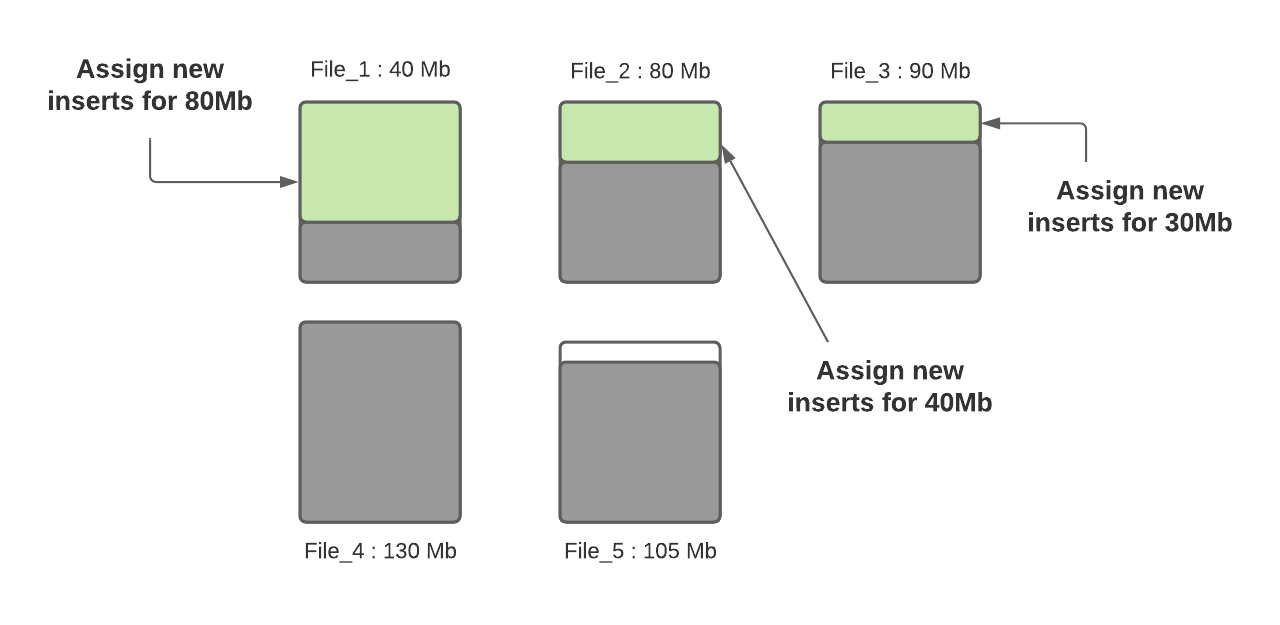
假设下面是给定分区的数据文件布局。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
假设最大文件大小和小文件大小限制的配置值分别是 120MB 和 100MB。File_1 的当前大小是 40MB, File_2 的大小是 80MB, File_3 的大小是 90MB, File_4 的大小是 130MB, File_5 的大小是 105MB,让我们看看当一个新的写入发生时会发生什么。
步骤1:将更新应用到文件。在这个步骤中,我们查找索引以找到标记的位置,并将记录分配给相应的文件。注意,我们假设更新只会增加文件大小,而这只会导致一个更大的文件。当更新降低了文件大小(比如,清空了很多字段),那么后续的写入将认为它是一个小文件。
步骤2:确定每个分区路径下面的小文件。这里将利用 hoodie.parquet.small.file.limit 配置值来确定小文件。在我们的示例中,给定配置值为100MB,那么小文件分别是 File_1(40MB)、File_2(80MB) 和 file_3 (90MB)。
第 3 步:一旦确定了小文件,就会将传入的插入分配给它们,以便它们达到 120MB 的最大容量。 File_1 将包含 80MB 的插入内容,file_2 将包含 40MB 的插入内容,File_3 将包含 30MB 的插入内容。
步骤3:一旦确定了小文件,就会将需要插入的数据分配给它们,使它们达到 120MB 的最大容量。所以 File_1 将插入 80MB 的数据;file_2 将插入 40MB 的数据;File_3 将插入 30MB 的数据.
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
步骤4:一旦所有小文件写到最大容量,并且如果还有未分配的插入,就会创建新的文件组/数据文件,并把剩下的数据写到这些新创建的文件组/数据文件中。每个新数据文件的记录数量由 hoodie.copyonwrite.insert.split.size 配置确定。假设 hoodie.copyonwrite.insert.split.size 配置为120k,如果有剩余 300k 条记录,那么将创建3个新文件,其中2个(File_6 和 File_7)将填充 120k 条记录,最后一个(File_8)将填充 60k 条记录(假设每条记录为 1000 字节)。在未来的摄取中,第三个新文件(File_8)将被视为是一个小文件,用于存储更多的数据。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
Hudi 利用自定义分区等机制来优化记录分发到不同的文件,执行上述算法。在这一轮摄取完成后,除 File_8 之外的所有文件都被很好地调整到最佳大小。 在每次摄取期间都遵循此过程,以确保 Hudi 表中没有小文件。
本文翻译自:How Apache Hudi maintains optimum sized files
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Hudi 是如何处理小文件的】(https://www.iteblog.com/archives/9988.html)